

StatsDirect(数据分析软件)
v3.2.10 免费版- 软件大小:52.6 MB
- 更新日期:2020-05-14 18:04
- 软件语言:简体中文
- 软件类别:办公专区
- 软件授权:免费版
- 软件官网:待审核
- 适用平台:WinXP, Win7, Win8, Win10, WinAll
- 软件厂商:

软件介绍 人气软件 下载地址
StatsDirectd是一款功能强大的数据分析软件,该程序提供了描述性统计、置信区间、参数化方法、非参数方法、回归与相关、方差分析、协议分析、荟萃分析、生存分析、分布函数、卡方列联表、精确的计数测试、比例、样本量估算、随机化等多种不同的分析方式,能够帮助用户处理各类数据,而且支持生成多种类型的图表,并允许通过Excel快速导入导出数据,从而极大的提升工作效率,这里为您分享了StatsDirectd的本,有需要的朋友赶紧下载吧!
软件功能
StatsDirect是一个全面的应用程序,可让您收集,浏览和分析大量数据以发现模式和潜在趋势。
以表格形式查看数据,进行编辑,进行分析并以最小的努力生成各种图形
读取和写入Microsoft Excel文件(2013/2010/2007或97-2003)。
Windows图元文件可缩放图形(可以在Word中编辑组件)。
软件内置的统计指南。
虚拟/设计/指标变量生成。
时间序列摘要,其中时间曲线下的面积用于药代动力学。
散点图,折线图和误差线图。
软件特色
干净清晰的界面
必须提及的是,当您首次启动该实用程序时,系统会提示您使用用户,电子邮件或密码登录。否则,安装将快速,流畅,并且您无需在使用前配置该应用程序。
该界面借用了Microsoft Excel的外观,这意味着它由几个数据表组成,您可以在其中预览或添加数据。尽管它包括您可以执行的大量工具和分析功能,但所有这些功能在工具栏和直观菜单中都井井有条。
就图形而言,该程序允许进行一些自定义,这意味着您可以更改每个图形的标题,颜色,标记,大小以及轴表示的线宽。虽然图形表示不是交互式的,但事实是它适合于应用程序的角色。
使您能够执行广泛的数据分析
从计算置信区间干扰到进行卡方检验,该应用程序的优势在于可以进行大量的统计分析。
类似的线性回归,比值比的Gart置信区间和单身和成双的Student T检验是可以用来检验心理工具(例如问卷)或当前研究假设的有效性和逼真度的一些功能。尽管它确实为您提供了必要的数据,但是您仍然需要自己进行解释。
附带说明一下,StatsDirect允许您加载和预览XLS文件,如果您没有安装Microsoft Office Pack,此功能肯定会派上用场。此外,您可以将项目另存为XLS,还可以导入或导出CSV,TXT和TAB文件格式。
进行统计分析的绝佳工具
StatsDirect具有描述性统计数据特有的众多功能,对于仅学习高级数据分析和解释的学生以及每天需要管理大量数据的专业人士而言,StatsDirect可以非常有用。
软件优势
易于使用
统计指南可帮助您根据结果编写科学报告。
智能界面可帮助您了解和学习统计信息。
技术先进
最新的方法和算法,例如精确的置信区间。
随着我们方法的发展,更新会添加新功能。
全面
广泛涵盖具有深层生物医学和公共卫生重点的方法。
用于许多领域,包括社会科学,市场研究和教学统计。
安装方法
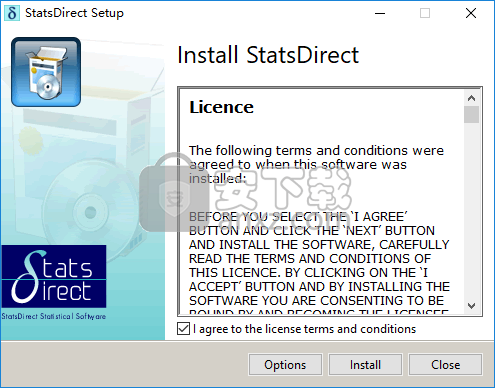
1、双击StatsDirect安装程序进入如下的许可协议界面,勾选【I agree to the license terms and conditions】的选项,然后进入下一步的安装。
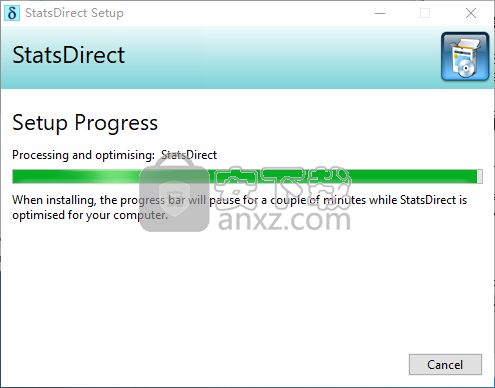
2、正在安装StatsDirect,用户等待安装完成。
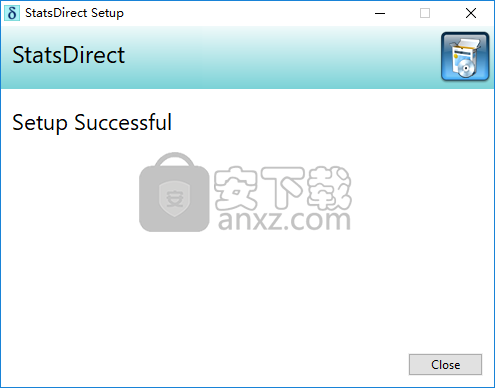
3、弹出如下的安装成功的提示,点击【close】结束。
4、将补丁文件“statsdirect.v.3.2.10-patch.exe”复制到软件安装目录,默认路径为C:\Program Files\StatsDirect3。
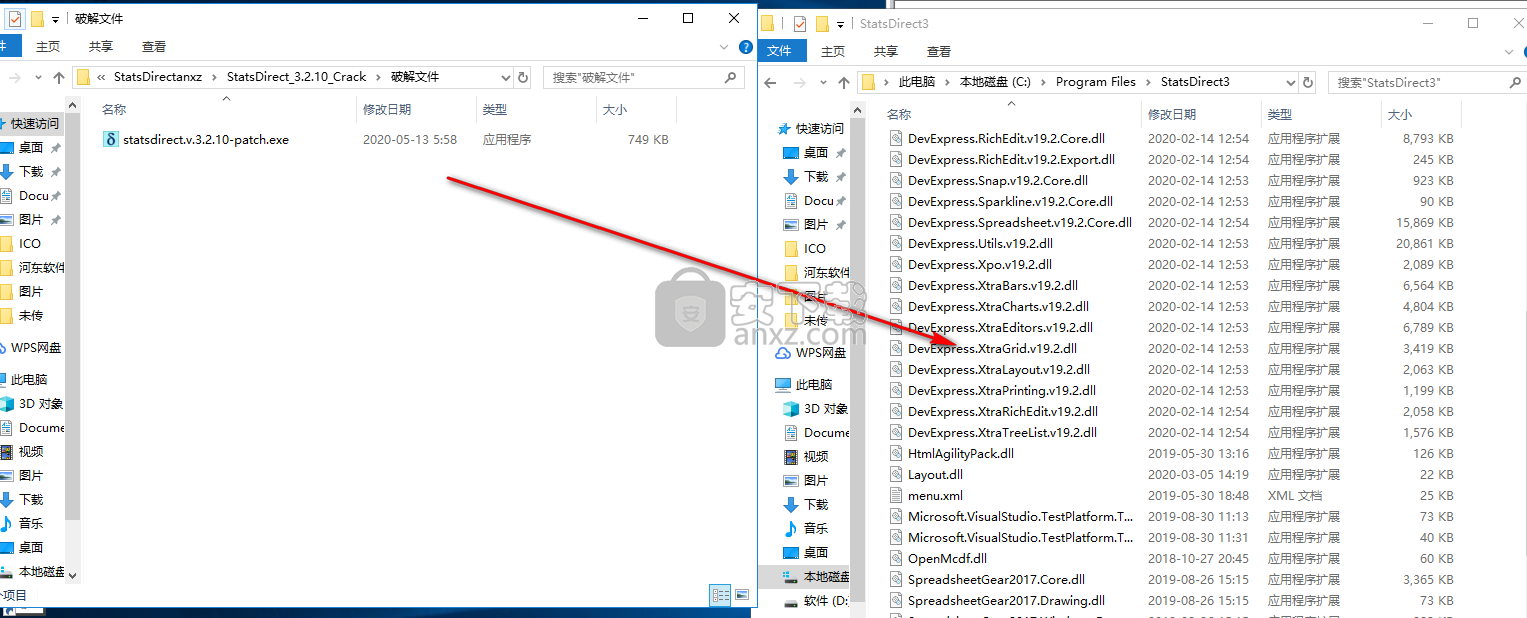
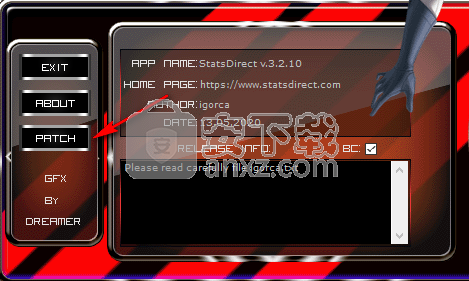
5、在安装目录下运行补丁程序,点击【patch】按钮进行打补丁操作。
6、以管理员身份运行“1.bat”。
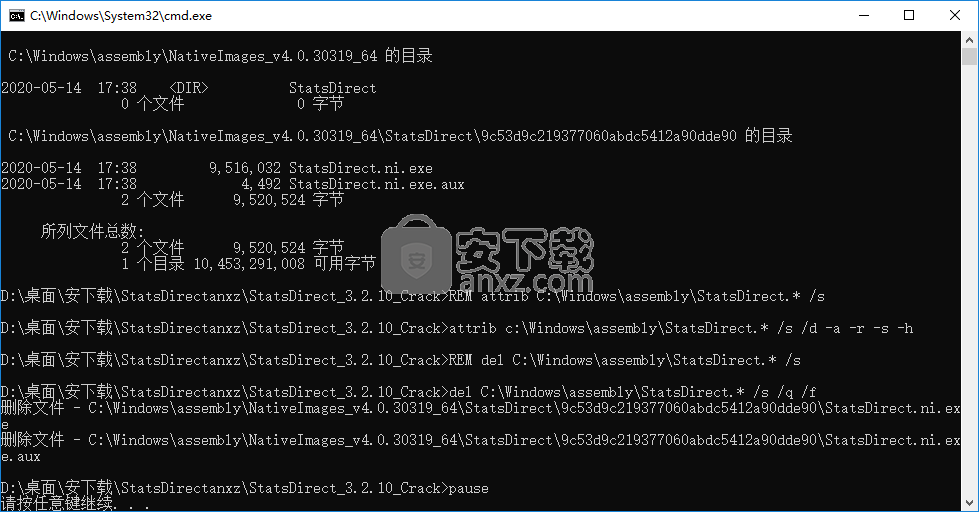
7、随即弹出如下的界面,然后按任意键完成。
8、运行StatsDirect,即可开始进行使用。
使用说明
摘要数据荟萃分析
当从一组相关研究中仅获悉汇总统计信息(几率,相对,风险差-带有置信区间或标准误差)时,此功能可替代适当的荟萃分析。
如果有原始研究的原始数据,请不要使用此功能,因为使用原始原始数据时,合并的估算值将更加精确。此功能的更好替代方案是基于所纳入研究的计数的比值比,相对风险或风险差异荟萃分析。
针对固定效应模型和随机效应模型计算了广义的荟萃分析。层权重被计算为所提供的摘要统计量(Y)的方差的倒数。如果将Y指定为比率,则对Y的自然对数转换执行计算。Y的合并估计值将作为加权平均值计算,即每个层的加权Y或ln(Y)的总和除以Y的总和。权重,如有必要,可以转换回自然比例。
I²统计数据汇总了各个研究结果之间的不一致,该统计数据是由于异质性而不是偶然性导致的各个研究变异的百分比。
荟萃分析中的异质性
荟萃分析中的异质性是指研究之间研究结果的差异。 StatsDirect调用统计数据,以测量荟萃分析“非组合性”统计数据中的杂合度,以帮助用户解释结果。
衡量研究结果的不一致
异质性的经典度量是Cochran's Q,它是根据各个研究结果与各个研究合并结果之间的平方差的加权和来计算的,权重是在合并方法中使用的。 Q分布为k(学习数)减去1自由度的卡方统计量。作为异质性的综合测试,Q的功效较低(Gavaghan等,2000),尤其是在研究数量较少(即大多数荟萃分析)的情况下。相反,如果研究数量很多,则Q具有太多的异质性检验功能(Higgins等人,2003):Q被包含在每个StatsDirect元分析函数中,因为它构成了DerSimonian-Laird随机效应合并方法的一部分。 DerSimonian和Laird(1985年)。由于Breslow和Day(1980)而进行的另一项测试提供了比值比值荟萃分析。通过仅考虑研究的汇总数据,可能无法检验所有研究正在评估相同效果的原假设:在系统评价中,应将异质性测试结果与研究可组合性的定性评估一起考虑。
I²统计量描述了由于异质性而不是偶然性导致的研究变异百分数(Higgins和Thompson,2002; Higgins等,2003)。 I²= 100%x(Q-df)/ Q。 I²是研究结果不一致的直观直观表达。与Q不同,它并不固有地取决于所考虑的研究数量。使用以下方法构造I²的置信区间:i)Hedges and Piggott(2001)的迭代非中心卡方分布方法; ii)Higgins和Thompson(2002)的基于测试的方法。当前,非中心卡方方法是首选方法(Higgins,个人交流,2006年)–如果选择了“精确”选项,则会进行计算。
L'Abbé图可用于从视觉上探索研究的不一致之处。
在固定效应模型和随机效应模型之间进行选择
如果两次试验之间的差异很小,则I²会很低,因此固定效应模型可能比较合适。具有固定的效果,您试图总体上检查的所有研究都被认为是在相似的条件下对相似的主题进行的–换句话说,研究之间的唯一区别是它们检测感兴趣结果的能力。另一种方法是“随机效应”,它可以使研究结果以研究之间的正态分布变化。许多研究者认为随机效应方法比固定效应是更自然的选择,例如在医疗决策环境中(Fleiss和Gross,1991; DerSimonian和Laird,1985; Ades和Higgins,2005)。
要获得与固定效应模型相同的统计功效,随机效应模型需要更多数据,并且在假设随机效应时,没有“精确”的方法来处理少量的研究。对于大多数荟萃分析来说,这应该不是问题,但是,在没有专家统计指导的情况下,请勿将稀疏数据集用于随机效应模型。
随机效应不能解决将荟萃分析的结果推广到现实世界中的困难。可以通过其他分析来探索可概括性,这些分析除了要审查的研究的内在不确定性外,还要结合特定的预测不确定性(Ades和Higgins,2005年)。
Logit转换
Logit是使比例的S形分布线性化的常见转换(Armitage和Berry,1994)。对数定义为自然对数ln(p / 1-p),其中p是比例。例如,被对数杀虫剂杀死的昆虫数量可能描述了乙状关系,即与非对数转化剂量呈矩形双曲线关系。在logit变换之后,这种量化响应情况通常被视为线性问题。逻辑回归使用这些原理。
您可以提供比例或离散数据进行logit转换。如果指定离散数据,则StatsDirect会将每个值作为所提供数据最大值的一部分,将其转换为比例。结果存储在标记为Logit:的新列中,其中是原始列标签。
StatsDirect将不确定的值标记为缺失数据,即p = 0或p = 1。另一方面,StatsDirect逻辑回归为这种情况提供了更复杂的处理,其中p = 0或p = 1有助于整体回归。
对数的另一个定义是0.5 * ln(p / 1-p),这只会使数值在数值上更接近概率。
Logits的一个吸引人的特征是对Logistic回归的普及,这是两个Logit之间的差异可以看作是优势比。当比较拟合的逻辑回归线上的点时,会出现这种情况。
概率转换
Probit是使比例的S型分布线性化的常见转换(Armitage and Berry,1994)。概率定义为标准正态分布的5 + 1-p分位数,其中p是比例。例如,被对数杀虫剂杀死的昆虫数量可能描述了乙状关系,即与非对数转化剂量呈矩形双曲线关系。这种量化响应情况可以在概率变换后视为线性问题。概率分析使用这些原理。
您可以提供比例或离散数据进行logit转换。如果指定离散数据,则StatsDirect会将每个值作为所提供数据最大值的一部分,将其转换为比例。结果存储在标记为Probit:的新列中,其中是原始列标签。
StatsDirect将不确定的值标记为缺失数据,即p = 0或p = 1。另一方面,StatsDirect概率分析以更复杂的方式处理p = 0和p = 1,将它们包括在整体分析中。
方差分析中的多重比较
StatsDirect提供用于多重比较(同时推理)的功能,特别是所有成对比较以及与控件的所有比较。对于k个组,有k(k-1)/ 2个可能的成对比较。
所有成对比较都提供了Tukey(Tukey-Kramer,如果组大小不相等),Scheffé,Bonferroni和Newman-Keuls方法(Armitage和Berry,1994; Wallenstein,1980; Miller,1981; Hsu,1996; Kleinbaum等人,1998)。 )。 Dunnett的方法用于与对照组进行多次比较(Hsu,1996)。
对于k个组,可以使用ANOVA查找整个k个组平均值之间的差异。如果在k均值之间存在统计学上的显着差异,则可以使用多重比较方法来寻找成对的组之间的特定差异。不应将两个样本方法用于进行成对比较的原因是,它们不是为以“数据挖掘”方式进行重复测试而设计的。
如果进行了20次重复的成对测试,那么您将不能接受传统的十分之一的错误机会作为统计推断的临界水平,即存在更高的I型错误风险。解决此问题的一种简单方法是,通过增加对比度数量来减少具有统计意义的临界值; Bonferroni的方法通过多个t检验来做到这一点。更复杂的方法,例如Tukey(-Kramer),考虑了与系统重复测试相关的统计分布; Tukey(-Kramer)和Newman-Keuls方法均基于Studentized范围统计量。 Scheffé的方法针对I型错误的风险进行了非常保守/谨慎的加权,因此对于检测真实差异的功能较弱。所有成对比较中最可接受的通用方法是Tukey(-Kramer),其P值在平衡设计下是精确的(Hsu,1996)。
基于针对每个对比比较的两组平均值之间差的绝对值,将不同的多种对比方法的输出以降序显示。第一个非有效P值旁边会显示“停止”一词,这表示如果您同时进行分析(类似于Shaffer-Holm方法),则不应考虑进一步的对比。
人气软件
-

microsoft office2021中文 3052 MB
/简体中文 -

microsoft project 2019中文 3584 MB
/简体中文 -

acrobat pro dc 2021 867 MB
/简体中文 -

福昕高级PDF编辑器 480 MB
/简体中文 -

Mindjet MindManager 2020激活码 0 MB
/简体中文 -

foxit pdf editor(福昕pdf编辑器) 4.6 MB
/简体中文 -

office tab14.0 56.1 MB
/简体中文 -

Tableau Desktop Professional Edition(专业数据分析软件) 431.0 MB
/简体中文 -

福昕pdf编辑器10.0 686 MB
/简体中文 -

XMind ZEN(思维导图软件) 131.0 MB
/简体中文
 钉钉电脑版 7.6.15
钉钉电脑版 7.6.15  华为welink电脑版 7.44.5.541
华为welink电脑版 7.44.5.541  网络编辑超级工具箱 1.0.3.0
网络编辑超级工具箱 1.0.3.0 









