
schrodinger suite 2016(药物分析与设计工具)
附带安装教程- 软件大小:13988 MB
- 更新日期:2020-04-06 15:21
- 软件语言:简体中文
- 软件类别:辅助设计
- 软件授权:免费版
- 软件官网:待审核
- 适用平台:WinXP, Win7, Win8, Win10, WinAll
- 软件厂商:

软件介绍 人气软件 下载地址
schrodinger 2016-4是一款非常强大的药物结构设计与分析软件;新版本更新了Maestro图形界面,使用标签将轨迹查看器的速度提高约3倍,轨迹回放速度提高约2倍,提供多序列查看器,带有现代化外观的重新设计界面,相关功能归为一组,使工作更轻松,添加了新功能,并保留了先前的多序列查看器中的重要功能,具有用于执行同源性建模的完整工作流程,包括紧密相关变体的批量同源性建模,轻松计算数十个序列描述符,并基于描述符值对序列进行排序,支持创建对齐方式集并执行轮廓对齐,性能针对大约500个序列进行了优化,多聚体蛋白的序列可以以分开或组合链模式查看;重写的驱动程序在站点识别和单个站点分析中的速度快,除相对结合自由能外,还同时存在相对溶剂化自由能,以便更好地解释自由能结果,可用性和布局改进,相对溶剂化能量结果和轨迹访问,显示未签名的错误,在FEP SID报告中访问副本交换图,在FEP+面板中轻松控制自定义FF参数文件,使用FEP+面板在PT中同步预测的自由能;需要的用户可以下载体验
新版功能
具有KNIME工作流程的SchrödingerSuites 2016-2
小分子药物发现套件。从QSAR到虚拟筛选再到结合亲和力预测,全面的小分子药物。Discovery Suite包含所有基于片段,配体和基于结构的药物设计所需的所有工具,以进行潜在顾客发现和优化。
生物制剂套装
这个易于使用的新套件是从头开始设计的,是对建模生物制剂,抗体和蛋白质非常重要的所有工具的第一个完整集合。
材料科学套件
这套创新的新套件为基于量子力学的化学系统模拟提供了功能强大的多功能工具,可在特种化学和材料科学中应用对系统进行分析和优化。
Discovery Informatics Suite
用于协作药物设计的下一代平台使包括医学化学家,生物学家建模人员和IT专业人员在内的多学科团队实时共享,查看和管理数据。
PyMOL
PyMOL是一个在开源基础上由用户赞助的分子可视化系统。请通过购买维护和/或支持订阅来支持这种开放,有效且价格合理的软件的开发。
SchrödingerSuites 2016-2
研发用于药物和生物技术研究的最新化学模拟软件的科学领导者SchrödingerLLC宣布推出Schrödinger软件2016-2。在此版本中,您将有机会对Maestro 11进行Beta测试并提供反馈。该季度发行版还包括所有软件的可用性改进和性能增强。
Schrödinger是高度模块化的程序套件,可用于各种模拟,设计,可视化,对接,建模和生物/化学信息学目的。多个发行版侧重于药物设计,材料科学,生物系统以及数据处理和可视化,为程序和集成环境之间的自定义工作流提供了预处理和后处理,界面,分析和优化的工具。
软件特色
Schrödinger提供致力于解决药物研究中挑战的完整软件套件。
对于以结构为基础的药物设计,Prime是一种精确的蛋白质结构预测模型;
Glide执行准确,迅速的配体-受体对接;联络预测结合与亲和力; QSite利用研究蛋白质活性区域内部的反应机制;
Schrödinger还提供了阶段,用于基于配体的药效建模,QikProp用于药物的ADME性状预测。
另外,LigPrep是一种用作深度计算机分析配体库准备的快速2D至3D转换程序。
最近,薛定谔还引入CombiGlide用于焦点库设计,引入EPIK对生物环境中的配体质子化状态做精确枚举。
此外,薛定谔还提供利用计算美洲虎,高级初始量子力学组件,MacroModel,分子模拟领域最受信赖的名字,已经广泛地被从物质到生命科学等全面的化学研究中。
组织性能关系的化学方法统计程序包。所有Schrödinger计算机程序的用户界面,提供提供强大,充分集成的分子的显现和分析环境。
安装步骤
1、用户可以点击本网站提供的下载路径下载得到对应的程序安装包

2、只需要使用解压功能将压缩包打开,双击主程序即可进行安装,弹出程序安装界面
3、可以根据自己的需要点击浏览按钮将应用程序的安装路径进行更改
4、弹出以下界面,用户可以直接使用鼠标点击下一步按钮
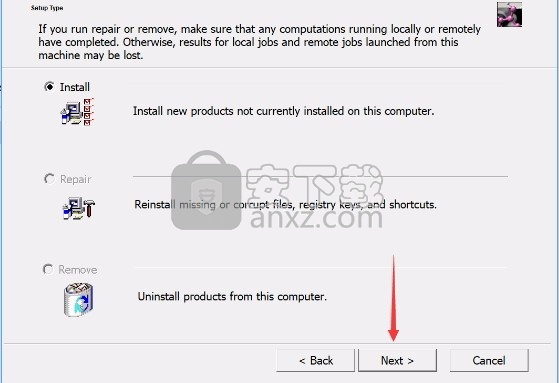
5、弹出以下界面,用户可以直接使用鼠标点击下一步按钮,可以根据您的需要不同的组件进行安装
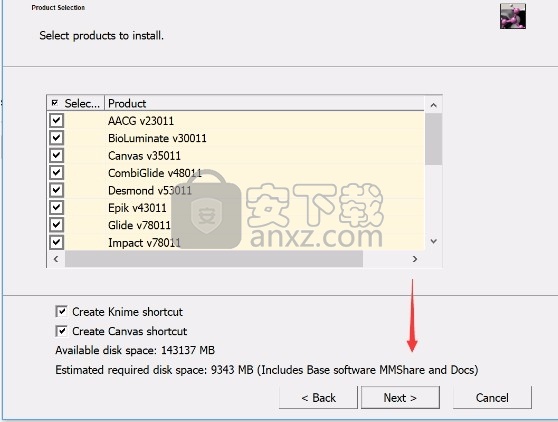
6、现在准备安装主程序,点击安装按钮开始安装
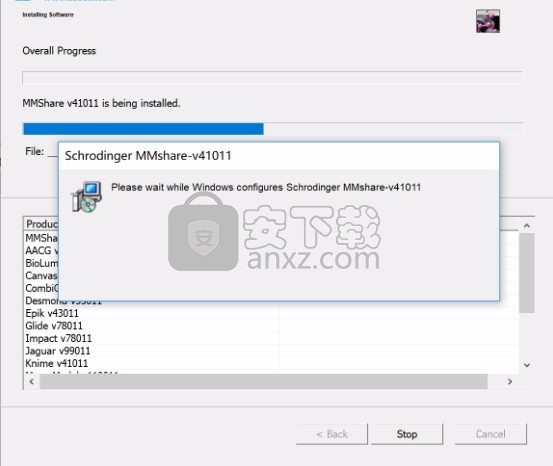
7、弹出应用程序安装进度条加载界面,只需要等待加载完成即可
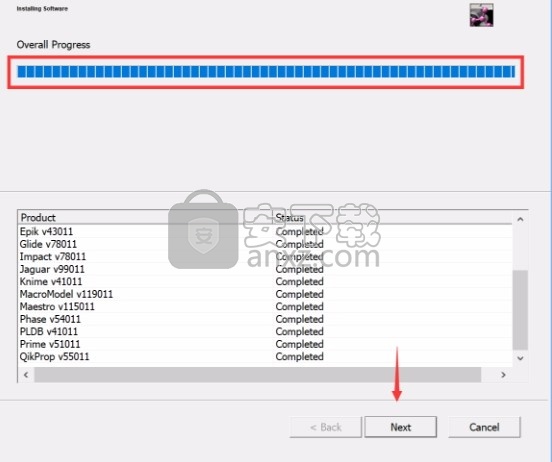
8、程序安装完成后,会弹出文件选择界面,根据需要勾选适配文件类型,点next
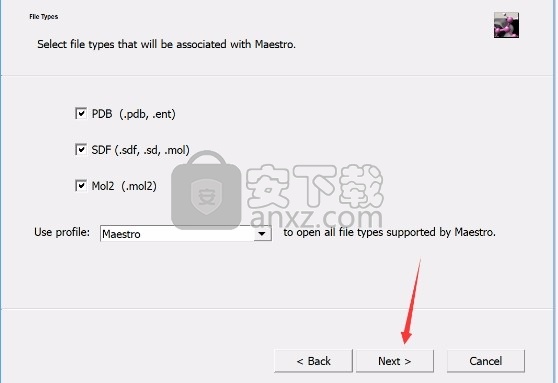
9、根据提示点击安装,弹出程序安装完成界面,点击完成按钮即可
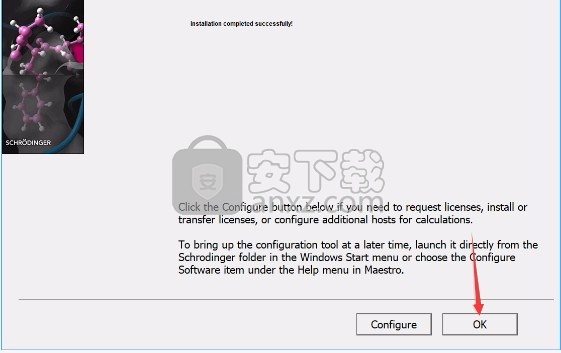
方法
1、程序安装完成后,先不要运行程序,打开安装包,将patcher文件夹内的patcher.exe复制到安装目录(默认:C:\Program Files\Schrodinger2017-4)
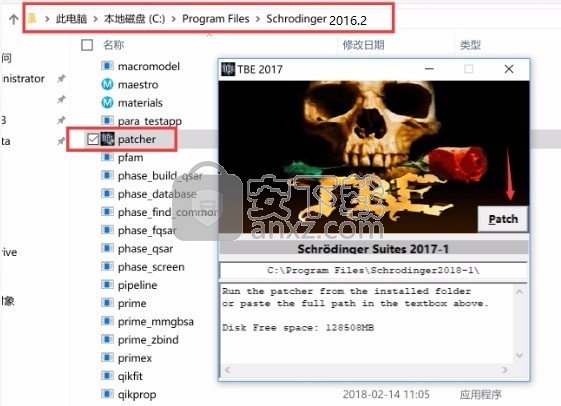
2、然后在程序安装路径下运行注册机,弹出对应的界面后,点patch完成
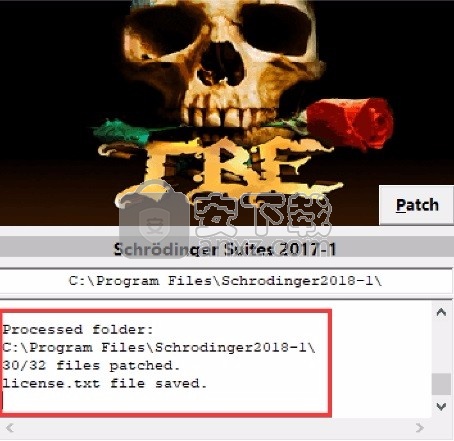
3、点开始菜单,这么多软件都可以免费使用了,双击应用程序将其打开,此时您就可以得到对应程序
使用说明
使用MM-GBSA预测对β-内酰胺酶TEM1有害的突变
错义突变可能对蛋白质的功能造成灾难性影响。结果,它们与多种疾病有关。然而,大多数错义变体仅对蛋白质功能具有名义上的影响。因此,区分这两种类型的错义突变的能力将极大地帮助药物发现在靶标鉴定和验证以及医学诊断方面的努力。
监测给定的错义突变和疾病表型的共现,为分类功能性错义突变提供了途径。但是,特定错义变体的发生通常非常罕见,这使得统计链接难以推断。在这项研究中,我们以MM-GBSA,并将其用于将突变归类为功能中断。
β-内酰胺酶TEM1中990个残基突变的大量数据集可用于评估性能,因为它富含功能破坏性突变和功能中性/有益突变。在此数据集上,我们将MM-GBSA的性能与预测功能破坏性突变的替代策略进行了比较。
我们观察到,MM-GBSA方法在整个数据集上获得的曲线下面积(AUC)为0.75,优于所有其他测试的预测指标。更重要的是,就该方法的通用性而言,MM-GBSA的性能对于数据集的各个部分都非常可靠。
尽管有一个明显的例外:蛋白质表面的突变是所有测试方法中最难以归类为功能破坏的突变。这可能是由于表面突变可用于破坏功能的多种机制所致,因此为将来的研究提供了方向。
DNA测序已经看到的巨大进步,因为在人类基因组在2001年[第一测序1,2 ]。DNA测序成本是这一进展的重要指标,因为自从第一个测序的人类基因组以来,DNA测序成本降低了六个数量级[ 3 ]。
这反过来促进了遗传变异的大型数据集[产生4 - 6 ]。特别值得注意的是ExAC和gnomAD数据库,其中包含超过12万个人的完整人类外显子组(蛋白质编码区)[ 4 ]。
然而,尽管存在大量的遗传变异,但预测遗传变异的功能效应仍然是错义突变的重大挑战[ 7]。错义突变是指基因的单氨基酸变化。
错义变异体在医疗诊断和发现方面发挥关键作用,因为某些错义变体已经被强烈疾病易感性的几个人类癌症相关[ 8,9 ]。最值得一提的例子是错义肿瘤抑制基因BRCA1和BRCA2 [变体8,10 ]。
然而,利用错义变体进行诊断的挑战在于许多错义变体对功能无害,在人类外显子组中占7.9%的位点[ 4 ]。此外,任何一个特定的错义变异体的稀有性使得绘制功能和错义变异体之间具有挑战性的统计链路[ 11,12]。
此外,由于疾病本身很少发生,因此罕见疾病还包含获得重要统计联系的另一个障碍。最后,使该问题进一步复杂化的事实是,用于评估特定错义变体如何影响蛋白质功能的实验分析仅覆盖有限的空间[ 8 ],从而使实验验证更加复杂。
几种算法已经被开发用于预测错义变异体[的功能的结果7,13 - 15 ]。这些算法中的许多算法都依赖于使用目标蛋白以及紧密相关的序列(通常来自其他物种)来生成多序列比对(MSA)。
该分析的基本前提是MSA中的保守残基对突变的耐受性较低。在此空间中,一些更强大的工具还包含结构信息,例如可访问的表面积,B因子和疏水性。尽管取得了一些成功,但这些工具显示出对输入序列比对的显着敏感性,因此性能在不同系统之间有所不同[ 16 ]。
在这项工作中,我们力求基准纯粹基于物理的方法,是独立称为MM-GBSA [序列比对的17,18 ]。MM-GBSA使用隐式溶剂模型结合分子力学能量函数来预测氨基酸突变的折叠自由能的相对变化。
MM-GBSA通过检测显着破坏蛋白质稳定性的突变来间接捕获破坏功能的突变。蛋白质稳定性和功能之间的联系由来已久,并已被探索[ 19 ]。由该分析领域引起的中心假设是,如果蛋白质显着不稳定,则将导致蛋白质错误折叠,因此突变将破坏蛋白质功能。
Beta内酰胺酶数据集
数据集在任何基准研究中都起着重要作用。它们必须足够大以获得有意义的统计数据,并且必须足够多样以避免数据偏差。因此,我们转向了β-内酰胺酶TEM-1的大规模突变研究[ 20]。
β内酰胺酶TEM-1是一种细菌酶,负责水解出现在β-内酰胺抗生素(如青霉素或阿莫西林)中的β-内酰胺键。TEM-1在结构和生化方面都有很好的特征。
最重要的是,上述研究提供了数百个有害且具有中性/有益功能的突变实例。反过来,这有助于减轻我们研究中的偏见,这也是我们选择此系统而不是人类基准的主要原因,因为人类基准缺乏有关功能中性/有益突变的大量信息。
本研究中使用的β内酰胺酶TEM-1数据集包含990个单点突变。在β内酰胺酶TEM-1上进行的功能测定的细节可以在Jacquier 等人中找到。简而言之,对于990个突变中的每一个,在几种浓度的阿莫西林下监测细胞生长,并记录抑制细胞生长所需的最小阿莫西林浓度,在本文中称为最小抑制浓度(MIC)。
MIC测量值通过以下等式log 2转换为MIC分数(MIC / 500)。500 mg / L是指野生型序列的MIC测量值。结果,MIC得分为0将表示与野生型酶相当的活性。MIC分数小于0的情况被归类为有害的。MIC得分为0或更高被分类为中性/有益。
功能有害突变和功能中性/有益突变的氨基酸分布如图1所示。这种二元分类方案的一个好处是,它使我们可以将有害集中每个氨基酸的观察频率与通过从二项式分布中随机选择所期望的突变概率进行比较。这使得容易识别在功能破坏集合中显着丰富的突变类型。
有趣的是,在有害集中,三种类型的突变出现的概率显着多(p <0.01)。这些是半胱氨酸,甘氨酸和脯氨酸的突变,其中最突出的是半胱氨酸。半胱氨酸在有害组中出现32次,而在中性/有益组中仅出现3次。
这大于有害集中的10倍富集。半胱氨酸在有害集中的富集可能与半胱氨酸参与阻止适当蛋白质折叠的二硫键的能力有关。脯氨酸在有害菌落中的出现频率是中性/有益菌落中的〜6.1倍。
脯氨酸在有害组中的富集可能与以下事实有关:脯氨酸在天然存在的氨基酸中占据唯一的二面体空间,当脯氨酸突变插入非脯氨酸位置时,这可能导致几何结构变形。
最后,观察到甘氨酸突变2。与有害/有益组相比,有害组的发生频率高4倍。甘氨酸侧链的小体积(单个氢原子)可能会在蛋白质核心中形成较大的孔洞,进而严重破坏整体蛋白质折叠的稳定性。
评估模型
超越数据的统计趋势,我们试图评估不同模型在功能上有害的氨基酸突变分类中的性能。为了评估模型,我们为每种方法计算了接收器工作特性(ROC)曲线。
然后测量曲线下的面积(AUC),以确定模型将有害突变与中性/有益突变分开的程度。AUC为0.5将代表一个将突变随机分类为有害的模型。AUC为1.0将代表一个完全符合实验指定分类的模型。
使用AUC,我们已经对5种不同的方法进行了基准测试,这些方法可预测对功能有害的突变。第一种方法是FoldX。FOLD-X是开发来预测蛋白质稳定性的变化的经验力场,并已适应于在蛋白质设计[使用21,22]。FoldX在此数据集上获得的AUC为0.67,这是所有测试方法中最低的AUC。
有趣的是,一种简单的方法(例如BLOSUM62替换矩阵,一种用于生成序列比对的工具)优于FoldX,获得的AUC为0.71。该方法通过预测在相关蛋白质家族中很少观察到的氨基酸取代将导致有害突变而起作用。
另一种简单的方法,即溶剂可及性(以前称为可及性)在此数据集上也表现良好,AUC为0.71。该方法通过预测掩埋位置的突变比溶剂暴露位置的突变更容易造成伤害而起作用。
最后,我们对Schrodinger的MM-GB / SA工具进行了基准测试,以预测蛋白质稳定性相对变化,Prime [ 18]。与FoldX相似,Prime预测,如果稳定性显着提高,则会发生有害突变。
Prime获得最大的AUC,获得的AUC为0.75。最后,我们对Prime的变体进行了基准测试,该变体通过在距突变侧链5Å以内的残基侧链进行精制,从而允许相邻残基具有更大的侧链灵活性。出乎意料的是,这会降低Prime的性能,而其AUC仅为0.69。
此外,我们检查了“基本稳定度”能量函数中每个术语的性能如何。总共有九个项可以计算出主要稳定性得分。第一项捕获共价相互作用(Covalent)的能量,例如键角和键拉伸。第二项对范德华相互作用(VDW)进行建模,它捕获了原子之间的感应偶极相互作用。第三项是库仑项(库仑),用于测量静电相互作用。第四个术语是广义出生术语(Solv GB),它模拟了氨基酸的溶剂化和去溶剂化作用。
第五项是与水的疏水相互作用的量度,称为“ Lipo”项。第六项是氢键项(Hbond)。第七项称为堆积,它测量π-π相互作用的质量。第八项是对侧链的自我互动(Self Cont)的度量。该术语捕获与主链原子的侧链氢键。诸如天冬酰胺,谷氨酰胺和丝氨酸的残基是参与这种相互作用类型的残基的实例。
最后,第九项代表每个氨基酸的解折叠能(参考)。素数稳定度总得分优于素数能量函数的所有各个组成部分(第九项代表每个氨基酸的解折叠能(参考)。素数稳定度总得分优于素数能量函数的所有各个组成部分(第九项代表每个氨基酸的解折叠能(参考)。素数稳定度总得分优于素数能量函数的所有各个组成部分。表明所有术语的总和比任何单个术语均能更好地预测功能中断突变。
人气软件
-

南方cass 65.9 MB
/简体中文 -

迈迪工具集 211.0 MB
/简体中文 -

origin(函数绘图工具) 88.0 MB
/简体中文 -

OriginLab OriginPro2018中文 493.0 MB
/简体中文 -

探索者TssD2017 417.0 MB
/简体中文 -

mapgis10.3中文(数据收集与管理工具) 168.66 MB
/简体中文 -

刻绘大师绿色版 8.32 MB
/简体中文 -

SigmaPlot 119 MB
/简体中文 -

keyshot6 1024 MB
/简体中文 -

Matlab 2016b 8376 MB
/简体中文
 女娲设计器(GEditor) v3.0.0.1 绿色版
女娲设计器(GEditor) v3.0.0.1 绿色版  iMindQ(思维导图软件) v8.1.2 中文
iMindQ(思维导图软件) v8.1.2 中文  Altair Embed(嵌入式系统开发工具) v2019.01 附带安装教程
Altair Embed(嵌入式系统开发工具) v2019.01 附带安装教程  avizo 2019.1(avizo三维可视化软件) 附安装教程
avizo 2019.1(avizo三维可视化软件) 附安装教程  ChemOffice 2017 附带安装教程
ChemOffice 2017 附带安装教程  绘图助手 v1.0
绘图助手 v1.0 











