

lingo11.0绿色中文版
附带使用说明- 软件大小:16.19 MB
- 更新日期:2019-08-31 19:36
- 软件语言:简体中文
- 软件类别:辅助设计
- 软件授权:免费版
- 软件官网:待审核
- 适用平台:WinXP, Win7, Win8, Win10, WinAll
- 软件厂商:

软件介绍 人气软件 下载地址
LINGO是一款数学模型创建和求解软件,既可用于非线性、线性规划,也可以用于一些线性和非线性方程组求解;该程序为用户提供了一般的非线性和非线性/整数功能;用户可以通过添加非线性许可证选项,然后使用其与非与LINDO API一起使用;该程序可以为用户提供全局求解器,该功能主要是在分支定界框架内组合一系列范围界限和范围缩减技术,以找到非凸非线性程序的经验证的全局解;传统的非线性求解器可能会陷入次优的本地解决方案,但是用户在使用全局解算器时不会出现类似的使用情况;强大又实用,需要的用户可以下载体验
软件功能
创建Turn-key应用
您可能需要为客户或同事创建一个自定义优化程序,而不是交互式运行LINGO。LINGO提供多个选择并将它的功能合并到您的应用中。其他应用调用LINGO求解器需要用到单独的许可包。
可调用的DLL和OLE接口
通过一些Windows开发环境无缝的将LINGO嵌入到您自己的应用中,如C#.NET, VB.NET, Visual Java, Visual Basic, Visual C++,或 Delphi。您的应用可以作为优化问题的用户前端——处理数据输入和存储以及准备将信息传递到LINGO的内存中。它也可以被设置为显示解决方案并为用户生成定制的报表。LINGO包括了可调用的DLL和OLE接口,可以让用户交互式访问所有的功能和命令。
从电子表格和数据库中调用LINGO
创建一个简单的应用,直接从电子表格如Excel和数据库如Access中调用LINGO。创建自己的“Solve”按钮就跟调用LINGO和运行一系列指定命令一样简单。
软件特色
1、简单的模型表示
Lingo可以将线性、非线性和整数问题迅速得予以公式表示,并且容易阅读、了解和修改
2、方便的数据输入和输出选择
Lingo建立的模型可以直接从数据库或工作表获取资料。也可以将求解结果直接输出到数据库或工作表
3、强大的求解引擎
Lingo内建的求解引擎有线性、非线性(convex and nonconvex)、二次、二次限制和整数最佳化
4、交互性的模型建立
Lingo提供完全互动的环境供您建立、求解和分析模型。同时也提供 DLL 和 OLE 界面可供使用者关联有关程序
5、多样性的工具栏和帮助功能
Lingo提供的所有工具和文件可使你迅速入门和上手。Lingo 使用者手册有详细的功能定义等
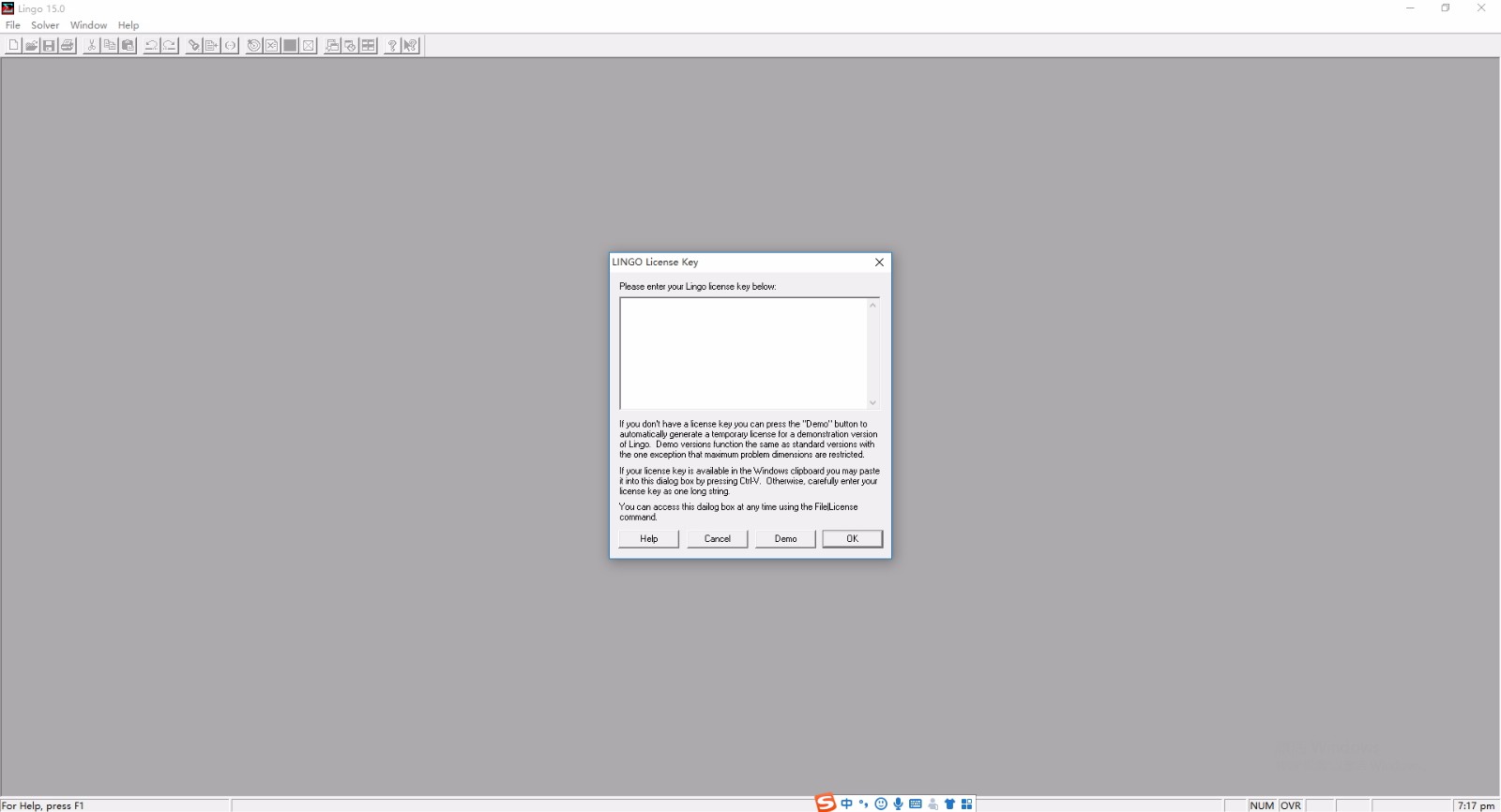
安装步骤
1、需要的用户可以点击本网站提供的下载路径下载得到对应的程序安装包
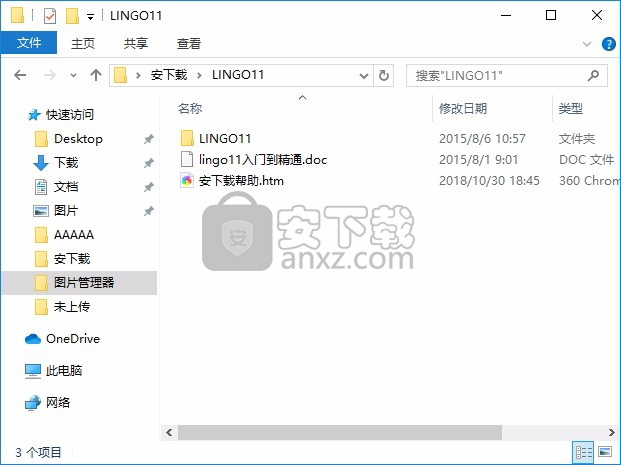
2、通过解压功能将压缩包打开,打开程序数据包后就可以看到对应的程序文件
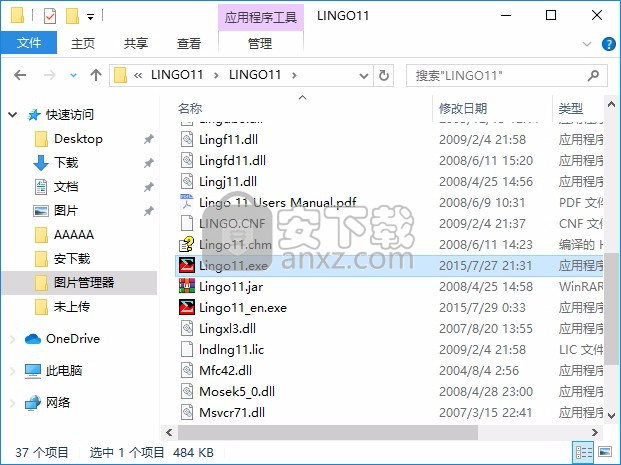
3、找到主程序,双击主程序即可将程序打开
使用说明
密集派生集示例 - 混合
以下模型说明了在混合模型中使用密集派生集等。 在混合模型中,一种是将原材料混合到成品中,该成品必须满足一个或多个维度上的最低质量要求。 目标是提供原材料的混合物,以最低的成本满足质量要求。
此模型可以在名为CHESS的主LINGO目录下的SAMPLES子目录中找到。
配方
该模型中的原始集合是坚果类型和混合坚果的品牌。我们可以在sets部分声明它们如下:
集:
坚果:供应;
品牌:价格,产品;
ENDSETS
NUTS集具有单一属性SUPPLY,我们将用它来存储每日坚果的磅数。 BRANDS套装具有PRICE和PRODUCE属性,其中PRICE存储品牌的销售价格,而PRODUCE代表每个品牌每天生产多少磅的决策变量。
然而,我们需要一组,这是我们一直承诺的密集派生集。为了输入品牌公式,我们需要在螺母类型和品牌上定义二维表。为此,我们将从NUTS和BRANDS集的交叉生成一个名为FORMULA的派生集。添加这个派生集,我们得到完成的集部分:
集:
坚果:供应;
品牌:价格,产品;
公式(坚果,品牌):OUNCES;
ENDSETS
我们标题为派生集FORMULA。它具有单一属性OUNCES,用于存储每磅每磅品牌使用的坚果盎司。由于我们尚未指定此衍生集的成员,因此LINGO假设我们需要包含所有坚果和品牌对的完整密集集,总共八个(坚果,品牌)对。
现在声明了我们的集合,我们可以继续构建数据部分。我们初始化我们的三套,NUTS,BRANDS和FORMULA,以及两个数据属性SUPPLY和PRICE如下:
数据:
NUTS,SUPPLY =
花生750
CASHEWS 250;
品牌,价格=
PAWN 2
骑士3
BISHOPP 4
KING 5;
公式= 15 10 6 2
1 6 10 14;
ENDDATA
随着集合和数据的建立,我们可以开始输入我们的目标函数和约束。最大化总收入的目标函数是直截了当的。我们可以表达为:
MAX = @SUM(品牌(I):价格(I)*产品(I));
我们的模型只有一类限制:我们不能使用比我们每天提供的坚果更多的坚果。用语言来说,我们希望确保:
对于每个坚果i,我使用的坚果磅数必须是
小于或等于螺母的供应i。
我们可以在LINGO中表达:
@FOR(NUTS(I):
@SUM(品牌(J):
OUNCES(I,J)* PRODUCE(J)/ 16)<= SUPPLY(I));
我们将左侧的总和除以16,将其从盎司转换为磅。
在此示例中,我们将介绍使用具有显式列表的稀疏派生集。您还记得,当我们使用此技术定义稀疏集时,我们必须明确列出属于该集的所有成员。这通常是由父集的完整笛卡尔积产生的密集的一小部分。
对于我们的示例,我们将建立PERT(项目评估和审查技术)模型,以确定涉及推出新产品的项目中任务的关键路径。 PERT是一种简单但功能强大的技术,在20世纪50年代开发,用于帮助管理人员跟踪大型项目的进度。 PERT在识别项目中的关键活动时特别有用,如果延迟,将会延迟整个项目。这些时间关键活动被称为项目的关键路径。对项目的动态进行深入了解可以很长时间地保证项目不会受到牵制并导致延迟。事实上,PERT证明是如此成功,它首次使用的Polaris项目提前18个月完成。 PERT继续在各种项目中成功使用。
们需要一个原始集来表示项目的任务。我们可以使用set定义将这样的集添加到模型中:
集:
任务:时间,ES,LS,SLACK;
ENDSETS
我们将四个属性与TASKS集相关联。属性的定义是:
时间
是时候完成任务了
ES
最早可能的任务开始时间
LS
该任务的最新可能开始时间
松弛
任务的LS和ES之间的差异
TIME属性作为数据提供给我们。我们将计算其余三个属性的值。如果任务的时间为0,则表示任务必须按时启动或整个项目将被延迟。具有0松弛时间的任务集合构成了项目的关键路径。
为了计算任务的开始时间,我们需要优先级关系。优先关系可以被视为有序任务对的列表。例如,必须在FORECAST任务之前完成DESIGN任务的事实可以表示为有序对(DESIGN,FORECAST)。在TASKS集上创建二维派生集将允许我们输入优先关系列表。具体来说,我们添加派生集定义PRED:
集:
任务:时间,ES,LS,SLACK;
PRED(TASKS,TASKS);
ENDSETS
接下来,我们可以通过包括以下内容在数据部分输入TASKS集和任务时间:
数据:
TASKS,TIME =
设计10
预测14
调查3
DUMMY 0
价格3
附表7
COSTOUT 4
火车10
;
ENDDATA
设置PRED是稀疏派生集,带有显式列表,我们希望在此示例中突出显示。该集合是从自身设置的TASKS的交叉派生的子集。该集是稀疏的,因为它只包含在TASKS的TASKS完整交叉中找到的49个成员中的8个。该集合被称为“显式列表”集,因为我们将明确列出我们想要包含在集合中的成员。在有数千个成员可供选择的情况下,明确列出稀疏集的成员可能不方便,但是只要设置成员资格条件没有很好地定义并且稀疏集大小相对于密集备选方案小,它确实有意义。将PRED的初始化添加到数据集给我们:
ENDDATA
请记住,此集合的第一个成员是有序对(DESIGN,FORECAST) - 而不仅仅是单个任务DESIGN。因此,该集合总共有8个成员,它们都对应于优先关系图中的有向弧。
现在,随着我们的集合和数据的建立,我们可以将注意力转向构建模型的公式。我们有三个要计算的属性:最早的开始(ES),最新的开始(LS)和松弛时间(SLACK)。诀窍是计算ES和LS。一旦我们有了这些时间,SLACK只是两者的差异。
让我们首先提出一个计算ES的公式。在完成所有前任任务之前,任务无法开始。因此,如果我们找到所有前任的最后完成时间,那么我们也找到了它最早的开始时间。因此,换句话说,任务t的最早开始时间等于任务t的所有前任的最大值,即前任的最早开始时间加上其完成时间之和。相应的LINGO表示法是:
@FOR(TASKS(J)| J#GT#1:
ES(J)= @MAX(PRED(I,J):ES(I)+ TIME(I))
请注意,我们通过添加条件限定符J#GT#1来跳过第一个任务的计算。我们这样做是因为第一个任务没有前驱。我们将给第一个任务一个任意的开始时间,如下所示。
计算LS稍微棘手,但与ES非常相似。换言之,任务t开始的最新时间是后继者最早开始的总和减去执行任务t的时间的所有后继任务的最小值。如果任务t在此之后开始,它将禁止至少一个后继者从其最早的开始时间开始。转换为LINGO语法给出:
@FOR(TASKS(I)| I#LT#LTASK:
LS(I)= @MIN(PRED(I,J):ES(J) - TIME(I))
在这里,我们省略了最后一个任务的计算,因为它没有后继任务。
计算松弛时间只是LS和ES之间的差异,可以写成:
@FOR(TASKS(I):SLACK(I)= LS(I) - ES(I));
我们可以将第一个任务的开始时间设置为某个任意值。出于我们的目的,我们将使用以下语句将其设置为0:
ES(1)= 0;
我们现在已经输入了用于计算所有变量值的公式,但最后一个任务的最新开始时间除外。事实证明,如果最后一个项目是
人气软件
-

南方cass 65.9 MB
/简体中文 -

迈迪工具集 211.0 MB
/简体中文 -

origin(函数绘图工具) 88.0 MB
/简体中文 -

OriginLab OriginPro2018中文 493.0 MB
/简体中文 -

探索者TssD2017 417.0 MB
/简体中文 -

mapgis10.3中文(数据收集与管理工具) 168.66 MB
/简体中文 -

刻绘大师绿色版 8.32 MB
/简体中文 -

SigmaPlot 119 MB
/简体中文 -

keyshot6 1024 MB
/简体中文 -

Matlab 2016b 8376 MB
/简体中文
 女娲设计器(GEditor) v3.0.0.1 绿色版
女娲设计器(GEditor) v3.0.0.1 绿色版  iMindQ(思维导图软件) v8.1.2 中文
iMindQ(思维导图软件) v8.1.2 中文  Altair Embed(嵌入式系统开发工具) v2019.01 附带安装教程
Altair Embed(嵌入式系统开发工具) v2019.01 附带安装教程  avizo 2019.1(avizo三维可视化软件) 附安装教程
avizo 2019.1(avizo三维可视化软件) 附安装教程  ChemOffice 2017 附带安装教程
ChemOffice 2017 附带安装教程  绘图助手 v1.0
绘图助手 v1.0 











