

OriginLab OriginPro 2015
附带安装教程- 软件大小:775.93 MB
- 更新日期:2019-06-14 16:37
- 软件语言:简体中文
- 软件类别:辅助设计
- 软件授权:免费版
- 软件官网:待审核
- 适用平台:WinXP, Win7, Win8, Win10, WinAll
- 软件厂商:

软件介绍 人气软件 下载地址
OriginPro2015是OriginLab公司最新出品的的科学绘图和数据分析软件,相比较旧版本,此版本对系统以及功能模块都进行了加强与优化;现在克隆Origin项目已经使用新数据轻松复制图形和分析任务,支持使用所需的数据,图形,分析和报告设置Master Origin项目,用户还可以根据自己的需要制作克隆项目,这将创建没有数据的重复项目,支持导入新数据以更新所有图表,结果和报告,用户还可以使用克隆功能对大型项目进行探索性分析;克隆包含数据,图形和分析的大型Origin项目,可以通过选择维护数据连接器链接到克隆项目中原始项目中的数据表,用户可以从原始项目中重新导入任何特定数据表,以继续进一步分析和探索该数据子集;这样可以避免重复包含相同数据的大型项目,并可以加快数据分析的探索阶段。强大又实用,需要的用户可以下载体验
新版功能
曲线拟合
在参数汇总表中包含派生参数的标准错误
为二极管和太阳能电池数据添加两个新的隐式拟合函数
隐函数中的支持积分
<和>非线性曲线拟合对话框参数选项卡上的两个按钮,用于在参数集之间切换以比较拟合结果
定义拟合函数时提供参数初始化公式的选择
更多内置拟合功能,如光合作用辐照度(PI)曲线,3D曲线等。
使用X误差在Fit Linear中提供Deming方法PROPROPROPROPRO
在图表中为LR / PR / NLFit和峰值拟合定制参数表
放大非线性曲线拟合的预览选项卡
改进的拟合结果:添加残差的正态概率图,将残差图放在单个图中
适合和排列类别中的所有功能PROPROPROPROPROPRO
隐式/显式函数的正交回归PROPROPROPROPRO+
计算派生参数的标准误差
线性拟合,支持X错误PROPROPROPROPRO+
表面适合多峰PROPROPROPROPROPRO
用于拟合函数创建的新拟合函数生成器
拟合的图形残差分析
Find-X / Find-Y工具,用于线性,多项式和非线性拟合
用于非线性曲面/矩阵拟合的新型Find-Z工具
软件特色
峰值分析器:支持输出基线在查找峰值后减去峰值信息,在Notes节点中报告基线模式,在适合控制对话框中添加提示选项卡
峰值检测的新方法:傅立叶自反卷积
正极和负极峰的自动绑定设置
在批量峰分析中按顺序初始化参数值
多峰值拟合工具
批量峰值拟合
峰值分析仪:峰值拟合PROPROPROPROPROPRO
峰值分析仪:适合峰值的基线PROPROPROPROPROPRO
峰值分析仪:峰值积分
峰值分析仪:峰值发现
峰值分析仪:基线检测
峰值分析器:基线减法
安装步骤
1、需要的用户可以点击本网站推荐的下载网址,点击后即可下载得到对应的程序安装包
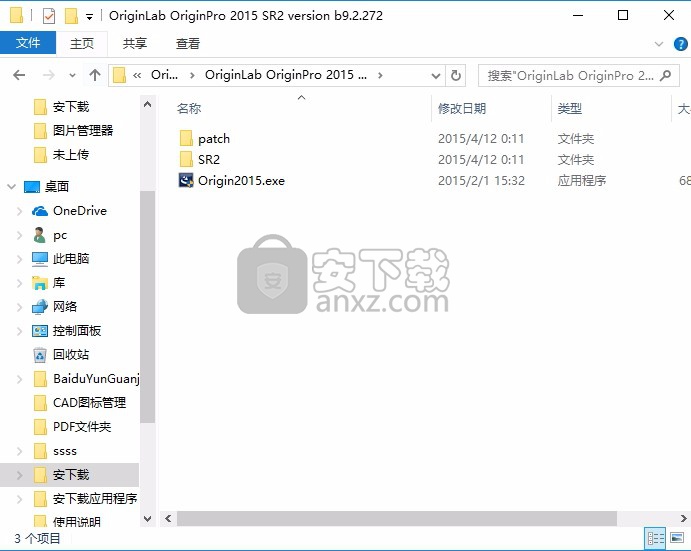
2、此程序可以在计算机上安装 0rigin OriginPro2015。单击下一步维续。
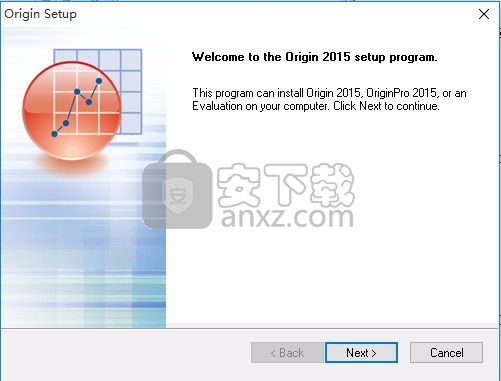
3、弹出应用程序许可协议同意界面,需要同意才能进行程序安装
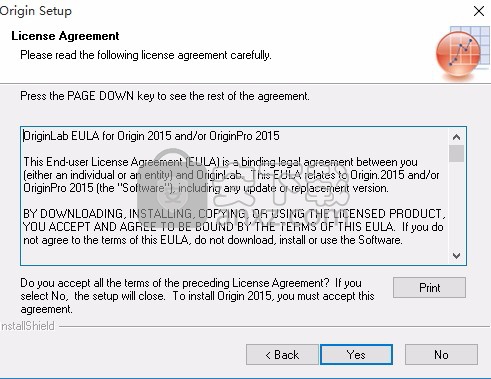
4、请选择下面的一个选项试用版包含0riginl0ri两个版本。您可通过帮助主菜单进行版本的切换 0riginProE提供更多分析工具和App用以进行曲线拟合、峰拟合、曲面拟合,高级统计以及信号处理。
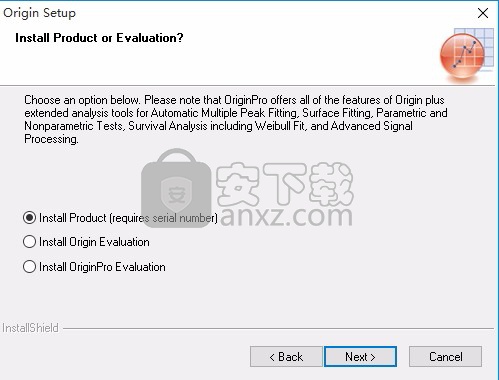
5、请输入您的名字、所在公司的名称以及产品序列号。输入origin 2015序列号【GF3S4-9089-7991320】
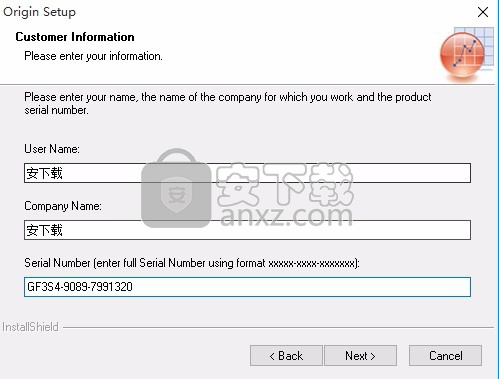
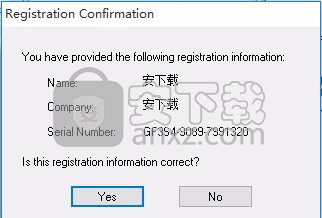
6、将界面中的勾选取消,不要勾选进行程序安装
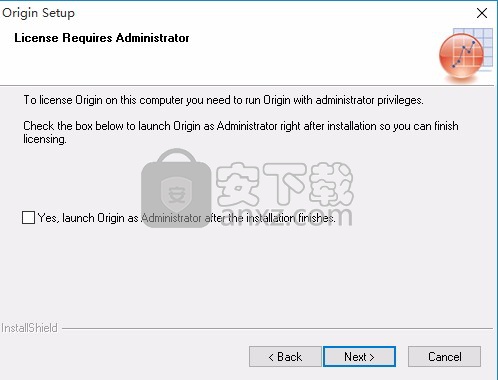
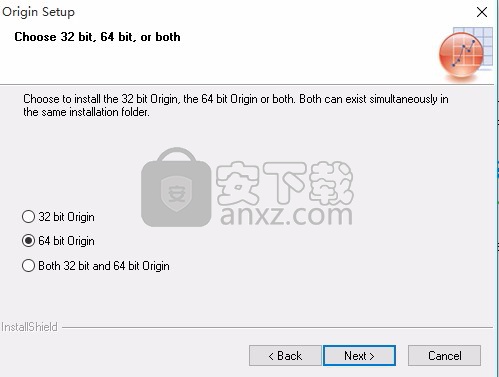
7、选择安装32位 0rigins0riging0或者两者都安装。两者可以同时存在于同一个安装文件夹中
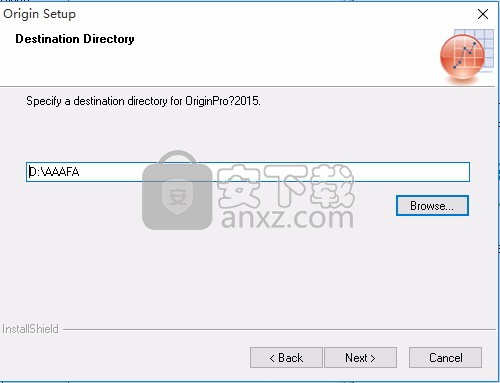
8、点击浏览按钮即可将应用程序的安装路径进行更改,可以自行决定
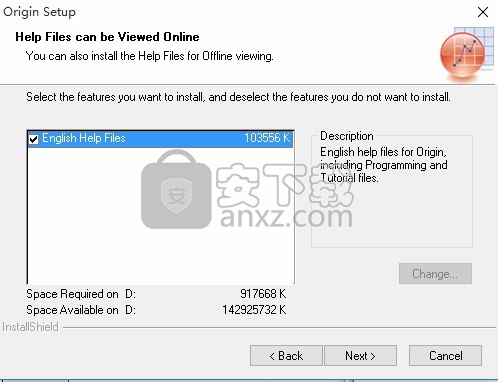
9、选择功能,选择安装程序将安装的功能。请选择要安装的功能,清除无需安装的功能。
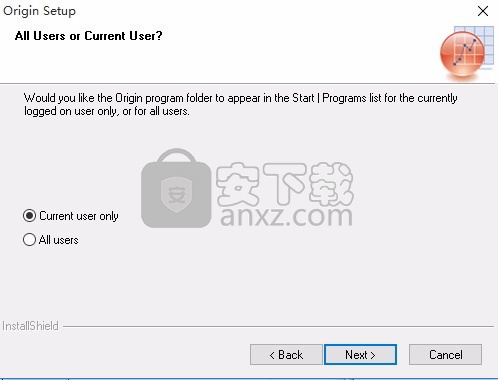
10、您希望 Originf0程序文件夹显示在仅当前登录用户的程序列表,或所有用户的程序列表。
11、装程会程标如割的程序件来”忠货可以输入新的文件夹茗称,或从“现有文件”列表中选择一个单
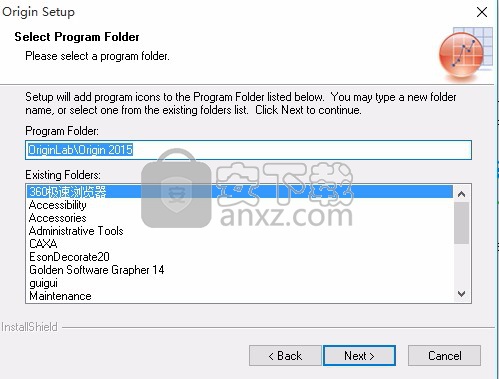
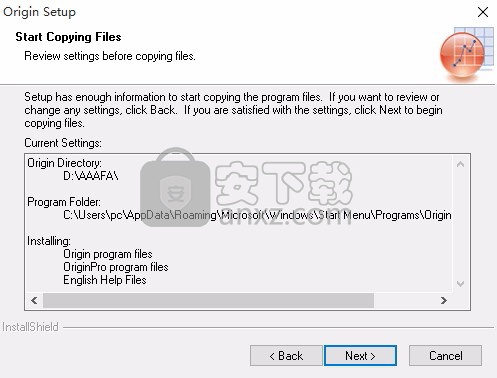
12、安装程序具有开始复制程序文件的足够信息。要查看或更改任何设置,请单击“上一步”。如果对设盖满意,请单击“下二步”以开始复制文件。
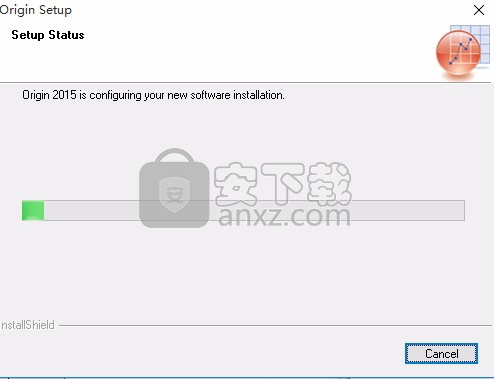
13、Origin2017安装程序正在执行所请求的操作。
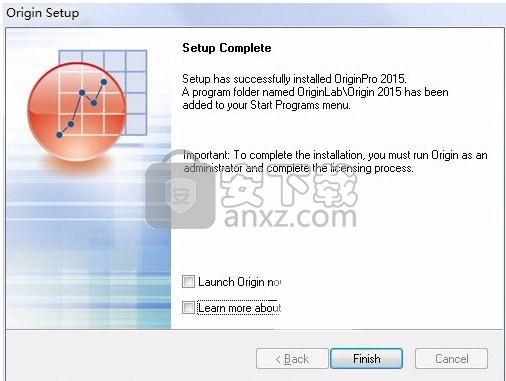
14、安装程序已成功安装,点击完成按钮即可推出程序安装界面
方法
1、打开安装包进入“patch/crack”目录,将文件“ok9.dll”和“patch.exe”复制到OriginPro 2015目录下运行,默认目录C:\Program Files\OriginLab\Origin2015
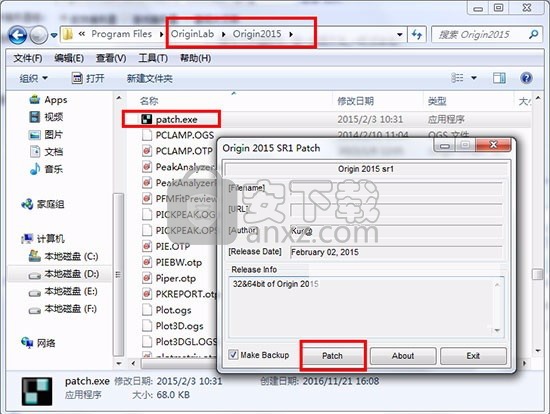
2、点击“Patch”,然后进入C:\Program Files\OriginLab\Origin2015目录,依次找到“ok9.dll”和“ok9_64.dll”点击打开即可完成,成功出现如下提示:
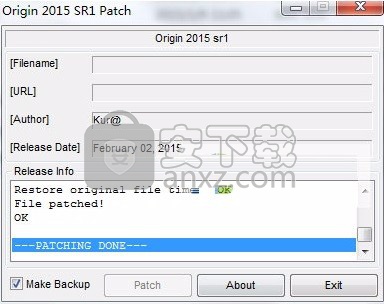
3、完成以上操作步骤即可将应用程序完成,打开即可使用

使用说明
OriginC
与LabTalk一样,OriginC现在可以支持UTF-8编码的文本字符串,并通过新的系统变量 @ SCOC进行控制。当它设置为1时,大多数字符串类的所有方法都将使用代码点进行位置和字符计数。当它设置为0(零)时,这些方法将利用基于0的字节偏移量来计算位置和字节数。与此系统变量的LabTalk版本不同,@ SCOC默认设置为0(零)意味着“开箱即用”OriginC不会考虑代码点并且会坚持使用字节。这是Origin 2018的选择,以确保产品附带的OriginC的大型代码库中没有无法预料的问题。
虽然字符串类的方法可以支持UTF-8编码的文本字符串,但是大多数其他字符和字符串操作函数都不会考虑非ASCII范围文本而不管@ SCOC的值 - 它们只处理字节。因此,必须考虑使用它们,特别是对于可能包含ASCII范围之外的字符(超过1个字节)的字符串。
因此,如果OriginC不支持使用“开箱即用”的代码点,那么如果需要在调用字符串类的成员时如何使用它们呢?
提供OriginC宏以启用此功能。宏是 ENABLE_STR_LENGTH_USE_CHAR_COUNT ; 它仅在使用宏的范围内将@SCOC设置为1。一旦超出范围,@ SCOC将恢复为之前的值。因此,宏应放在需要使用的范围内。
例如,您可以使用下面的函数执行与上面讨论的LabTalk代码相同的操作(记住OriginC使用基于0的偏移):
// Assumes @SCOC=0 prior to function call.
void func1()
{string str = "实验 #1";
int len1 = str.GetLength(); // returns 9
string sub1 = str.Mid(3, 2); // returns garbage
ENABLE_STR_LENGTH_USE_CHAR_COUNT;
int len2 = str.GetLength(); // returns 5
string sub2 = str.Mid(3, 2); // returns #1}
请注意使用宏之前和之后的差异?并且因为它仅在函数的范围内,所以@SCOC在函数返回时恢复为其先前的值。
最后,根据这些行,有一个宏,如果需要,可以将@SCOC显式设置为0。它是: DISABLE_STR_LENGTH_USE_CHAR_COUNT ;
为了进一步支持UTF-8编码的文本字符串,已修改了字符串类的某些方法。
String :: GetLength()现在原型为:
1int GetLength( BOOL bAuto = true );
的 B自动设定 参数是只适用时@ SCOC = 1。如果为true(默认值),则该方法返回代码点中的长度。如果为false,则返回以字节为单位的长度。如果@ SCOC = 0,则无论bAuto的值如何,总是返回以字节为单位的长度 。
String :: GetAt()和string :: SetAt()已经过载了,每个版本都允许在给定字符串中的某些偏移处获取和设置子字符串(而不仅仅是字符类型)。这允许字符比UTF-8中的多个字节跨越。
2int GetAt(int nIndex, string& str); //Return:0 if index specified is invalid, 1 if character is ANSI, 2 if character is Unicode
void SetAt(int nIndex, LPCTSTR pstr );
最后,如果你想获得与字符串变量相关的缓冲区,那么使用str很有诱惑力 。的GetBuffer (STR 。GetLength进行()); 。不要这样做,因为如果Code Point使用有效,缓冲区的长度将是错误的。而是使用 str 。GetBuffer (0 ); 因为它与代码点或字节是否使用无关。
你看到的并不总是你得到的
以下是对复杂主题的过度简化,但应该足以说明问题。在最常见的情况下,它应该不上来,但仍然是很好的了解。
从编程角度来看,Unicode文本的一个混淆方面是“视觉角色”(字形)和代码点之间并不总是存在1对1关系的概念。一些“视觉角色”实际上是所谓的字形簇。也就是说,“视觉角色”由许多代码点组成,而不仅仅是一个。这些字形簇通常由基本字符和许多组合字符或非间距标记组成。这些是特殊的代码点,可以通过某种方式直观地修改基本字符,但它们本身不可见。
从维基百科条目借来的一个例子是瑞典姓“Åström”。视觉上名称是6个“字符”,但它可以由许多不同的代码点组成。在下表中,我们可以看到两个看起来完全相同的名称变体:
文本代码点
乻tr歮-HU + 00C5 U + 0073 U + 0074 U + 0072 U + 00F6 U + 006D
乻tr歮-HU + 0041 U + 030A U + 0073 U + 0074 U + 0072 U + 006F U + 0308 U + 006D
在第一个示例中,Å和ö(以蓝色突出显示的代码点)是预先组合的字符。这是基本字符,任何组合字符都卷入一个代码点。所以,这个例子没有问题。但是,在第二个例子中,绿色的基本字符由红色的组合字符修改。例如, U + 0041是基本字符A.它由U + 030A修改,它是字符上方的组合环。U + 006F是由组合分音符U + 0308修改的基本字符。这两个例子都是完全合法且有效的。
那么这对LabTalk和OriginC意味着什么呢?好吧,当使用代码点处理文本字符串时,这两种语言都没有考虑“集群”。也就是说,相关的字符串函数将一组代码点视为单独的代码点。例如,虽然LabTalk的len()函数在第一个示例的情况下将返回6,但它将为第二个报告8,因为整个字符串中确实有8个代码点。
这在编程语言和其他产品中并不罕见。例如,Excel将报告与Origin相同的结果。没有专门的模块,Python会显示相同的行为。虽然有用于确定字素集群边界的编码方法,但它就像一般的主题 - 相当复杂。因此,它不会在Origin 2018中实现。幸运的是,绝大多数Unicode文本字符串不是字形集群,因此这个特定问题可能对大多数编码工作没有影响。
人气软件
-

南方cass 65.9 MB
/简体中文 -

迈迪工具集 211.0 MB
/简体中文 -

origin(函数绘图工具) 88.0 MB
/简体中文 -

OriginLab OriginPro2018中文 493.0 MB
/简体中文 -

探索者TssD2017 417.0 MB
/简体中文 -

mapgis10.3中文(数据收集与管理工具) 168.66 MB
/简体中文 -

刻绘大师绿色版 8.32 MB
/简体中文 -

SigmaPlot 119 MB
/简体中文 -

keyshot6 1024 MB
/简体中文 -

Matlab 2016b 8376 MB
/简体中文
 女娲设计器(GEditor) v3.0.0.1 绿色版
女娲设计器(GEditor) v3.0.0.1 绿色版  iMindQ(思维导图软件) v8.1.2 中文
iMindQ(思维导图软件) v8.1.2 中文  Altair Embed(嵌入式系统开发工具) v2019.01 附带安装教程
Altair Embed(嵌入式系统开发工具) v2019.01 附带安装教程  avizo 2019.1(avizo三维可视化软件) 附安装教程
avizo 2019.1(avizo三维可视化软件) 附安装教程  ChemOffice 2017 附带安装教程
ChemOffice 2017 附带安装教程  绘图助手 v1.0
绘图助手 v1.0 











