

ScrapydWeb(爬虫管理平台)
v1.4.0 官方版- 软件大小:1.60 MB
- 更新日期:2021-04-28 10:33
- 软件语言:英文
- 软件类别:网页辅助
- 软件授权:免费版
- 软件官网:待审核
- 适用平台:WinXP, Win7, Win8, Win10, WinAll
- 软件厂商:

软件介绍 人气软件 下载地址
ScrapydWeb提供web抓取项目管理功能,可以在软件上添加多个地址执行抓取,可以在软件运行蜘蛛对网络信息采集,采集服务全部在软件上显示,您可以添加新的Scrapyd
server项目到软件上分析,实现集群管理模式,方便对多个web项目抓取,抓取信息全部在软件显示,可以查看列表项目,可以查看日志内容,可以通过可视化的界面查看日志数据,可以结合统计表分析采集数据,可以建立分布式方案执行抓取任务,可以在Heroku上Scrapyd设置集群,可以在web界面管理你的任务,结合定时功能可以在任意时间段运行蜘蛛执行抓取任务,如果你需要这款软件就可以下载使用!
软件功能
一、Scrapyd集群管理
支持所有Scrapyd JSON API
分组,过滤和选择任意数量的节点
只需单击几下即可在多节点上执行命令
二、Scrapy日志分析
统计资料收集
进度可视化
日志分类
三、增强功能
自动打包项目
与整合 LogParser
计时器任务
监控和警报
行动使用者介面
Web UI的基本身份验证
软件特色
支持定时任务计划定期运行蜘蛛程序
在数据库中坚持工作信息
适应于LogParser v0.8.1,如果可用,请在“统计信息”页面中显示Crawler.stats和Crawler.engine。
支持备份stats json文件,以防Scrapyd删除原始日志文件
支持分别设置EMAIL_USERNAME (问题28)
为“作业,日志和项目”页面引入新的UI
在“部署项目并运行Spider”页面中添加“从服务器同步”页面复选框
将“概述”重命名为“服务器”,将“仪表板”重命名为“作业”
官方教程
如何简单高效地部署和监控分布式爬虫项目
安装与设定
1、确保已在所有主机上安装并启动了Scrapyd。请注意,如果要远程访问Scrapyd服务器,则必须手动将bind_address设置为,bind_address = 0.0.0.0然后重新启动Scrapyd,以使其在外部可见。
2、通过命令在您的主机之一上安装ScrapydWebpip install scrapydweb。
3、通过命令启动ScrapydWebscrapydweb。(将在第一次启动时生成一个配置文件以自定义设置。)
4、启用HTTP基本身份验证(可选)。

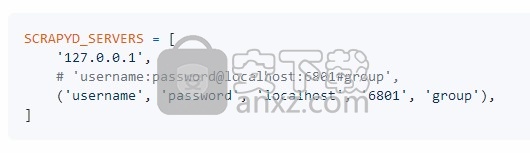
5、添加您的Scrapyd服务器,支持字符串和元组格式,您可以附加用于访问Scrapyd服务器的基本身份验证,以及用于分组或标记的字符串。
6、通过命令重新启动ScrapydWebscrapydweb。
访问网页界面
访问http://127.0.0.1:5000,然后使用上面的USERNAME / PASSWORD登录。
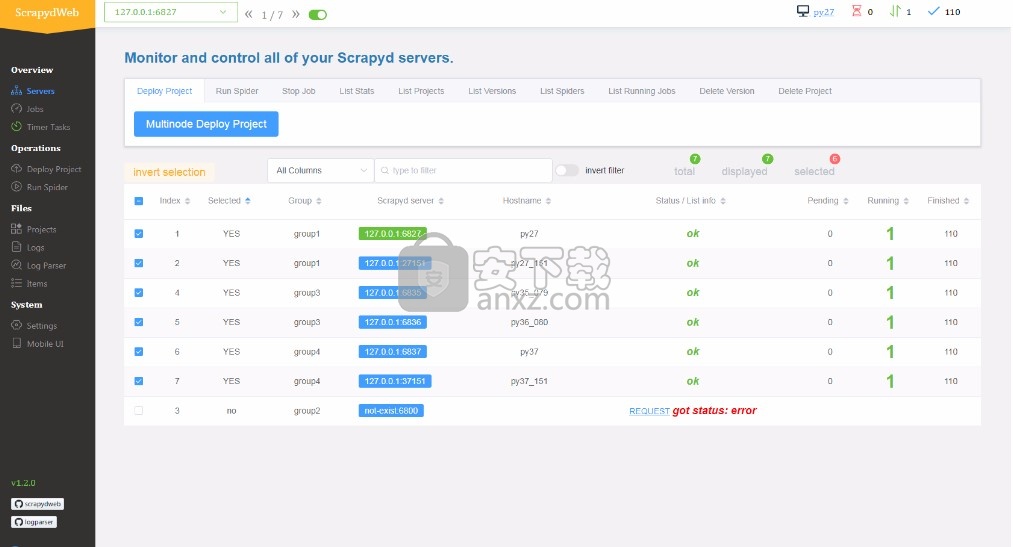
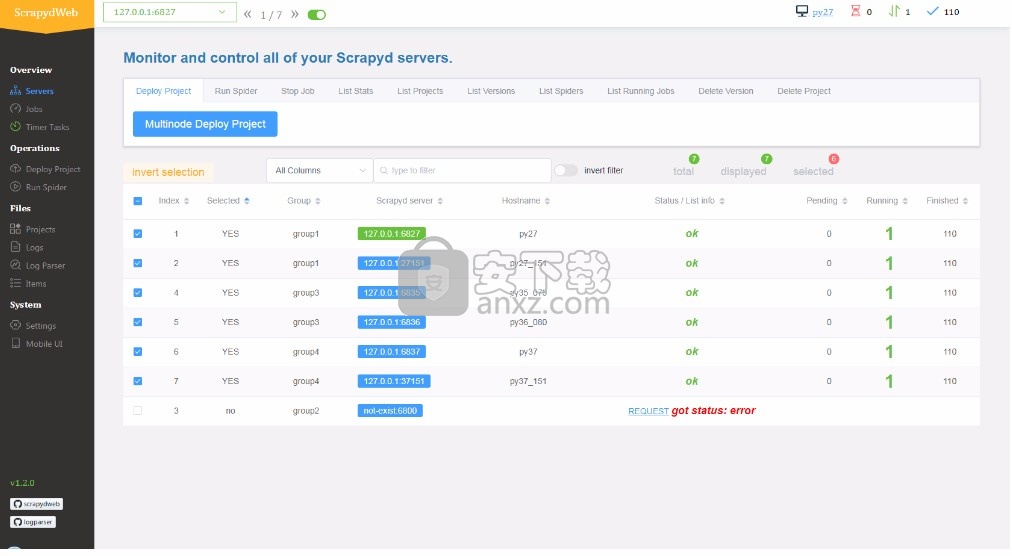
服务器页面将自动显示所有Scrapyd服务器的工作状态。
您可以通过分组和过滤来选择任意数量的Scrapyd服务器,然后只需单击几下即可在群集上调用Scrapyd的HTTP JSON API。
与LogParser集成后,“作业”页面可以自动显示您的抓取作业的页面和项目信息。
默认情况下,ScrapydWeb会定期创建您的抓取作业的快照并将其保存在数据库中,以避免在重新启动Scrapyd服务器时丢失作业信息。(第12期)
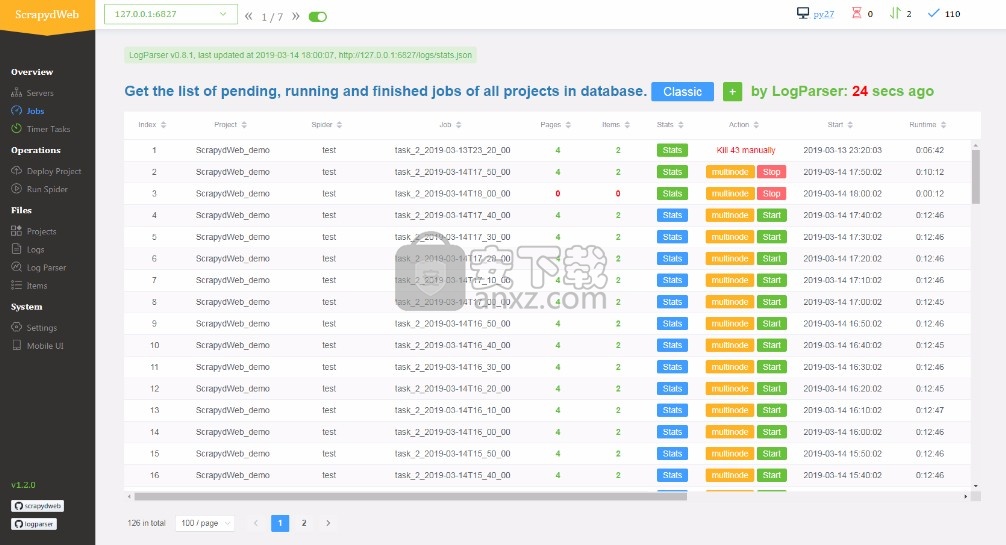
部署项目
在将SCRAPY_PROJECTS_DIR选项设置为包含Scrapy项目的路径之后,ScrapydWeb将列出该目录中的所有项目,并选择最新修改的项目。只需选择一个项目并按按钮即可提交,然后在后台自动打包。
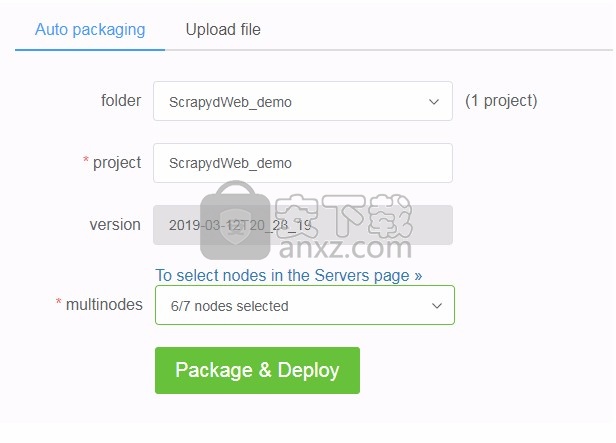
如果ScrapydWeb在远程服务器上运行时正在本地开发Scrapy项目怎么办?除了上传egg文件,您还可以使用存档软件或通过tar命令将项目文件夹压缩为存档文件tar -czvf projectname.tar.gz /home/username/myprojects/projectname,然后上传。
您可以选择任意数量的Scrapyd服务器来部署项目。
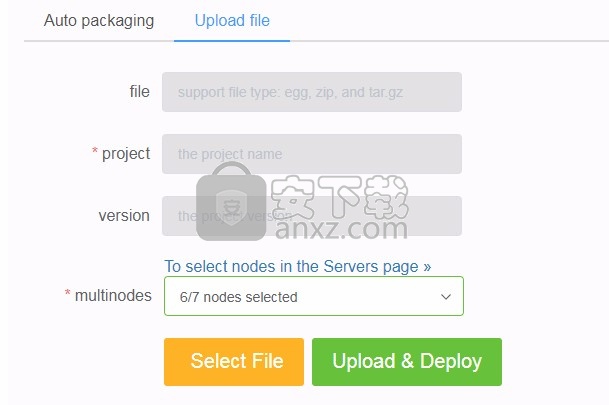
运行蜘蛛
依次从下拉框中选择一个项目,一个版本和一个Spider。
可以随意传递任何Scrapy设置或Spider参数。
支持基于APScheduler创建计时器任务。(如果要同时启动多个蜘蛛,请不要忘记调整Scrapyd的max-proc选项)
您可以选择任意数量的Scrapyd服务器来运行蜘蛛。
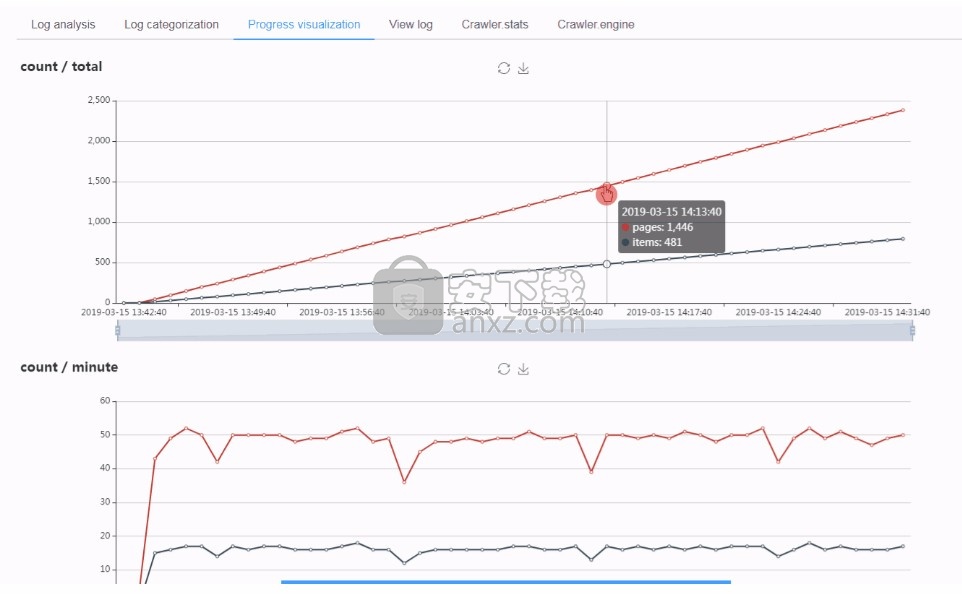
日志分析和可视化
如果在同一台计算机上运行Scrapyd和ScrapydWeb,建议设置SCRAPYD_LOGS_DIR和ENABLE_LOGPARSER选项,以便LogParser与ScrapydWeb一起自动启动。该LOGPARSER的子进程将在分析和定期增量指定目录Scrapy日志文件,从而加快统计信息页的加载不消耗内存和带宽因请求原始日志文件。
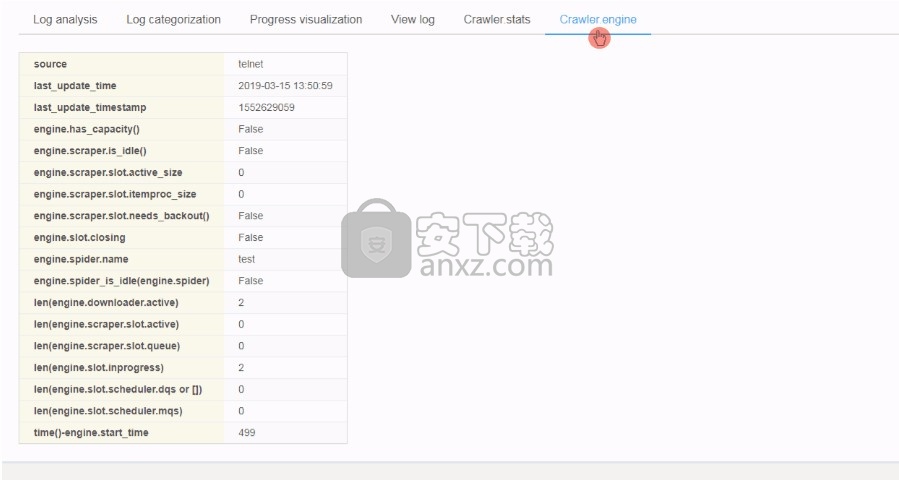
同样,在其余主机上安装并运行LogParser。
如果您使用的是Scrapy 1.5.1和更早版本,则LogParser可以通过Scrapy的内置telnet控制台收集Crawler.stats和Crawler.engine 。
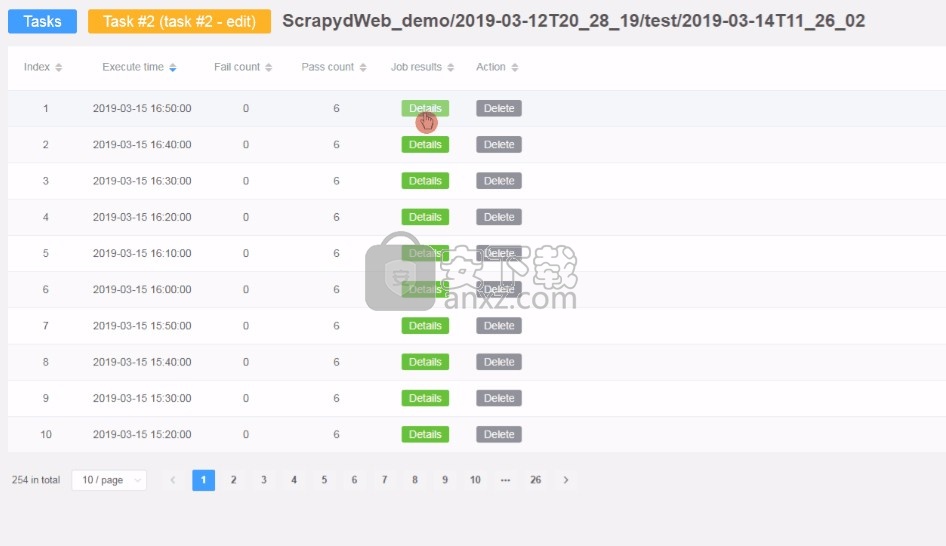
计时器任务
检查任务的参数及其执行结果。
可以自由地暂停,继续,触发,停止,编辑和删除任务。
电邮通知
通过在轮询子过程中定期访问“统计信息”页面,ScrapydWeb可以在满足特定条件时通知您,并发送包含当前作业统计信息的电子邮件。
1、设置您的电子邮件帐户:

2、设置电子邮件工作时间和基本触发条件:
上面的设置意味着当当前时间满足工作日的9点,12点和17点时,将每小时发送一次电子邮件。这也适用于工作完成的情况。

3、除了上面的基本触发器之外,ScrapydWeb 还提供了多种触发器来处理特定类型的日志,包括'CRITICAL','ERROR','WARNING','REDIRECT','RETRY'和'IGNORE'。

上面的设置意味着,如果在Scrapy日志中找到三个或更多关键日志,ScrapydWeb将自动停止当前的抓取作业。如果满足电子邮件工作时间的条件,则会发送一封电子邮件。
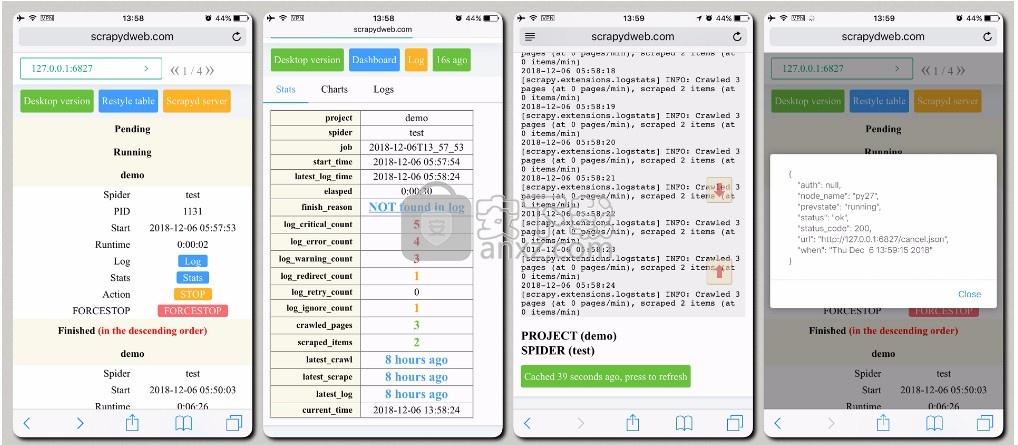
移动UI界面
更新日志
1.4.0(2019-08-16)
新的功能
添加用于通过Slack,Telegram或Email发送文本或警报的API
改进之处
侧边栏和多节点按钮上的UI改进
其他
将配置文件更新为scrapydweb_settings_v10.py
1.3.0(2019-08-04)
新的功能
添加新页面用于汇总作业统计信息的节点报告和集群报告(问题#72)
改进之处
适应于 LogParser v0.8.2
添加DATA_PATH选项以自定义保存程序数据的路径(issue#40)
添加DATABASE_URL选项以支持MySQL或PostgreSQL后端(问题#42)
支持人员在“运行蜘蛛”页面中指定最新版本的Scrapy项目(问题4)
支持在“运行蜘蛛”页面中指定设置和参数的默认值(问题#55)
其他
将配置文件更新为scrapydweb_settings_v9.py
支持CircleCI上的持续集成(CI)
人气软件
-

网站万能信息采集器 8.68 MB
/简体中文 -

找货神器插件(chrome淘宝找货神器插件) 0.02 MB
/简体中文 -

Next FlipBook Maker Pro(HTML5翻页制作软件) 144 MB
/英文 -

自媒体全平台采集助手 2.85 MB
/简体中文 -

12306订票助手.NET版 3.31 MB
/简体中文 -

疯狂的美工阿里巴巴自由布局工具 4.66 MB
/简体中文 -

疯狂的美工在线自由布局工具 5.79 MB
/简体中文 -

万能弹窗广告工具 1.89 MB
/简体中文 -

酒店比价插件(chrome酒店价格比较插件) 0.79 MB
/简体中文 -

网页关键词监控大师 0.82 MB
/简体中文
 后羿采集器 v4.0.1
后羿采集器 v4.0.1  网页模版小偷 V15.0
网页模版小偷 V15.0  Xara Web Designer 15(网页设计软件) 附安装教程
Xara Web Designer 15(网页设计软件) 附安装教程  Oxygen XML Editor 21(XML编辑器) v21.0
Oxygen XML Editor 21(XML编辑器) v21.0  CloudMounter for Windows(云盘本地虚拟工具) v1.0.545
CloudMounter for Windows(云盘本地虚拟工具) v1.0.545  CoffeeCup Web Form Builder(网页表单制作工具) v2.9
CoffeeCup Web Form Builder(网页表单制作工具) v2.9  Xara Web Designer 16(网页设计软件) 附安装教程
Xara Web Designer 16(网页设计软件) 附安装教程 












