织梦采集侠
v2.8 特别版- 软件大小:0.35 MB
- 更新日期:2019-10-29 17:24
- 软件语言:简体中文
- 软件类别:数据库类
- 软件授权:免费版
- 软件官网:待审核
- 适用平台:WinXP, Win7, Win8, Win10, WinAll
- 软件厂商:

软件介绍 人气软件 下载地址
织梦采集侠是一款后台数据采集工具,可以为用户们提供一个自动采集数据的平台,自动采集无需管理员实时操作以及不需要一直盯着程序工作,它是站长们必备的采集工具;使用该程序时,用户只需要将自己需要采集的参数以及其它采集信息输入程序中,系统会根据用户的设定进行工作,可以快速对指定网站中的数据进行采集和添加;支持对文章进行自动采集,它还为用户提供了一个无限制的域名使用功能,此功能主要是让用户可以更好的避免采集次数受限制的困窘;强大又实用,需要的用户可以下载体验
软件功能
1、定向采集,精确采集标题、正文、作者、来源
定向采集只需要提供列表URL和文章URL即可智能采集指定网站或栏目内容,方便简单,编写简单规则便可精确采集标题、正文、作者、来源。
2、 多种伪原创及优化方式,提高收录率及排名
自动标题、段落重排、高级混淆、自动内链、内容过滤、网址过滤、同义词替换、插入seo词语、关键词添加链接等多种方法手段对采集回来的文章加工处理,增强采集文章原创性,利于搜索引擎优化,提高搜索引擎收录、网站权重及关键词排名。
3、插件全自动采集,无需人工干预
织梦采集侠按照预先设定是采集任务,根据所设定的采集方式采集网址,然后自动抓取网页内容,程序通过精确计算分析网页,丢弃掉不是文章内容页的网址,提取出优秀文章内容,最后进行伪原创,导入,生成,这一切操作程序都是全自动完成,无需人工干预。
软件特色
1、一键安装,全自动采集
织梦采集侠安装十分简单方便,只需一分钟,立即开始采集,而且结合简单、健壮、灵活、开源的dedecms程序,新手也能快速上手,而且我们还有专门的客服为商业客户提供技术支持。
2、一词采集,无须编写采集规则
和传统的采集模式不同的是织梦采集侠可以根据用户设定的关键词进行泛采集,泛采集的优势在于通过采集该关键词的不同搜索结果,实现不对指定的一个或几个被采集站点进行采集,减少采集站点被搜索引擎判定为镜像站点被搜索引擎惩罚的危险。
3、RSS采集,输入RSS地址即可采集内容
只要被采集的网站提供RSS订阅地址,即可通过RSS进行采集,只需要输入RSS地址即可方便的 采集到目标网站内容,无需编写采集规则,方便简单。
说明
织梦采集侠采集版分UTF8和GBK两个版本,根据自己使用的dedecms版本来选择!
因文件是用mac系统打包的,会自带_MACOSX、.DS_Store文件,不影响使用,有强迫症的可以删除。覆盖文件的时候不用管这些文件。
1、您自行去采集侠官方下载最新v2.8版本,然后安装到您的织梦后台,如果之前安装过2.7版本,请先删除!
2,注意安装的时候版本千万不要选错了,UTF8就装UTF8,GBK就用GBK的不要混用!
3、覆盖文件(共三个文件CaiJiXia、include和Plugins)
Plugins : 直接覆盖到网站的根目录
include : 直接覆盖到网站的根目录
CaiJiXia: 网站默认后台是dede,如果你没有修改后台目录的话那就是覆盖 /dede/apps/下面,如果后台访问路径被修改过的话,那就把dede换成你修改的名称。例:dede已修改成test, 那就覆盖/test/apps/目录下
4、程序使用对域名无限制
5、覆盖后需要清理下浏览器缓存, 推荐使用谷歌或者火狐浏览器,不要用IE内核浏览器,清理缓存有时清的不干净
6、PHP版本必须5.3+
使用说明
1、设置定向采集
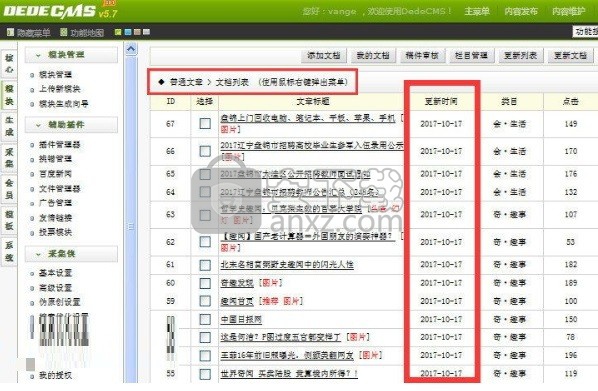
1)、登录您网站后台,模块->采集侠->采集任务,如果您的网站还没有添加栏目,你需要先到织梦的栏目管理里先添加栏目,如果已经添加了栏目,你可能可以看到如下界面
2)、在弹出的页面里选择定向采集,
3)、点击添加采集规则,这就是添加定向采集规则的页面了,这里我们要详细说下
2、设置 目标页面编码
打开您要采集的网页,点击鼠标右键,点击查看网站源码,搜索charset,查看charset后面紧跟的是utf-8还是gb2312,如图所示即为utf-8
3、设置 列表网址
列表网址就是您要采集的网站的栏目列表地址
如果只是单纯采集列表页的第一页,直接输入该列表URL就行,如我要采集站长之家的优化栏目的第一页,那列表URL就输入:http://www.chinaz.com/web/seo/,即可。采集第一页的内容的好处就是可以不用采集老旧的新闻,而且有新更新也可以及时采集到,如果需要采集该栏目的所有内容,那也可以通过设置通配符的方式,匹配所有列表URL规则
。
超级采集
原理:即以采集爬虫的模式对对方网站进行逐层抓取,获取所有符合规则的内容页面
适用对象:对采集内容没有时间排序要求,需要采集大量内容的网站使用!
目标页面编码: >gb2312 >utf8列表url: 要采集的栏目列表,通配符[开始数-结束数],如[1-10]文章url: 列表内文章地址,支持url模糊匹配(*) 和 区域匹配[规则说明]:找出字段内容所在区域,"起始html片段[内容]结尾html片段",如标题规则:
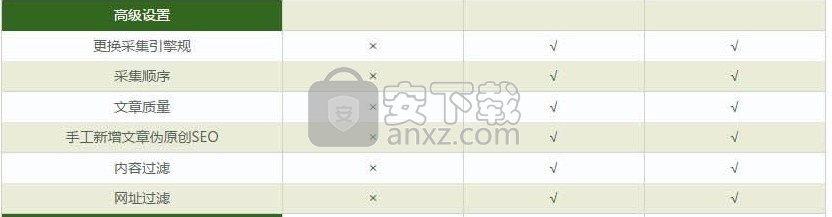
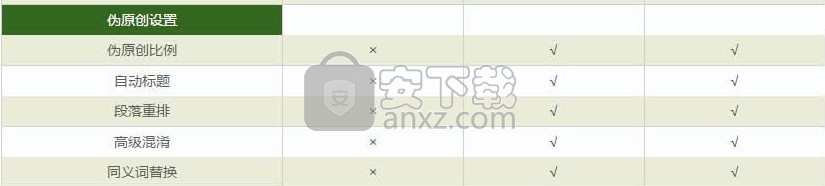
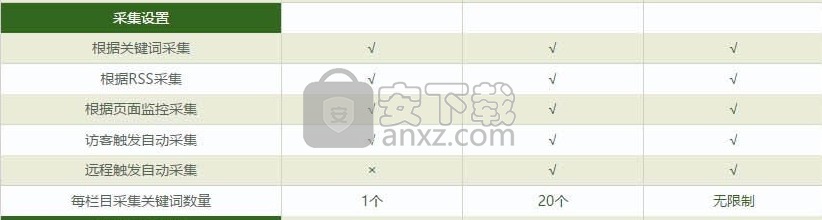
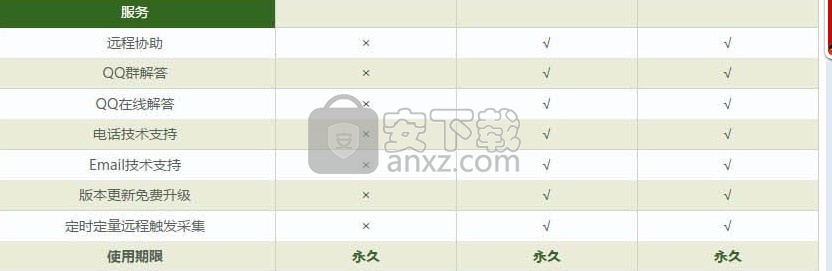
该程序的功能模块比较如下



人气软件
-

PL/SQL Developer(PL/SQL数据库管理软件) 130.1 MB
/简体中文 -

Oracle SQL Developer(oracle数据库开发工具) 382 MB
/简体中文 -

PowerDesigner16.6 32/64位 2939 MB
/简体中文 -

Navicat for MySQL 15中文 72.1 MB
/简体中文 -

Navicat Data Modeler 3中文 101 MB
/简体中文 -

SPSS 22.0中文 774 MB
/多国语言 -

db文件查看器(SQLiteSpy) 1.67 MB
/英文 -

Navicat Premium V9.0.10 简体中文绿色版 13.00 MB
/简体中文 -

Navicat 15 for MongoDB中文 78.1 MB
/简体中文 -

sql prompt 9 12.67 MB
/简体中文
 toad for oracle 绿化版 v12.8.0.49 中文
toad for oracle 绿化版 v12.8.0.49 中文  Aqua Data Studio(数据库开发工具) v16.03
Aqua Data Studio(数据库开发工具) v16.03  dbforge studio 2020 for oracle v4.1.94 Enterprise企业
dbforge studio 2020 for oracle v4.1.94 Enterprise企业  navicat 12 for mongodb 64位/32位中文 v12.1.7 附带安装教程
navicat 12 for mongodb 64位/32位中文 v12.1.7 附带安装教程  SysTools SQL Log Analyzer(sql日志分析工具) v7.0 (附破解教程)
SysTools SQL Log Analyzer(sql日志分析工具) v7.0 (附破解教程)  FileMaker pro 18 Advanced v18.0.1.122 注册激活版
FileMaker pro 18 Advanced v18.0.1.122 注册激活版  E-Code Explorer(易语言反编译工具) v0.86 绿色免费版
E-Code Explorer(易语言反编译工具) v0.86 绿色免费版