InfluxDB(时间序列数据库)
v1.7.11 官方版- 软件大小:11.4 MB
- 更新日期:2021-04-30 09:23
- 软件语言:英文
- 软件类别:数据库类
- 软件授权:免费版
- 软件官网:待审核
- 适用平台:WinXP, Win7, Win8, Win10, WinAll
- 软件厂商:

软件介绍 人气软件 下载地址
InfluxDB是一款时间序列数据库,适合构建物联网使用,您可以通过这款软件管理远程设备,将物联网传感器设备添加到这款数据库使用,可以实时读取数据变化,可以按照时间序列展示数据,将每时每刻设备生成的数据保存在数据库,方便以后在客户端界面显示可视化的数据,例如可以通过这款软件监控天气数据,每天的天气变化数据都可以按照时间序列保存,也可以监控股票数据,股票行情变化按照时间序列号展示,也支持物流数据管理,运输数据实时更新,按照时间变化实时捕捉数据,监控数据,帮助用户更快速构建自己的时间序列数据库,需要就下载吧!
软件功能
nfluxDB是一个时间序列平台
InfluxDB使开发人员能够构建物联网,分析和监控软件。它专门用于处理传感器,应用程序和基础架构所产生的大量和无数个带有时间戳的数据源。
专为开发人员打造
专为增长而设计,具有企业级安全性,允许开发人员在任何地方进行构建:边缘,云,本地。
时间序列数据库
在高性能的时间序列数据库中摄取指标,事件和日志,该数据库每秒可以摄取数百万个数据点。
更快的时间
执行分析以获得更快的检测和解决方案,或者通过简单的单击设置警报或异常检测。
强大的API和工具
使用InfluxDB平台的开发人员可以以更少的精力,更少的代码和更少的配置来构建他们的应用程序。
不受限制的开发人员生产力
客户端和服务器库,包括React,JavaScript,Go,Python等等。
抢先使用模板
每个用例的鼓舞人心的模板。易于创建和共享-找到适合您的内容。
软件特色
为什么要使用InfluxDB
更快的时间变得很棒
InfluxDB通过单一二进制文件的时间序列平台即可满足您的所有需求-多租户时间序列数据库,UI和仪表板工具,后台处理和监视代理。所有这些使部署和设置变得轻而易举,并且更易于保护。
深刻的见解和分析
Flux是第四代编程语言,旨在用于数据脚本,ETL,监视和警报。作为一种功能语言,您可以构建查询并将通用逻辑分离为易于共享并有助于加快开发速度的函数和库。Flux还可以用于与其他SQL数据存储库(Postgres,Microsoft SQL Server,SQLite和SAP Hana)以及基于云的数据存储库(Google Bigtable,Amazon Athena和Snowflake)一起充实您的时间序列数据。丰富的时间序列数据提供了可以进一步深入了解您的数据的上下文。
优化开发人员的生产力
现在,可以在统一的API中访问InfluxDB中的所有内容(提取,查询,存储和可视化)。因为现在可以通过编程方式访问和控制平台中的所有内容,所以这使开发人员能够更快地获得出色的表现。这与跨10种语言(例如Go,Java,PHP和Python)的一组强大的客户端库结合在一起,并且一组InfluxDB命令行工具可帮助开发人员以最熟悉的方式进行开发。
从UI开始
InfluxDB具有一流的UI,其中包括Data Explorer,仪表板工具和脚本编辑器。使用数据资源管理器快速浏览收集的指标和事件数据,并应用常见的转换。仪表板工具随附了方便的可视化列表,可帮助您更快地从数据中查看见解。最后,使用脚本编辑器通过易于访问的示例,自动完成和实时语法检查来快速学习Flux。
易于构建,易于共享的模板
InfluxDB模板(一套新工具,其中包括打包程序和一套预制的监控解决方案)使您可以与全世界的同事和其他社区成员共享监控专业知识。InfluxDB模板库提供了可用的模板,这些模板涵盖了一些最流行的工具,应用程序和协议。还可以将这些模板作为代码检入,以适合您的持续集成和部署管道,以使部署(更重要的是回滚)更改轻松进行。
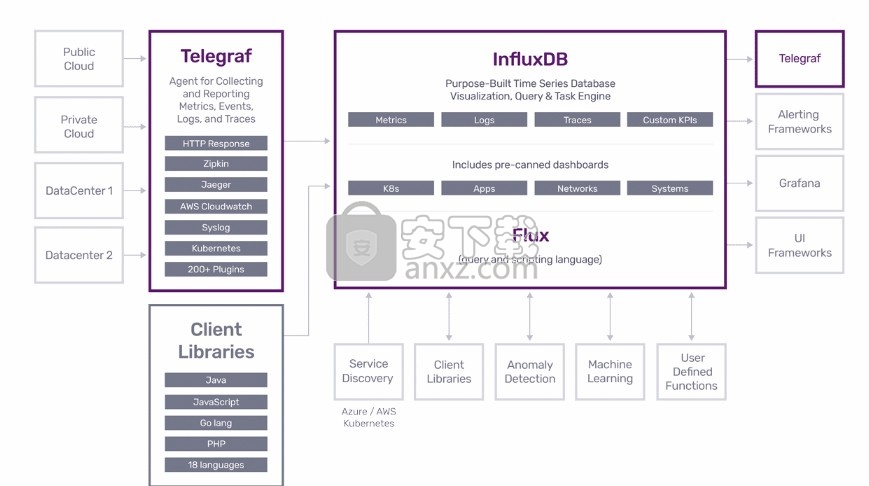
软件优势
InfluxDB是从头开始构建的,是专用的时间序列数据库。即,没有将其重新设定为时间序列。时间从一开始就是内置的。InfluxDB是全面平台的一部分,该平台支持时间序列数据的收集,存储,监视,可视化和警报。它不仅仅是一个时间序列数据库。
InfluxDB数据模型与其他时间序列解决方案(如Graphite,RRD或OpenTSDB)完全不同。InfluxDB具有用于发送时间序列数据的线路协议,其格式如下:measurement-name tag-set field-set timestamp。度量名称是一个字符串,标记集是键/值对的集合,其中所有值都是字符串,而字段集是键/值对的集合,其中值可以是int64,float64,bool或string。测量名称和标签集保存在倒排索引中,这可以非常快速地查找特定系列。例如,如果我们有CPU指标:
cpu,host=serverA,region=uswest idle=23,user=42,system=12 1464623548s
InfluxDB中的时间戳可以是秒,毫秒,微秒或纳秒精度。微纳级刻度使InfluxDB成为金融和科学计算用例的理想选择,而其他解决方案将被排除在外。压缩是可变的,具体取决于用户所需的精度水平。在磁盘上,数据以柱状样式格式组织,其中为测量,标签集,字段设置了连续的时间块。因此,每个字段在磁盘上按时间顺序进行组织,这使得在单个字段上计算聚合非常快速。可以使用的标签和字段的数量没有限制。
其他时间序列解决方案不支持多个字段,当使用共享标签集传输数据时,这会使它们的网络协议变得肿。大多数其他时间序列解决方案仅支持float64值,这意味着用户无法随时间序列一起编码其他元数据。甚至支持标签(与Graphite和RRD不同)的OpenTSDB和KairosDB都对可使用的标签数量有所限制。在大约5到6个标签处,用户将开始看到其HBase或Cassandra计算机集群中的热点。
InfluxDB没有此限制,因为InfluxDB数据模型是专门为时间序列设计的。它通过索引标签并使字段保持未索引的方式,将开发人员推向正确的方向,以从数据库中获得良好的性能。它的灵活性在于它支持许多数据类型,并且用户可以具有许多字段和标签。由于所有这些因素,像InfluxDB这样的专用时间序列数据库是处理时间序列数据的最佳解决方案。
使用说明
时间序列数据是通过一段时间内重复测量获得的观测值的集合。将点绘制在图形上,其中一个轴将始终是时间。
时间序列数据无处不在,因为时间是所有可观察到的事物的组成部分。随着我们对世界的仪器化程度越来越高,传感器和系统不断地发出无休止的时间序列数据流。这样的数据在各个行业中都有大量应用。让我们通过一些示例将其放在上下文中。
时间序列数据可用于:
跟踪每日,每小时或每周的天气数据
跟踪应用程序性能的变化
医疗设备实时可视化生命体征
跟踪网络日志
以下是一些时间序列数据的详细示例。
时间序列示例
气象记录,经济指标和患者健康发展指标-均为时间序列数据。时间序列数据还可以是服务器指标,应用程序性能监视,网络数据,传感器数据,事件,点击和许多其他类型的分析数据。
请注意,时间(如下图底部所示)是轴。
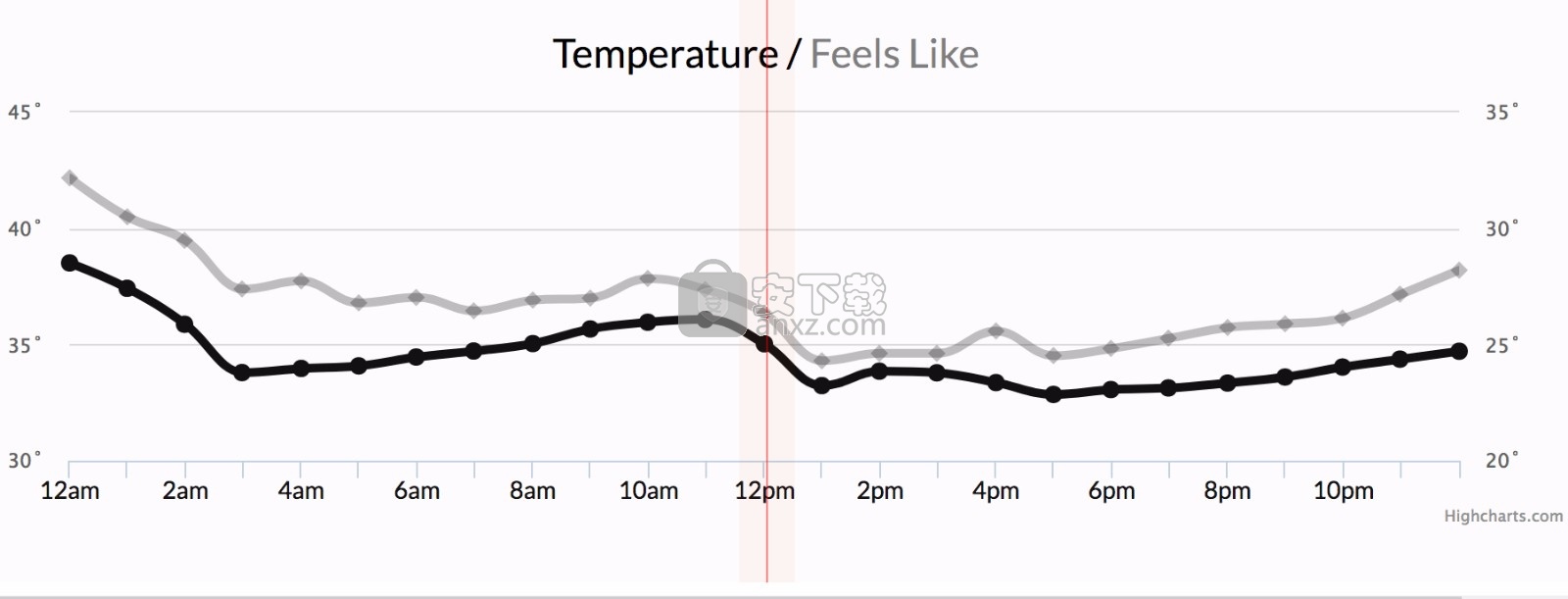
示例1:天气情况
在下面的下一张图表中,请注意时间作为衡量股价变化的轴。在投资中,时间序列会跟踪数据点的移动,例如指定时间段内有价证券的价格,并定期记录数据点。可以在短期(例如,一个工作日内每小时的证券价格)或长期(例如在五年中的每个月的最后一天收盘价)上进行追踪)。
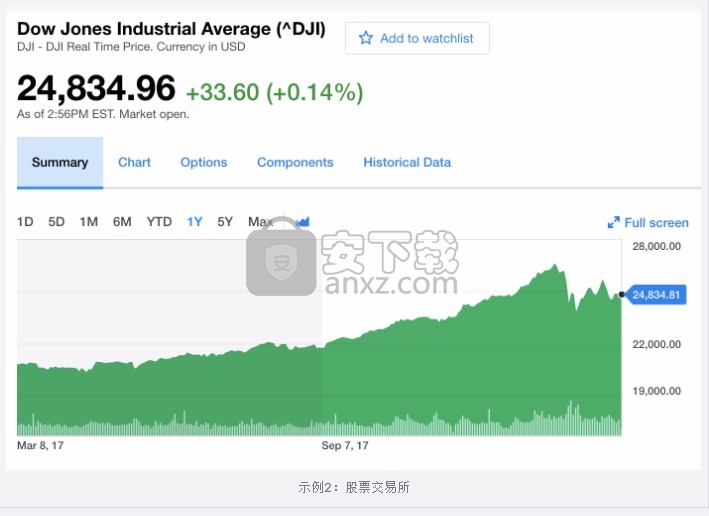
示例2:股票交易所
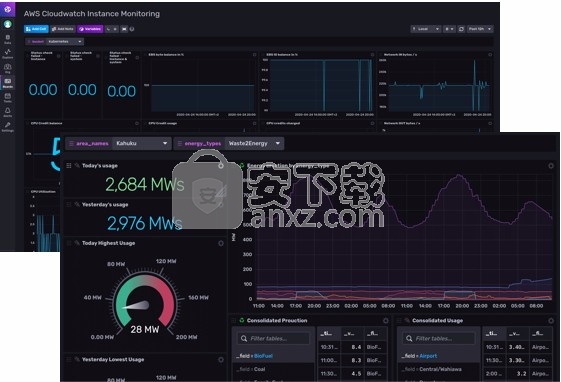
下面的群集监视示例描述了磁盘操作的写入和使用情况数据,这是Network Operation Center团队所熟悉的。请记住,监视数据是时间序列数据。
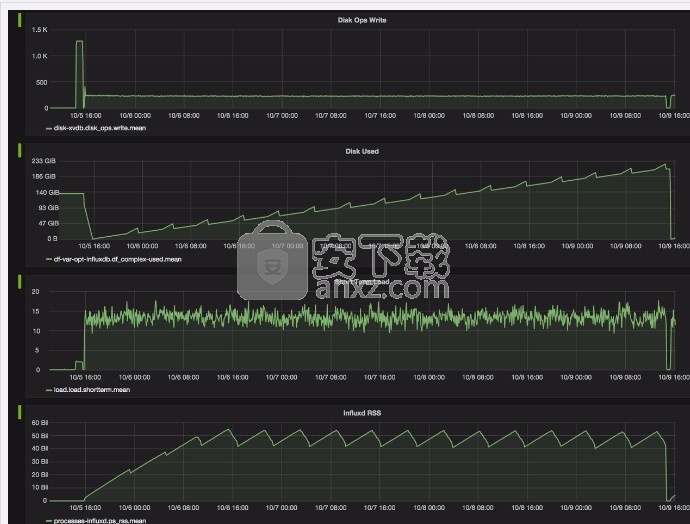
示例3:群集监视
时间序列数据的另一个常见示例是患者健康监测,例如心电图(ECG),它可以监测心脏的活动以显示其是否正常工作。
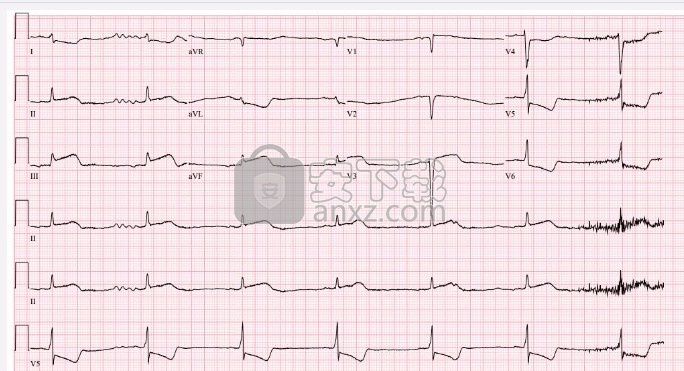
示例4:健康监控
除了按固定的时间间隔捕获之外,还可以随时捕获时间序列数据,无论时间间隔如何,例如在日志中。日志是事件,进程,消息以及软件应用程序与操作系统之间的通信的注册表。每个可执行文件都会生成一个日志文件,其中记录了所有活动。日志数据是分类和解决问题的重要上下文资源。例如,在联网中,事件日志有助于提供有关网络流量,使用情况和其他条件的信息。
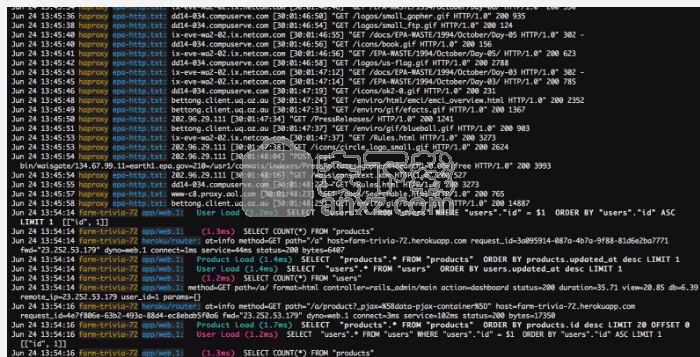
示例5:日志
跟踪(应用程序在执行过程中执行的子例程调用的列表)也是时间序列数据。在下面的跟踪图中的彩色带上,您可以看到时间序列数据的示例。跟踪的目的是跟踪程序的流程和数据进度。跟踪包含对应用程序的广泛,连续的视图,以查找程序或应用程序中的错误。
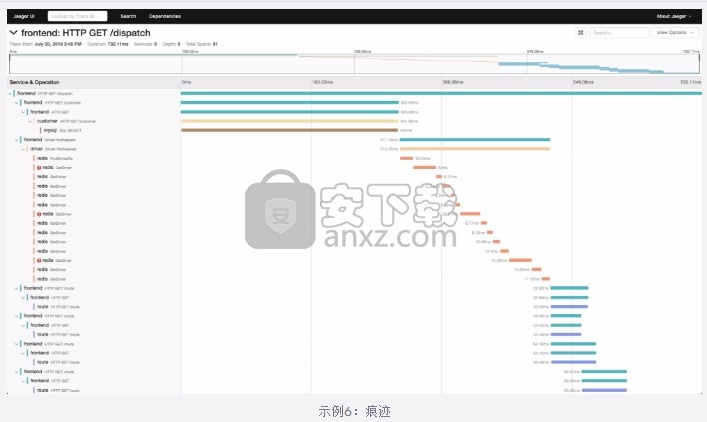
示例6:痕迹
上面的示例包含两种不同类型的时间序列数据,如下所述。时间序列数据的类型时间序列数据可以分为两种类型:
1、以固定的时间间隔收集度量(度量标准)
2、以不规则的时间间隔(事件)收集测量结果
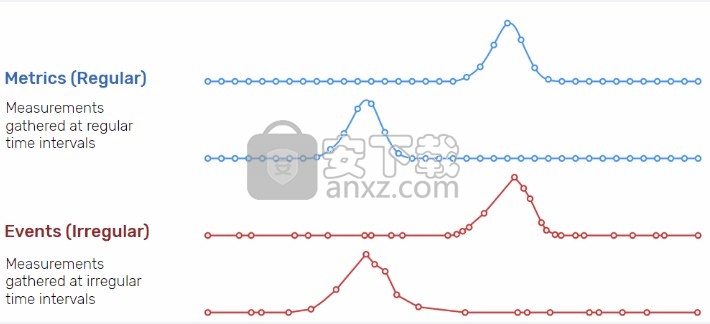
在上面的“时间序列数据示例”部分中:
示例3(集群监视)和示例4(运行状况监视)描述了 指标。
示例5(日志)和6(跟踪)描述了 事件。
因为事件以不规则的间隔发生,所以事件是不可预测的,因此无法建模或预测,因为预测假设过去发生的任何事情都可以很好地指示将来发生的事情。
线性与非线性时间序列数据
线性时间序列是一个线性时间序列,其中对于每个数据点X t,该数据点都可以视为过去或将来的值或差异的线性组合。非线性时间序列是由非线性动力学方程生成的。它们具有无法通过线性过程建模的特征:时变方差,不对称循环,更高矩的结构,阈值和中断。使用线性和非线性时间序列数据时,有一些重要的注意事项:
如果回归方程不遵循线性模型的规则,则它必须是非线性模型。
非线性回归可以拟合各种曲线。
两种模型的定义特征是功能形式。
识别时间序列数据时间序列数据 的独特之处在于它具有自然的时间顺序:观察数据的顺序很重要。时间序列数据与常规数据的主要区别在于,随着时间的推移,您总是会提出有关它的问题。确定您正在使用的数据集是否为时间序列的一种通常简单的方法是查看您的坐标轴是否为时间。
时间序列注意事项
不变性 –由于时间序列数据按时间顺序排列,因此几乎总是将其记录在新条目中,因此,它应该是不变的,并且只能追加(附加到现有数据中)。它通常不会更改,而是按照事件发生的顺序进行处理。此属性将时间序列数据与通常是易变的关系数据区分开来,并存储在进行在线事务处理的关系数据库中,在此关系数据库中,行随着事务的运行而更新,或多或少地随机更新。例如,以一个现有客户的订单为例,更新客户表以添加已购买的项目,还更新库存表以显示它们不再可供出售。
时间序列数据是有序的,这使得它在数据空间中是唯一的,因为它经常显示出序列依赖性。当某个时间点的数据点的统计值在另一时间统计地依赖于另一个数据点时,就会发生串行依赖性(有关此主题的详细说明,请阅读“时序数据中的自相关”)。
尽管没有时间以外的事件存在,但也有一些时间与时间无关的事件。时间序列数据不仅涉及按时间顺序发生的事情,还涉及将时间添加为轴时其价值增加的事件。时间序列数据有时会以较高的粒度级别存在,频率通常为微秒或什至纳秒。有了 时间序列数据,随时间变化就是一切。
时间序列数据的不同形式 –时间序列数据并不总是数字的-它可以是int64,float64,bool或string。时间序列数据与横截面和面板数据要确定您的数据是否为时间序列数据,请确定在数据集中确定唯一记录所需的条件。
如果您只需要一个时间戳,则可能是时间序列数据。
如果您需要除时间戳之外的其他内容,则可能是横截面数据。
如果您需要时间戳以及其他内容(例如ID),则可能是面板数据。
回顾以下三种数据类型中的每一种的定义(以及它们之间的区别),上述含义将变得更加清楚
官方教程
开始使用InfluxDB任务
一个InfluxDB任务是预定流量脚本,需要输入数据,修改流或分析它以某种方式,然后存储在一个新的桶或执行其他操作修改的数据。
本文逐步编写了一个基本的InfluxDB任务,该任务对数据进行降采样并将其存储在新的存储桶中。
任务的组成部分
每个InfluxDB任务都需要以下四个组件。它们的形式和顺序可以变化,但是它们都是任务的重要组成部分。
任务选项
资料来源
数据处理或转换
目的地
定义任务选项
任务选项定义有关任务的特定信息。以下示例说明了如何在Flux脚本中定义任务选项:

InfluxDB用户界面(UI)中创建任务时,任务选项在表单字段中定义。
定义数据源
使用Fluxfrom()函数 或任何其他Flux输入函数定义数据源。
为方便起见,请考虑创建一个变量,该变量包括具有所需时间范围的源数据和任何相关过滤器。

在Flux脚本中使用任务选项
任务选项作为task选项记录的一部分传递,可以在您的Flux脚本中引用。在上面的示例中,时间范围定义为-task.every。
task.every是点符号,它引用every了task选项记录的属性。 every定义为1h,因此-task.every等于-1h。
使用任务选项在Flux脚本中定义值可以使重用任务更加容易。
处理或转换您的数据
任务的目的是以某种方式处理或转换数据。具体发生什么以及输出数据采用什么形式取决于您和您的特定用例。
考虑带有偏移量的潜在数据
要考虑潜在数据(例如来自边缘设备的数据流),请在任务中使用偏移量。例如,如果您使用选项every: 1h和将小时任务间隔设置为小时,则offset: 5m任务将在任务间隔后5分钟执行,但查询now()时间以确切的小时为单位。
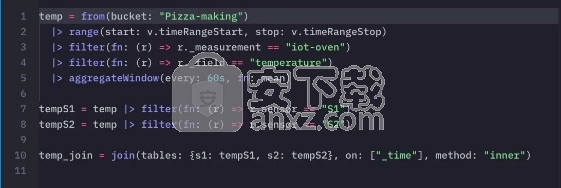
下面的示例说明了通过计算设置间隔的平均值对数据进行下采样的任务。它使用上面data定义的变量作为数据源。然后,将数据分成5分钟的间隔,并使用函数计算每个窗口的平均值。aggregateWindow()

定义目的地
在绝大多数任务用例中,数据一旦转换,就需要发送并存储在某个地方。这可以是一个单独的存储桶或其他度量。
以下示例使用Fluxto()函数 将转换后的数据发送到另一个存储桶:

为了将数据写入InfluxDB,你必须有_time,_measurement,_field,和_value列。
完整的示例任务脚本
下面是一个任务脚本,其中包含上述所有组件:

创建一个任务
InfluxDB提供了多种在InfluxDB用户界面(UI)和influx命令行界面(CLI)中创建任务的方式。
从数据资源管理器创建任务
1、在左侧的导航菜单中,选择浏览(Data Explorer)。

2、生成查询,然后单击右上角的“另存为”。
3、选择任务选项。
4、指定任务选项。 有关每个选项的详细信息,请参见任务选项。
5、从令牌下拉列表中选择要使用的令牌。
6、单击另存为任务。
在任务界面中创建任务
1、在左侧的导航菜单中,选择任务。
2、点击 在右上方创建任务。
3、选择新建任务。
4、在左侧面板中,指定任务选项。有关每个选项的详细信息,请参见任务选项。
5、从令牌下拉列表中选择要使用的令牌。
6、在右侧面板中,输入您的任务脚本。
省略选项任务分配
在InfluxDB任务UI中创建新任务时,请忽略option task 定义任务选项的分配。 保存任务时,InfluxDB UI使用左侧面板中“任务选项”字段中指定的设置注入此代码。
7、点击右上角的保存。
导入任务
1、在左侧的导航菜单中,选择任务。
2、点击右上角的+创建任务。
3、选择导入任务。
4、使用以下选项之一上传JSON任务文件:
5、将JSON任务文件拖放到指定区域中。
6、点击上传,然后从文件管理器中选择JSON任务区域。
7、选择JSON选项,然后粘贴原始任务JSON。
8、点击导入JSON作为Task。
从模板创建任务
1、在左侧的导航菜单中,选择设置>模板。

2、选择模板。
3、将鼠标悬停在模板上以用于创建任务,然后点击创建。
克隆任务
1、在左侧的导航菜单中,选择任务。
2、将鼠标悬停在要克隆的任务上,然后单击 出现的图标。
3、单击克隆。
使用Influx CLI创建任务
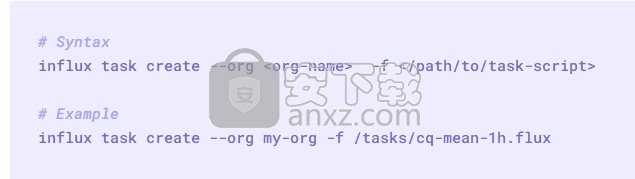
使用influx task create命令创建新任务。它接受文件路径或原始Flux。
使用文件创建任务
使用原始Flux创建任务

人气软件
-

PL/SQL Developer(PL/SQL数据库管理软件) 130.1 MB
/简体中文 -

Oracle SQL Developer(oracle数据库开发工具) 382 MB
/简体中文 -

PowerDesigner16.6 32/64位 2939 MB
/简体中文 -

Navicat for MySQL 15中文 72.1 MB
/简体中文 -

Navicat Data Modeler 3中文 101 MB
/简体中文 -

SPSS 22.0中文 774 MB
/多国语言 -

db文件查看器(SQLiteSpy) 1.67 MB
/英文 -

Navicat Premium V9.0.10 简体中文绿色版 13.00 MB
/简体中文 -

Navicat 15 for MongoDB中文 78.1 MB
/简体中文 -

sql prompt 9 12.67 MB
/简体中文
 toad for oracle 绿化版 v12.8.0.49 中文
toad for oracle 绿化版 v12.8.0.49 中文  Aqua Data Studio(数据库开发工具) v16.03
Aqua Data Studio(数据库开发工具) v16.03  dbforge studio 2020 for oracle v4.1.94 Enterprise企业
dbforge studio 2020 for oracle v4.1.94 Enterprise企业  navicat 12 for mongodb 64位/32位中文 v12.1.7 附带安装教程
navicat 12 for mongodb 64位/32位中文 v12.1.7 附带安装教程  SysTools SQL Log Analyzer(sql日志分析工具) v7.0 (附破解教程)
SysTools SQL Log Analyzer(sql日志分析工具) v7.0 (附破解教程)  FileMaker pro 18 Advanced v18.0.1.122 注册激活版
FileMaker pro 18 Advanced v18.0.1.122 注册激活版  E-Code Explorer(易语言反编译工具) v0.86 绿色免费版
E-Code Explorer(易语言反编译工具) v0.86 绿色免费版