

Tablesaw(数据科学可视化库)
v0.38.1 官方版- 软件大小:15.7 MB
- 更新日期:2021-04-19 11:57
- 软件语言:英文
- 软件类别:信息管理
- 软件授权:免费版
- 软件官网:待审核
- 适用平台:WinXP, Win7, Win8, Win10, WinAll
- 软件厂商:

软件介绍 人气软件 下载地址
Tablesaw提供数据分析和统计功能,可以通过这款软件建立多种统计表分析数据,支持偏度,峰值、中位数、乘积、平均值等多种数据统计分析功能,让用户在分析科学数据的时候获得可视化的图形统计结果,您可以直接从本地导入数据到软件分析,也可以将数据库的内容添加到Tablesaw分析,可以对表格数据排序,可以对表格数据筛选,可以使用逻辑运算符and,or,not来组合查询过滤器;Tablesaw结合了用于处理表和列的工具,并具有创建统计模型和可视化效果的能力,其中每一列都包含一个数据类型,而行可以包含多种类型,为用户可视化科学数据提供更多帮助,如果你需要这款软件就下载吧!

软件功能
Tablesaw是用于数据科学的Java。它包括一个数据框和一个可视化库,以及用于加载,转换,过滤和汇总数据的实用程序。记忆快速而谨慎。如果您使用Java处理数据,则可以节省您的时间和精力。Tablesaw还支持描述性统计,并与Smile机器学习库很好地集成。
Tablesaw功能:
数据处理与转换
从RDBMS,Excel,CSV,JSON,HTML或固定宽度文本文件导入数据,无论这些文件是本地文件还是远程文件(http,S3等)
将数据导出到CSV,JSON,HTML或固定宽度文件。
通过追加或合并表
添加和删除列或行
排序,分组,查询
映射/归约运算
处理缺失值
软件特色
可视化
Tablesaw通过为Plot.ly JavaScript绘图库提供包装器来支持数据可视化。
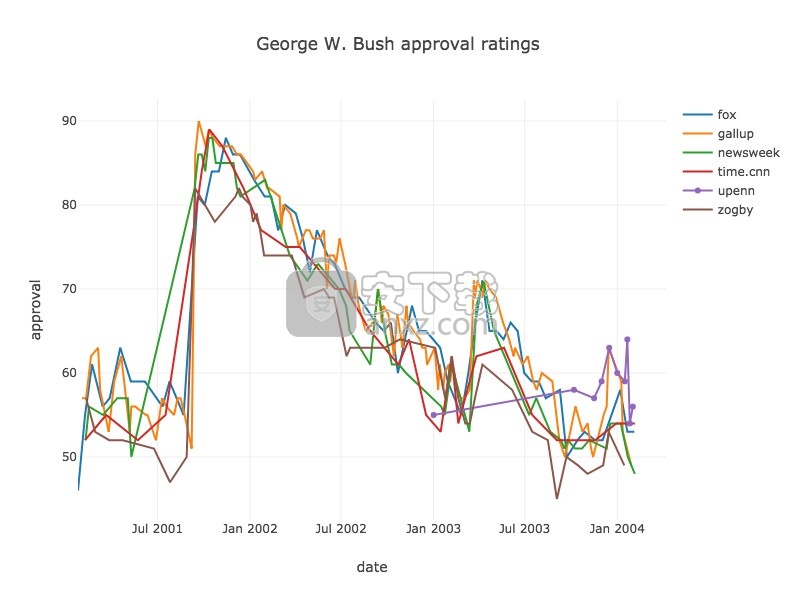
统计数据
描述性统计:平均值,最小值,最大值,中位数,总和,乘积,标准差,方差,百分位数,几何平均值,偏度,峰度等。

官方教程
Tablesaw入门
Java是一种很棒的语言,但是它并不是为数据分析而设计的。通过Tablesaw,可以轻松地使用Java进行数据分析。
本教程将帮助您入门和运行,并介绍Tablesaw的一些基本功能。
设置
首先,Tableasaw需要Java 8或更高版本。
其次,您需要将依赖项添加到pom文件中。它在Maven Central上可用。
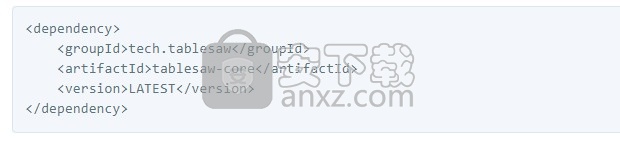
设置完毕就可以了。上设计
表和列
如您所料,Tablesaw完全是关于表的,而表是由列组成的。我们将从列开始。
列
列是命名的一维数据集合。它可能是表的一部分,也可能不是。列中的所有数据必须具有相同的类型。
Tablesaw支持以下列:字符串,浮点数,双精度数,整数,短裤,多头,布尔值,LocalDates,LocalTimes,Instant和LocalDateTimes。日期和时间列与Java 8中引入的java.time类具有可比性。
要创建列,可以使用其静态create()方法之一:
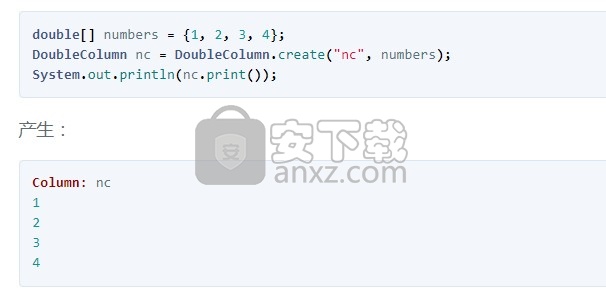
每列都有一个关联的基于0的索引。要获取单个值,请调用带有索引的get()。
double three = nc.get(2);
返回3.0。
阵列运算
Tablesaw使列易于使用。例如,在标准Java中处理数字的操作通常在Tablesaw中处理数字列。要将一列中的每个值乘以4,我们使用乘法()方法,该方法将返回一个与原始列相同的新列。

如您所见,这些值是原始值的4倍。新列的名称是通过合并原始“ Test”和操作(* 4)而得到的。如果您喜欢使用,可以更改它setName(aString)。
通常,Tablesaw中有许多列式操作,因此,如果发现自己编写了一个for循环来处理列或表,则可能会丢失某些内容。
对象和基元
许多Java程序和程序员仅使用对象,而不使用基元。在Tablesaw,因为他们使用我们经常使用的原语多比盒装的选择更少的内存。例如,即使字节的范围只有256个值,但Byte对象使用的内存与原始double一样多。
这种节俭是有代价的。使用原语时,您会放弃一些常见的Java功能,例如使用标准Java 8谓词。尽管Java深思熟虑地提供了一些专门的谓词接口(例如IntPredicate),但它们没有提供任何原始BiPredicate实现,它们的原始接口也没有涵盖所有原始类型。没有IntBiPredicate,我们将无法实现
这仅涵盖有关列的最基本信息。您可以在“列”部分中找到更多信息,或者在api包 和columns包的Javadocs中 找到更多信息 。
选择项
在上表之前,我们应该谈谈选择。选择用于过滤表和列。它们通常在后台运行,但是您可以直接使用它们。例如,考虑我们DoubleColumn包含值{1、2、3、4}。您可以通过发送消息来过滤该列。例如:
nc.isLessThan(3);
此操作返回Selection。从逻辑上讲,它是与原始列相同大小的位图。上面的方法有效地返回1、1、0、0,因为该列中的前两个值小于3,而后两个值则不是。
您可能想要的不是Selection对象,而是一个DoubleColumn仅包含通过过滤器的值的新对象。为此,您可以使用where(aSelection)方法来应用选择:
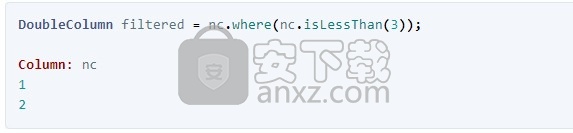
分两步执行此操作可带来许多好处。首先,它使我们可以组合过滤器。例如:
DoubleColumn filteredPositive = nc.where(nc.isLessThan(3).and(nc.isPositive()));
如果方法直接返回列,则无法通过这种方式将它们组合在一起。这也使我们可以使用相同的方法来过滤表和列,如下所示。
按索引选择
这些示例说明了如何使用谓词进行选择。您还可以使用选择来检索一个或多个特定索引处的值。以下两项均受支持:

如果您有几列的长度与数据表中的长度相同,则可以选择其中一列,然后使用它来过滤另一列:

重点:请注意方法startsWith(aString),isLessThan(aNumber)和isPositive()。这些是预定义的供您使用。有许多此类方法可用于构建查询。对于StringColumn,它们是在tech.tablesaw.columns.strings.StringFilters接口中定义的 。它还包括endsWith(),isEmpty(),isAlpha(),containsString()1等。每列都有一组相似的过滤器操作。它们都可以在位于tech.tablesaw.columns子文件夹中的过滤器接口中找到(例如,tech.tablesaw.columns.dates.DateFilters)。
地图功能
映射函数是在列上定义的方法,这些方法返回新的Columns作为结果。您已经看到一个:上面的column乘法(aNumber)方法是带有标量参数的映射函数。要在两列中乘以多个值,请使用乘法(aNumberColumn):

nc1列中的每个值都乘以nc2中的对应值,而不是前面示例中的标量值。
各种列类型都有许多内置的映射函数。以下是StringColumn的一些示例:
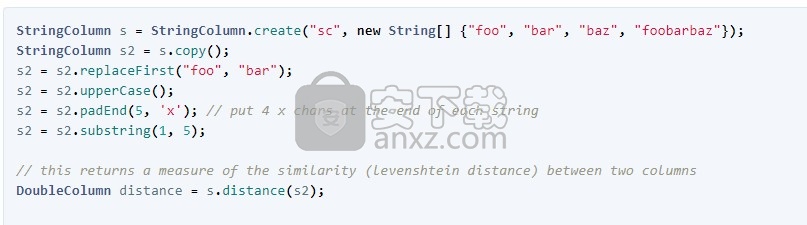
如您所见,对于许多返回新String的String方法。StringColumn提供了一个等效的映射方法,该方法返回一个新的StringColumn。它还包括在Guava的String库和Apache Commons String库中找到的其他有用的方法。
关键点:每个列类型都有一组映射操作,例如乘法(aNumber)。对于StringColumn,这些方法在tech.tablesaw.columns.strings.StringMapFunctions接口中定义。除了上面显示的方法以外,它还包括许多方法。所有列类型的方法都可以在位于tech.tablesaw.columns的子文件夹的过滤器界面中找到(如tech.tablesaw.columns.dates.DateMapFunctions,它提供了最新的方法,如plusDays(ANINT) ,年()和month())。
减少(汇总)功能:汇总一列
有时您想要导出一个值,该值在某种意义上总结了列中的数据。聚合函数就是这样做的。每个这样的函数都会扫描列中的所有值,并作为结果返回单个标量值。所有列都支持一些聚合函数:min()和max(),例如plus plus (),countUnique()和countMissing()。有些还支持特定于类型的功能。BooleanColumn,例如,支持所有() ,它返回真,如果在所有的列中的值是真。函数any()和none(),如果该列中的值分别为true或不为true,则返回true。函数countTrue()和countFalse()也可用。
NumberColumn具有更多的聚合函数。例如,要计算列中值的标准偏差,应调用:
double stdDev = nc.standardDeviation();
关键点: NumberColumn支持许多聚合功能,包括许多最有用的功能。其中可用的总和,计数,平均值,中位数,百分位数(n),范围,方差,sumOfLogs等。这些在NumericColumn类中定义。
当我们讨论下表时,我们将展示如何通过一个或多个分组列中的值来计算一个或多个数字列中的小计。
表
表是列的命名集合。尽管允许缺少值,但表中的所有列都必须具有相同数量的元素。一个表可以包含列类型的任何组合。
建立表格
您可以用代码创建一个表。在这里,我们创建一个表并向其中添加两个新列:

汇入资料
更常见的是,您将从CSV或其他带分隔符的文本文件中加载表格。
Table bushTable = Table.read().csv("../data/bush.csv");
Tablesaw在猜测许多数据集的列类型方面做得很好,但是如果您猜错了,或者可以提高性能,则可以指定它们。还有许多其他选项可用,例如指定是否有标头,使用非标准定界符,提供自定义缺失值指示符等等。
注意:加载数据有时是数据分析中最难的部分。有关导入数据的文档中介绍了用于加载数据的高级选项。该部分还显示了如何从数据库,流或HTML表读取数据。流接口使您可以从网站或S3存储桶读取数据。
探索表
由于Tablesaw擅长处理表,因此我们会尽可能使用它们。当您向tableaw请求一个表的结构时,答案会以另一张表的形式返回,其中一个列包含列名,等等。方法structure(), shape(), first(n), and last(n)可以帮助您了解新的数据集。这里有些例子。

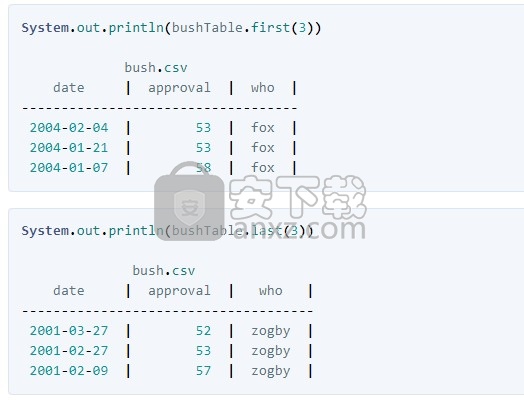
Table的toString()方法返回类似上面所示的String表示形式。默认情况下,它返回有限的行数,但是您也可以使用table.printAll()或table.print(n)来获取所需的输出。
当然,这仅仅是探索性数据分析的开始。您还可以使用数字和可视工具来浏览数据。这些工具分别在有关统计数据和绘图的文档中进行了描述 。
处理表的列
通常,您将使用表中的特定列。以下是一些有用的方法:
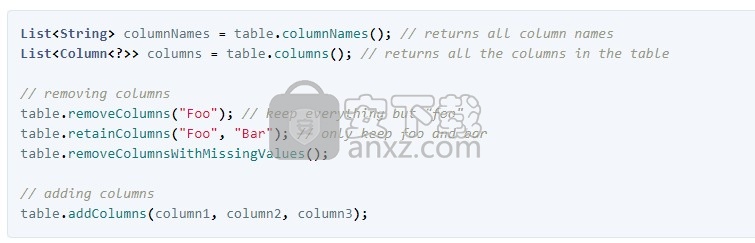
在tablesaw中,列名不区分大小写。如果您要求以下任何一项,则您将获得同一列:

记住列名就足够了,而不必确切地记住哪个字符要大写。
从表中获取特定的列类型
可以按名称或位置从表中检索列。最简单的方法column()返回Column类型的对象。这可能已经足够好了,但是通常您希望获得特定类型的列。例如,您需要将返回的值强制转换为NumberColumn才能在散点图中使用其值。

当变量类型为“列”时,它仅提供所有列均可用的方法。您不能执行数学运算或直接在Column类型上进行字符串替换。如果需要StringColumn,则可以强制转换该列,例如:
StringColumn sc = (StringColumn) table.column(0);
表还支持直接返回所需类型的列的方法:
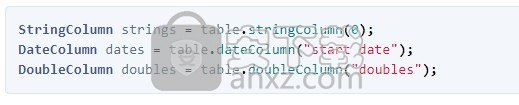
关键点:您可能希望使用特定类型的列。使用标准column()方法并转换结果,或使用为您处理转换的特定于类型的方法之一(例如numberColumn())。还有一些方法或获取特定类型的列。
处理行
与列一样,存在许多以行方式处理表的选项。这里有一些有用的:
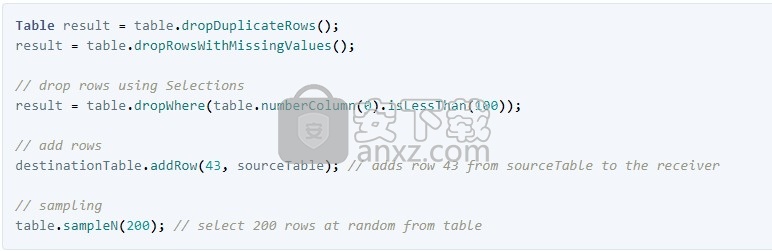
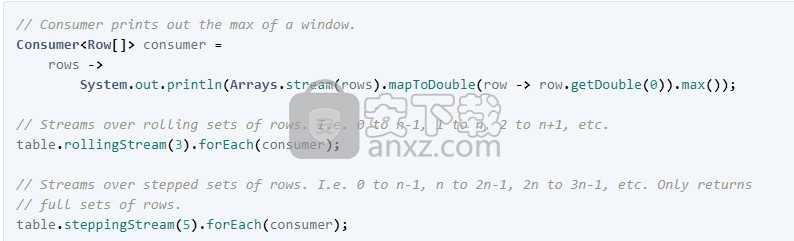
您还可以对表中的每一行执行任意操作。一种方法是仅遍历行并分别处理每一列。

另一种方法使您可以跳过迭代,而只为每一行提供一个使用者。

如果您一次需要处理多个行,则有几种方法可以提供帮助。
更新日志
特点
创建气泡图的更多选项 (#781) - 谢谢 @rayeaster
错误修复
修复对java.sql.Time的支持 (#791) - 感谢 @brainbytes42。
允许在聚合时使用空切片 (#795) - 谢谢 @emillynge
修正ColumnType.compare中的NPE(#799)
修正集的NPE(#800)
人气软件
-

endnote x9.1中文版下载 107.0 MB
/简体中文 -

Canon IJ Scan Utility(多功能扫描仪管理工具) 61.55 MB
/英文 -

A+客户端(房源管理系统) 49.6 MB
/简体中文 -

第二代居民身份证读卡软件 4.25 MB
/简体中文 -

船讯网船舶动态查询系统 0 MB
/简体中文 -

ZennoPoster(自动化脚本采集/注册/发布工具) 596.65 MB
/英文 -

中兴zte td lte 18.9 MB
/简体中文 -

originpro 2021 527 MB
/英文 -

个人信息管理软件(AllMyNotes Organizer) 5.23 MB
/简体中文 -

ZKTeco居民身份证阅读软件 76.2 MB
/简体中文
 有道云笔记 8.0.70
有道云笔记 8.0.70  Efficient Efficcess Pro(个人信息管理软件) v5.60.555 免费版
Efficient Efficcess Pro(个人信息管理软件) v5.60.555 免费版  originpro8中文 附安装教程
originpro8中文 附安装教程  鸿飞日记本 2009
鸿飞日记本 2009  竞价批量查排名 v2020.7.15 官方版
竞价批量查排名 v2020.7.15 官方版  Scratchboard(信息组织管理软件) v30.0
Scratchboard(信息组织管理软件) v30.0  Fitness Manager(俱乐部管理软件) v9.9.9.0
Fitness Manager(俱乐部管理软件) v9.9.9.0 









