

PyTorch(神经网络计算)
v1.8.1 官方版- 软件大小:18.0 MB
- 更新日期:2021-03-30 16:56
- 软件语言:英文
- 软件类别:信息管理
- 软件授权:免费版
- 软件官网:待审核
- 适用平台:WinXP, Win7, Win8, Win10, WinAll
- 软件厂商:

软件介绍 人气软件 下载地址
PyTorch提供神经网络分析功能,您可以使用多个类模快创建分析方案,您可以在软件上编辑分析代码,通过执行代码的方式分析项目,让软件自动对复杂的服务器、系统、程序进行分析,软件提供强大的计算能力,可以帮助企业分析大型神经网络项目,结合分布式的训练系统可以优化计算流程,让项目计算速度更加快速;PyTorch允许您创建数据模型分析,分析完毕的模型可以在软件显示可视化界面,结合GUI界面查看分析结果,也支持将模型导出使用,这款软件功能还是很多的,满足大部分神经网络训练需求,如果你需要就可以下载使用!
软件功能
PyTorch是一个Python软件包,提供两个高级功能:
1、具有强大GPU加速功能的Tensor计算(如NumPy)
2、在基于磁带的自动毕业系统上构建的深度神经网络
您可以在需要时重用自己喜欢的Python软件包(例如NumPy,SciPy和Cython)来扩展PyTorch。
从粒度上讲,PyTorch是一个由以下组件组成的库:
1、torch:像NumPy这样的Tensor库,具有强大的GPU支持
2、torch.autograd:一个基于磁带的自动微分库,该库支持火炬中所有可微分的Tensor操作
3、torch.jit:编译堆栈(TorchScript),以从PyTorch代码创建可序列化和可优化的模型
4、torch.nn:一个与autograd深度集成的神经网络库,旨在提供最大的灵活性
5、torch.multiprocessing:Python多处理,但跨进程的torch张量具有神奇的内存共享。对于数据加载和霍格威尔德训练有用
6、torch.utils:DataLoader和其他实用程序功能,以方便使用
通常,PyTorch可以用作:
替代NumPy以使用GPU的功能。
提供最大灵活性和速度的深度学习研究平台
软件特色
准备生产
使用TorchScript在渴望模式和图形模式之间无缝过渡,并使用TorchServe加快生产速度。

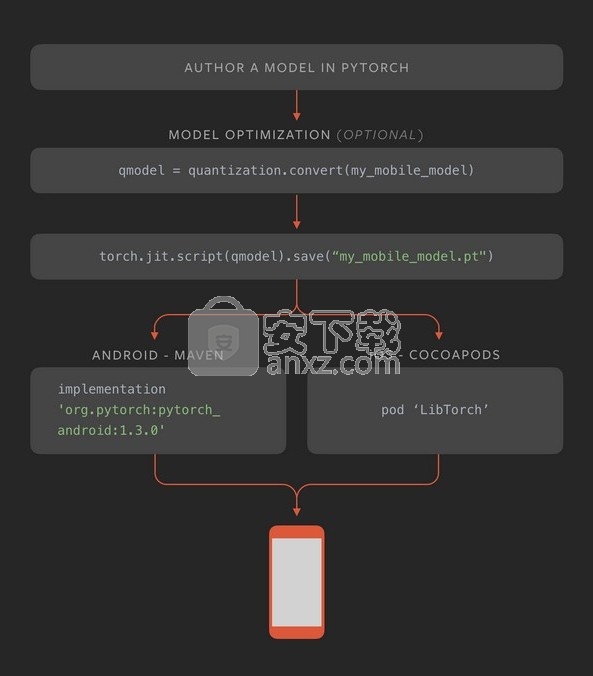
分布式培训
火炬。分布式后端可实现研究和生产中可扩展的分布式培训和性能优化。
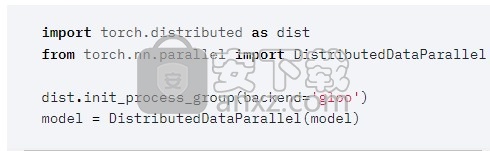
健壮的生态系统
丰富的工具和库生态系统扩展了PyTorch并支持计算机视觉,NLP等方面的开发。
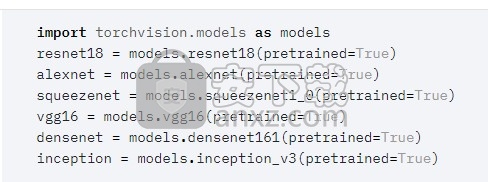
云端支援
PyTorch在主要的云平台上得到了很好的支持,提供了无摩擦的开发并且易于扩展。
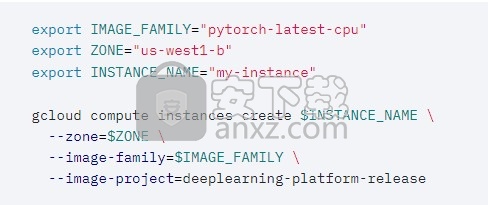
使用说明
音频 I/O 和torchaudio的预处理
PyTorch 是一个开源深度学习平台,提供了从研究原型到具有 GPU 支持的生产部署的无缝路径。
解决机器学习问题的重要工作是准备数据。 torchaudio充分利用了 PyTorch 的 GPU 支持,并提供了许多工具来简化数据加载并使其更具可读性。 在本教程中,我们将看到如何从简单的数据集中加载和预处理数据。 请访问音频 I/O 和torchaudio的预处理,以了解更多信息。
对于本教程,请确保已安装matplotlib包,以便于查看。
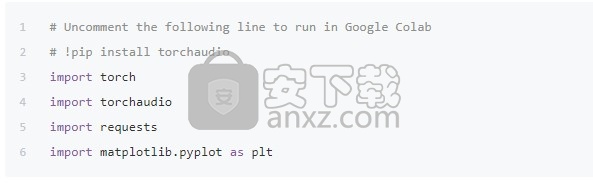
打开文件
torchaudio还支持以 wav 和 mp3 格式加载声音文件。 我们将波形称为原始音频信号。
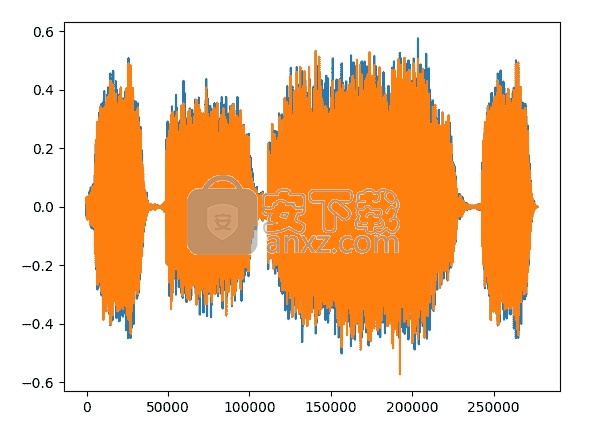
在torchaudio中加载文件时,可以选择指定后端以通过torchaudio.set_audio_backend使用 SoX 或 SoundFile 。 这些后端在需要时会延迟加载。
torchaudio还使 JIT 编译对于函数是可选的,并在可能的情况下使用nn.Module。
转换
torchaudio支持不断增长的转换列表。
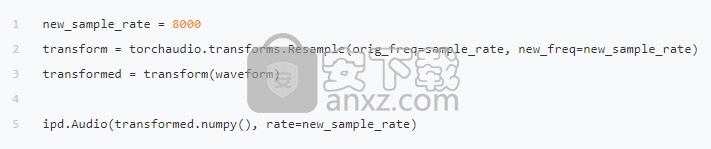
Resample:将波形重采样为其他采样率。
Spectrogram:从波形创建频谱图。
GriffinLim:使用 Griffin-Lim 变换从线性比例幅度谱图计算波形。
ComputeDeltas:计算张量(通常是声谱图)的增量系数。
ComplexNorm:计算复数张量的范数。
MelScale:使用转换矩阵将正常 STFT 转换为 Mel 频率 STFT。
AmplitudeToDB:这将频谱图从功率/振幅标度变为分贝标度。
MFCC:从波形创建梅尔频率倒谱系数。
MelSpectrogram:使用 PyTorch 中的 STFT 特征从波形创建 MEL 频谱图。
MuLawEncoding:基于 mu-law 压扩对波形进行编码。
MuLawDecoding:解码 mu-law 编码波形。
TimeStretch:在不更改给定速率的音调的情况下,及时拉伸频谱图。
FrequencyMasking:在频域中对频谱图应用屏蔽。
TimeMasking:在时域中对频谱图应用屏蔽。
每个变换都支持批量:您可以对单个原始音频信号或频谱图或许多相同形状的信号执行变换。
由于所有变换都是nn.Modules或jit.ScriptModules,因此它们可以随时用作神经网络的一部分。
首先,我们可以以对数刻度查看频谱图的对数。
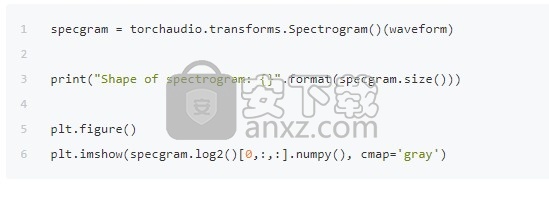

出:
Shape of spectrogram: torch.Size([2, 201, 1385])
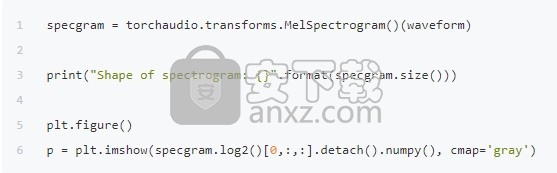
或者我们可以以对数刻度查看梅尔光谱图。

使用torchaudio的语音命令识别
本教程将向您展示如何正确设置音频数据集的格式,然后在数据集上训练/测试音频分类器网络。
Colab 提供了 GPU 选项。 在菜单选项卡中,选择“运行系统”,然后选择“更改运行系统类型”。 在随后的弹出窗口中,您可以选择 GPU。 更改之后,运行时应自动重新启动(这意味着来自已执行单元的信息会消失)。
首先,让我们导入常见的 Torch 包,例如torchaudio,可以按照网站上的说明进行安装。
让我们检查一下 CUDA GPU 是否可用,然后选择我们的设备。 在 GPU 上运行网络将大大减少训练/测试时间

导入数据集
我们使用torchaudio下载并表示数据集。 在这里,我们使用 SpeechCommands,它是由不同人员说出的 35 个命令的数据集。 数据集SPEECHCOMMANDS是数据集的torch.utils.data.Dataset版本。 在此数据集中,所有音频文件的长度约为 1 秒(因此约为 16000 个时间帧)。
实际的加载和格式化步骤是在访问数据点时发生的,torchaudio负责将音频文件转换为张量。 如果想直接加载音频文件,可以使用torchaudio.load()。 它返回一个包含新创建的张量的元组以及音频文件的采样频率(SpeechCommands为 16kHz)。
回到数据集,这里我们创建一个子类,将其分为标准训练,验证和测试子集。

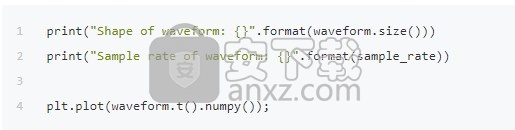
SPEECHCOMMANDS数据集中的数据点是一个由波形(音频信号),采样率,发声(标签),讲话者的 ID,发声数组成的元组。
让我们找到数据集中可用的标签列表。

35 个音频标签是用户说的命令。 前几个文件是人们所说的marvin。
最后一个文件是有人说“视觉”。

格式化数据
这是将转换应用于数据的好地方。 对于波形,我们对音频进行下采样以进行更快的处理,而不会损失太多的分类能力。
我们无需在此应用其他转换。 对于某些数据集,通常必须通过沿通道维度取平均值或仅保留其中一个通道来减少通道数量(例如,从立体声到单声道)。 由于SpeechCommands使用单个通道进行音频,因此此处不需要。
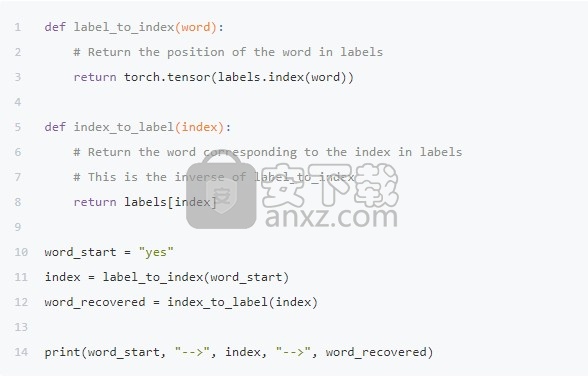
我们使用标签列表中的每个索引对每个单词进行编码。
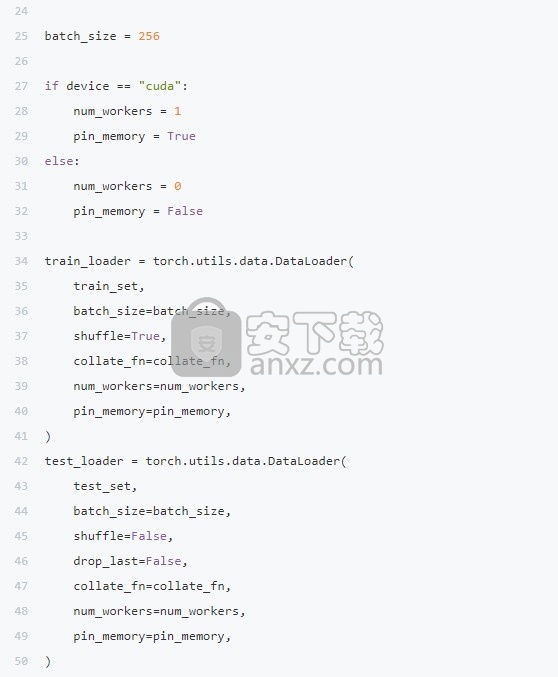
为了将由录音和语音构成的数据点列表转换为该模型的两个成批张量,我们实现了整理函数,PyTorch DataLoader使用了该函数,允许我们分批迭代数据集。
在整理函数中,我们还应用了重采样和文本编码。

人气软件
-

endnote x9.1中文版下载 107.0 MB
/简体中文 -

Canon IJ Scan Utility(多功能扫描仪管理工具) 61.55 MB
/英文 -

A+客户端(房源管理系统) 49.6 MB
/简体中文 -

第二代居民身份证读卡软件 4.25 MB
/简体中文 -

船讯网船舶动态查询系统 0 MB
/简体中文 -

ZennoPoster(自动化脚本采集/注册/发布工具) 596.65 MB
/英文 -

中兴zte td lte 18.9 MB
/简体中文 -

originpro 2021 527 MB
/英文 -

个人信息管理软件(AllMyNotes Organizer) 5.23 MB
/简体中文 -

ZKTeco居民身份证阅读软件 76.2 MB
/简体中文
 有道云笔记 8.0.70
有道云笔记 8.0.70  Efficient Efficcess Pro(个人信息管理软件) v5.60.555 免费版
Efficient Efficcess Pro(个人信息管理软件) v5.60.555 免费版  originpro8中文 附安装教程
originpro8中文 附安装教程  鸿飞日记本 2009
鸿飞日记本 2009  竞价批量查排名 v2020.7.15 官方版
竞价批量查排名 v2020.7.15 官方版  Scratchboard(信息组织管理软件) v30.0
Scratchboard(信息组织管理软件) v30.0  Fitness Manager(俱乐部管理软件) v9.9.9.0
Fitness Manager(俱乐部管理软件) v9.9.9.0 









