Apache Superset(开源可视化平台)
v0.38.1 官方版- 软件大小:75.7 MB
- 更新日期:2021-03-12 09:29
- 软件语言:英文
- 软件类别:数据库类
- 软件授权:免费版
- 软件官网:待审核
- 适用平台:WinXP, Win7, Win8, Win10, WinAll
- 软件厂商:

软件介绍 人气软件 下载地址
Apache
Superset提供数据库可视化开发功能,可以通过这款软件将你的数据显示在图表上分析,让用户可以快速将复杂的数据可视化,为分析数据提供帮助,可以使用数据可视化数组探索您的数据,通过交互式仪表板查看任意数据,软件提供丰富的仪表内容,可以显示不同的数据图,可以自定义图表类型,可以使用
SQL Lab编写查询以探索数据,支持大部分常见的数据库,包括MySQL、SQL
Server、SQLite,满足用户可视化数据库的需求;Superset功能非常多,导入相关的数据就可以创建图表和仪表盘执行可视化设计,如果你需要就下载吧!
软件功能
超集提供:
直观的界面,用于可视化数据集和制作交互式仪表板
多种精美的可视化展示您的数据
无代码可视化构建器,用于提取和呈现数据集
世界一流的SQL IDE,用于准备数据以进行可视化,其中包括丰富的元数据浏览器
轻量级的语义层,使数据分析人员能够快速定义自定义维度和指标
对大多数说SQL的数据库提供开箱即用的支持
无缝的内存中异步缓存和查询
一种可扩展的安全模型,允许配置关于谁可以访问哪些产品功能和数据集的非常复杂的规则。
与主要的身份验证后端(数据库,OpenID,LDAP,OAuth,REMOTE_USER等)集成
添加自定义可视化插件的功能
用于程序化定制的API
云原生架构,专为规模而设计
Superset是云原生的,旨在提供高可用性。它被设计为可扩展到大型分布式环境,并且在容器内可以很好地工作。虽然您可以在适中的设置下或仅在笔记本电脑上轻松测试Superset驱动器,但扩展平台几乎没有任何限制。
从灵活性上讲,Superset还是云原生的,它使您可以选择:
网络服务器(Gunicorn,Nginx,Apache),
元数据数据库引擎(MySQL,Postgres,MariaDB等),
消息队列(Redis,RabbitMQ,SQS等),
结果后端(S3,Redis,Memcached等),
缓存层(Memcached,Redis等),
Superset还可以与NewRelic,StatsD和DataDog等服务良好配合,并能够针对大多数流行的数据库技术运行分析工作负载。
目前,Superset已在许多公司大规模运行。例如,Superset在Kubernetes内的Airbnb生产环境中运行,每天为600多个活跃用户提供服务,每天查看超过10万张图表。
软件特色
Superset快速,轻巧,直观,并带有各种选项,使各种技能的用户都可以轻松浏览和可视化其数据,从简单的折线图到高度详细的地理空间图。
1、功能强大但易于使用
使用我们简单的无代码可视化构建器或最新的SQL IDE,可以快速,轻松地集成和浏览数据。

2、与现代数据库集成
Superset可以通过SQLAlchemy连接到任何基于SQL的数据源,包括PB级的现代云本机数据库和引擎。

3、现代建筑
Superset轻巧且具有高度可扩展性,可以利用现有数据基础架构的功能,而无需另外的提取层。
4、丰富的可视化和仪表板
Superset附带了各种精美的可视化效果。我们的可视化插件体系结构使构建直接放入Superset的自定义可视化变得容易。

官方教程
创建您的第一个仪表板
本节重点介绍将要使用Superset进行数据分析和探索工作流的最终用户的文档(数据分析师,业务分析师,数据科学家等)
本教程针对想要在Superset中创建图表和仪表盘的人员。我们将向您展示如何将Superset连接到新数据库以及如何在该数据库中配置表以进行分析。您还将浏览公开的数据,并将可视化效果添加到仪表板中,以便对端到端的用户体验有所了解。
连接到新数据库
Superset本身没有存储层来存储数据,而是与现有的说SQL的数据库或数据存储配对。
首先,我们需要将连接凭据添加到您的数据库中,以便能够查询和可视化其中的数据。如果您是通过Docker compose在本地使用Superset的 ,则可以跳过此步骤,因为Postgres数据库(名为examples)已包含在Superset中,并已为您预先配置。
在“数据”菜单下,选择“数据库”选项:
接下来,单击右上角的绿色+数据库按钮:
您可以在此窗口中配置许多高级选项,但是对于本演练,您只需指定两件事(数据库名称和SQLAlchemy URI):
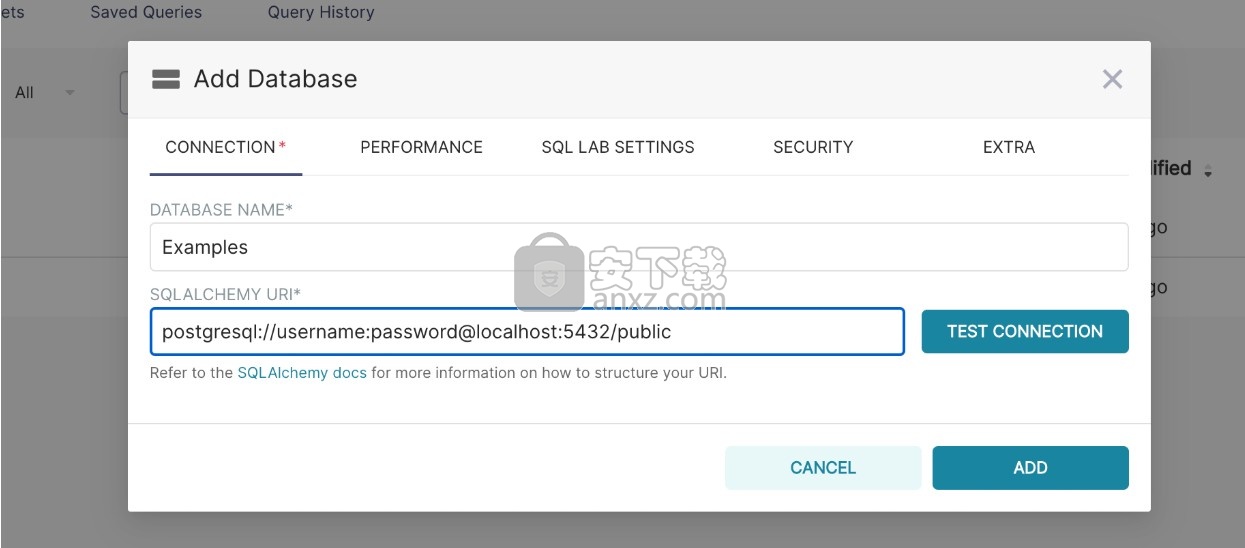
如URI下方的文本所述,您应参考SQLAlchemy文档, 为目标数据库创建新的连接URI。
单击“测试连接”按钮以确认一切正常工作。如果连接看起来不错,请通过单击模态窗口右下角的“添加”按钮来保存配置:
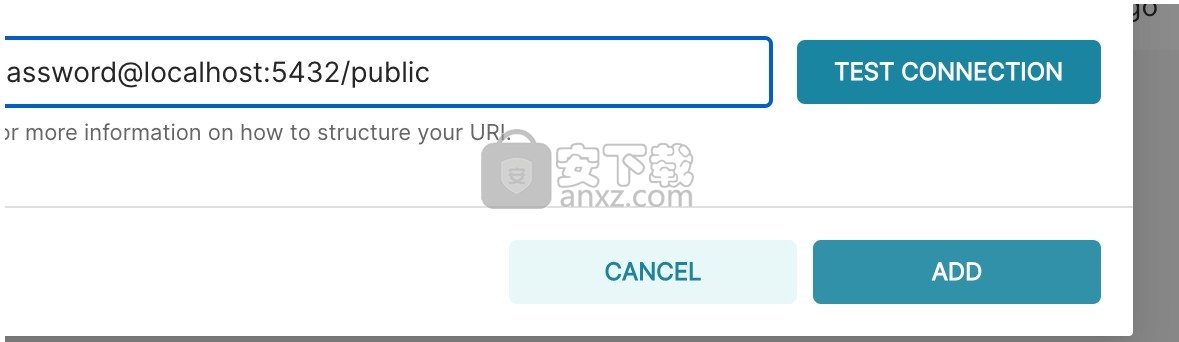
恭喜,您刚刚在Superset中添加了新的数据源!
注册一个新表
现在,您已经配置了数据源,您可以选择要在Superset中公开以进行查询的特定表(在Superset中称为数据集)。
导航至数据‣数据集,然后选择右上角的+数据集按钮。

一个模态窗口应该在您面前弹出。使用显示的下拉列表选择您的Database, Schema和Table。在以下示例中,我们从示例数据库中注册了cleaned_sales_data表。
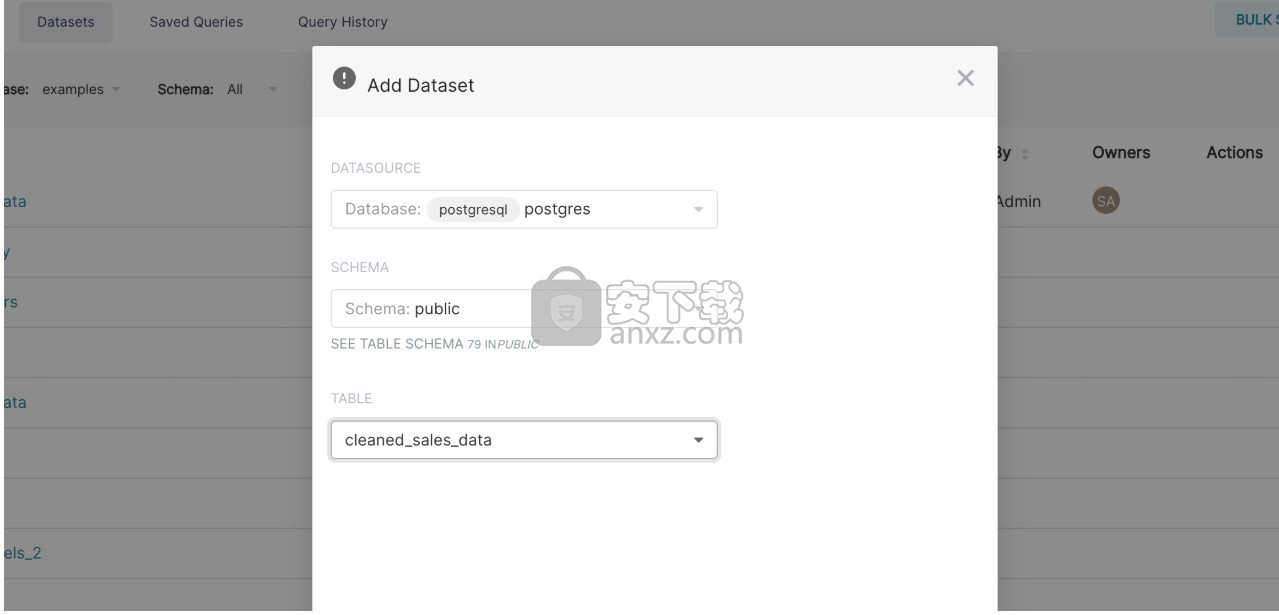
要完成操作,请单击右下角的“添加”按钮。现在,您应该在数据集列表中看到您的数据集。
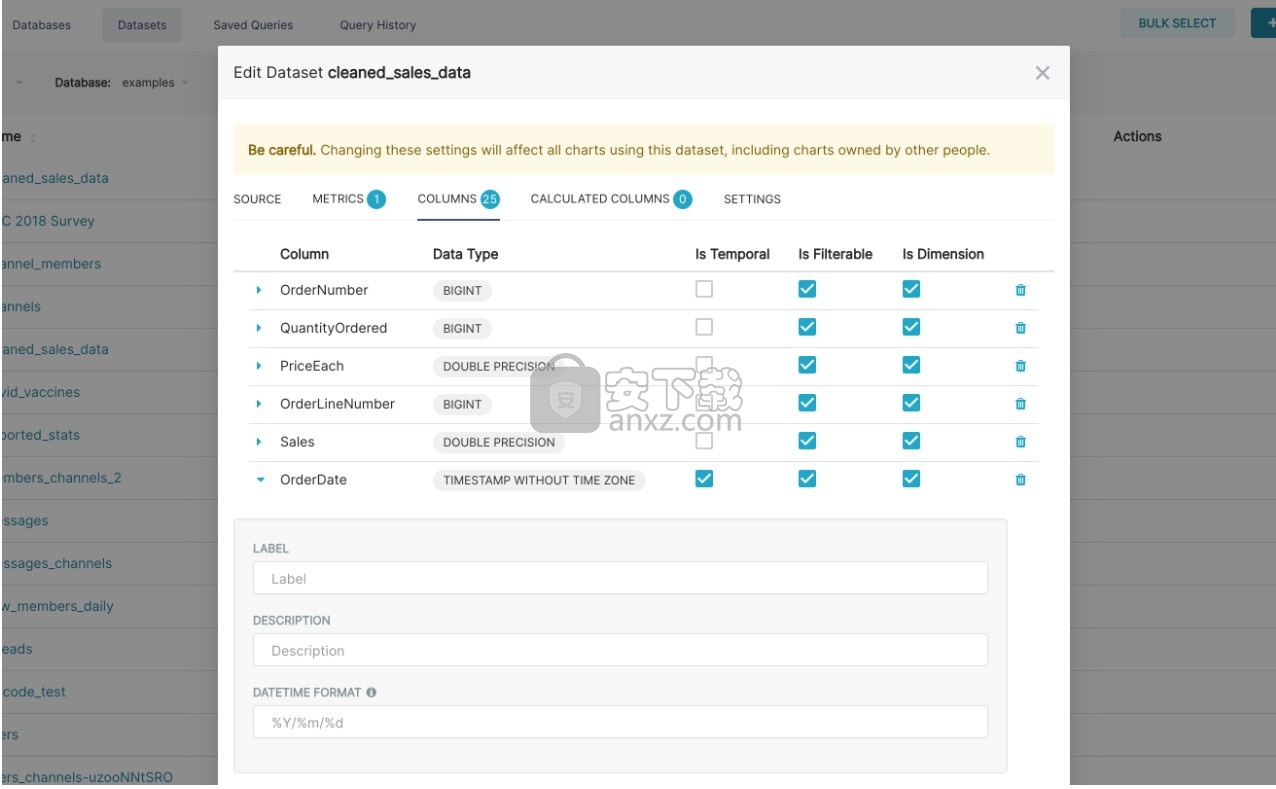
自定义列属性
现在,您已经注册了数据集,您可以配置列属性,以了解应如何在“探索”工作流程中处理该列:
列是临时的吗?(是否应将其用于时间序列图中的切片和切块?)
柱子应该可过滤吗?
列是维数吗?
如果是datetime列,那么Superset应该如何解析datetime格式?(使用ISO-8601字符串模式)
超集语义层
Superset具有较薄的语义层,可为分析人员增加许多生活质量。Superset语义层可以存储2种类型的计算数据:
1、虚拟指标:您可以编写SQL查询,以汇总来自多个列(例如SUM(recovered) / SUM(confirmed))的值,并使它们可作为列(例如recovery_rate)用于Explore中的可视化。允许并鼓励使用汇总函数作为指标。
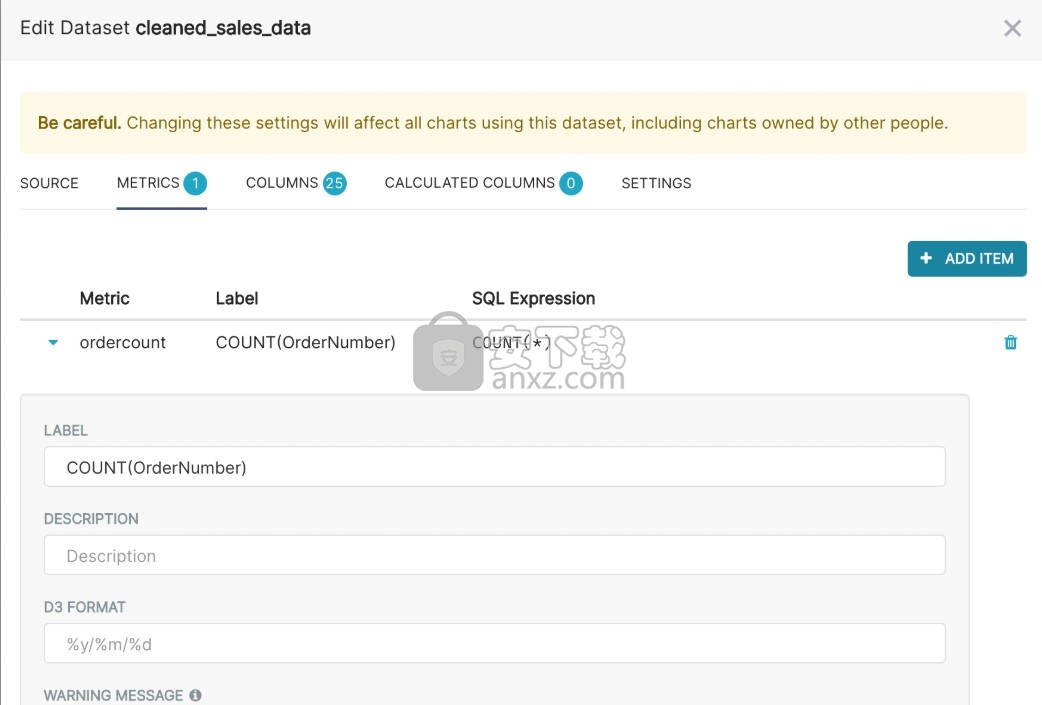
如果您希望在此视图中为您的团队提供服务,也可以对指标进行认证。
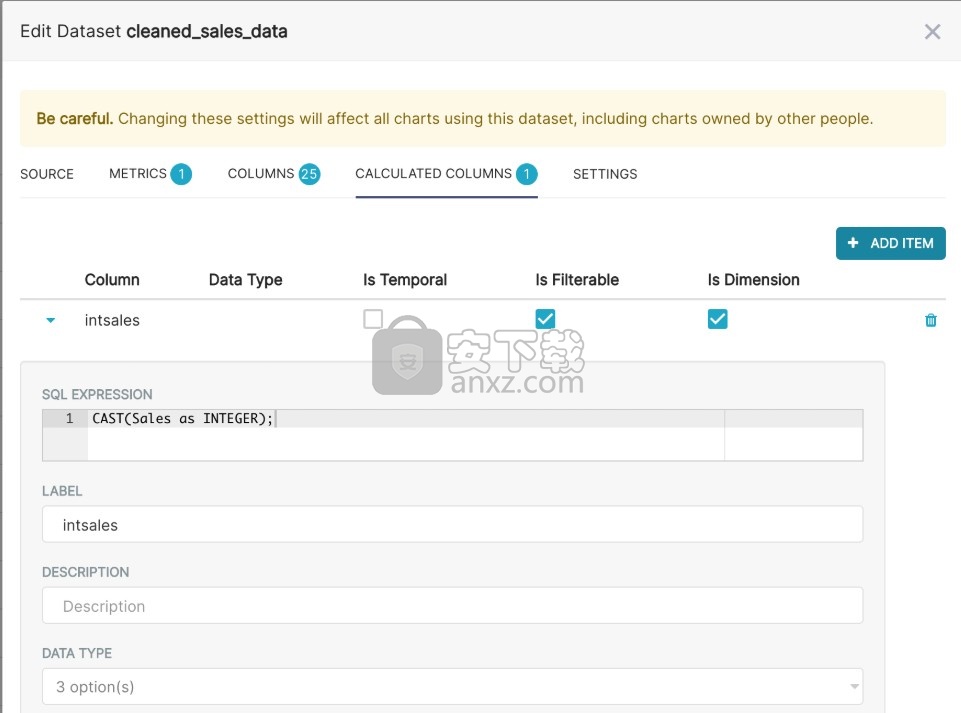
2、虚拟计算列:您可以编写SQL查询来自定义特定列(例如CAST(recovery_rate) as float)的外观和行为。计算列中不允许使用汇总函数。
在“浏览”视图中创建图表
Superset具有2个用于浏览数据的主要界面:
探索:无代码可视化生成器。选择您的数据集,选择图表,自定义外观,然后发布。
SQL Lab:用于清理,联接和准备数据以进行“探索”工作流的SQL IDE
现在,我们将重点关注用于创建图表的“浏览”视图。要从“数据集”选项卡启动“探索”工作流,请先单击将为图表提供动力的数据集的名称。

现在,您将获得一个功能强大的工作流,用于浏览数据并在图表上进行迭代。
左侧的“数据集”视图具有列和指标的列表,作用域仅限于您选择的当前数据集。
该数据图表区域下方的预览还为您提供有用的数据上下文。
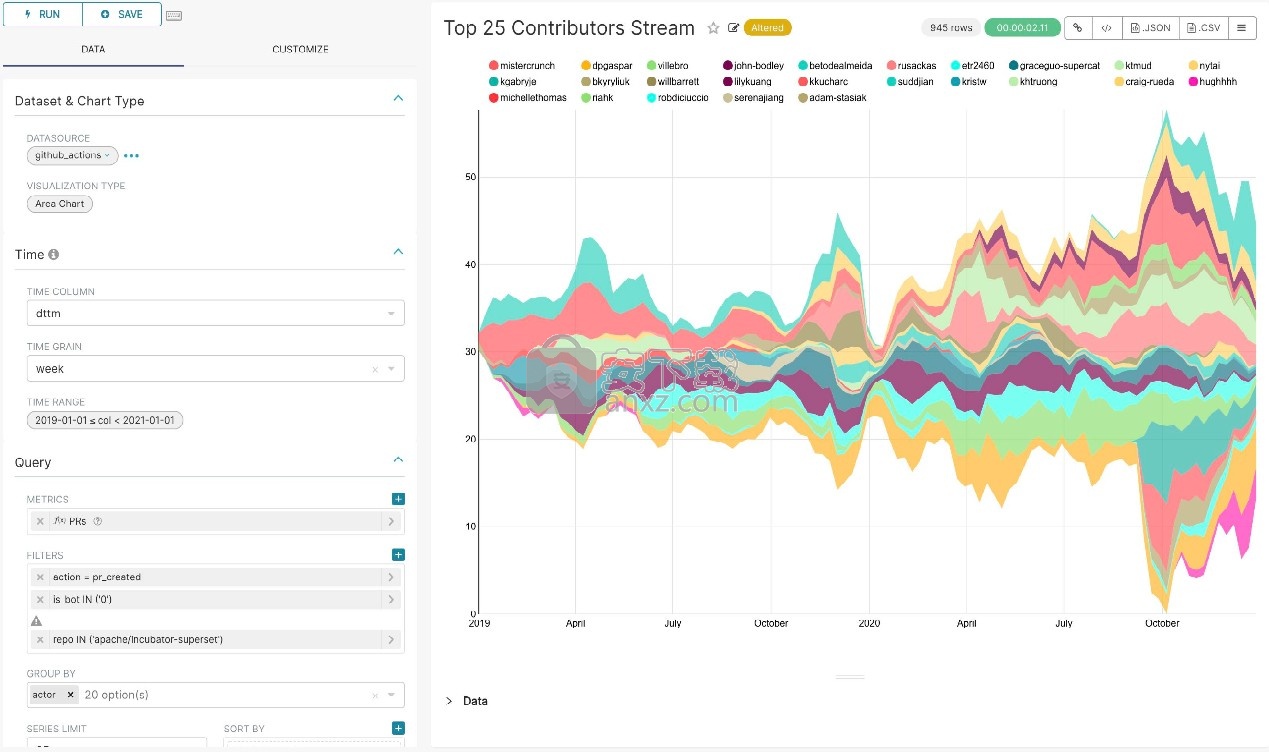
使用“数据”选项卡和“自定义”选项卡,您可以更改可视化类型,选择时间列,选择要分组的指标以及自定义图表的美观。
使用下拉菜单自定义图表时,请确保单击“运行”按钮以获取视觉反馈。
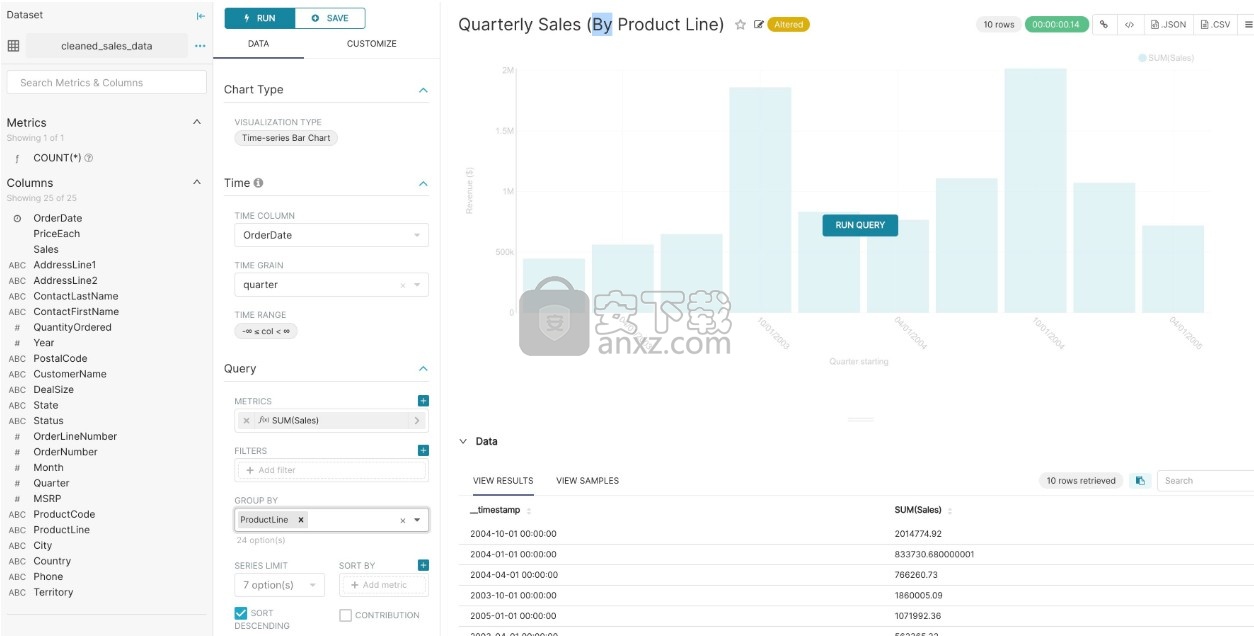
在以下屏幕截图中,我们只需按一下下拉菜单中的选项,就可以创建一个按时间分组的条形图,以按产品系列可视化我们的季度销售数据。
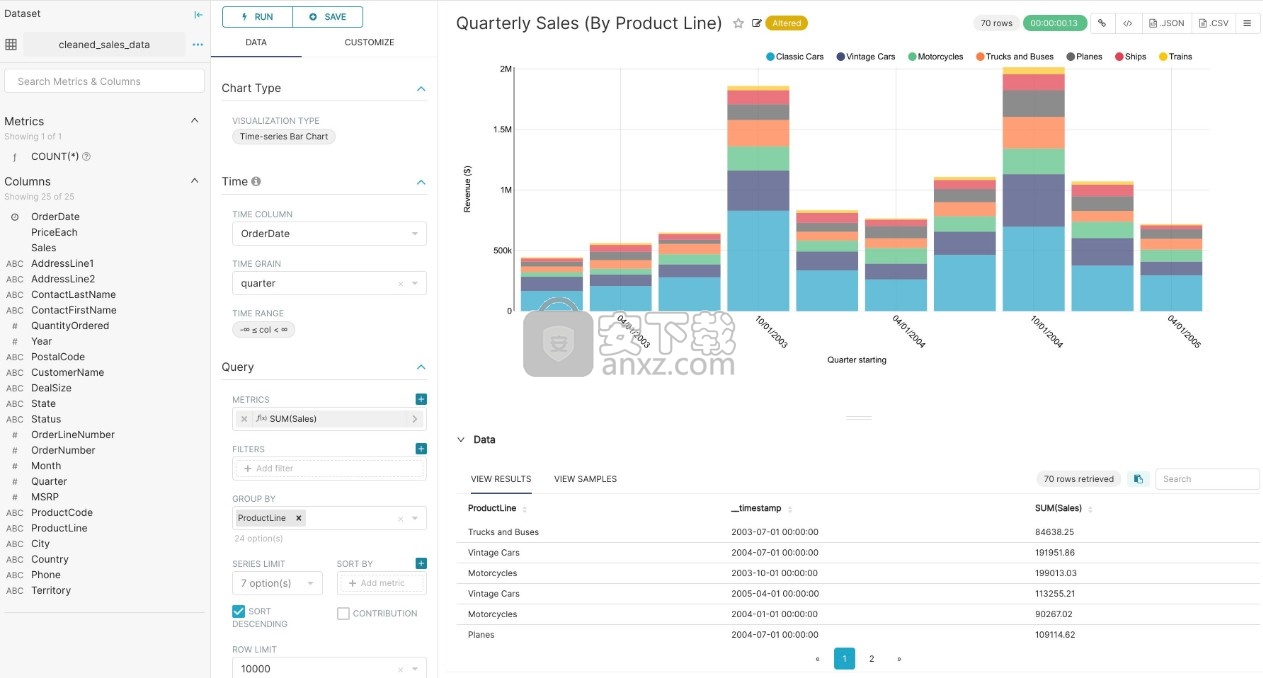
创建切片和仪表板
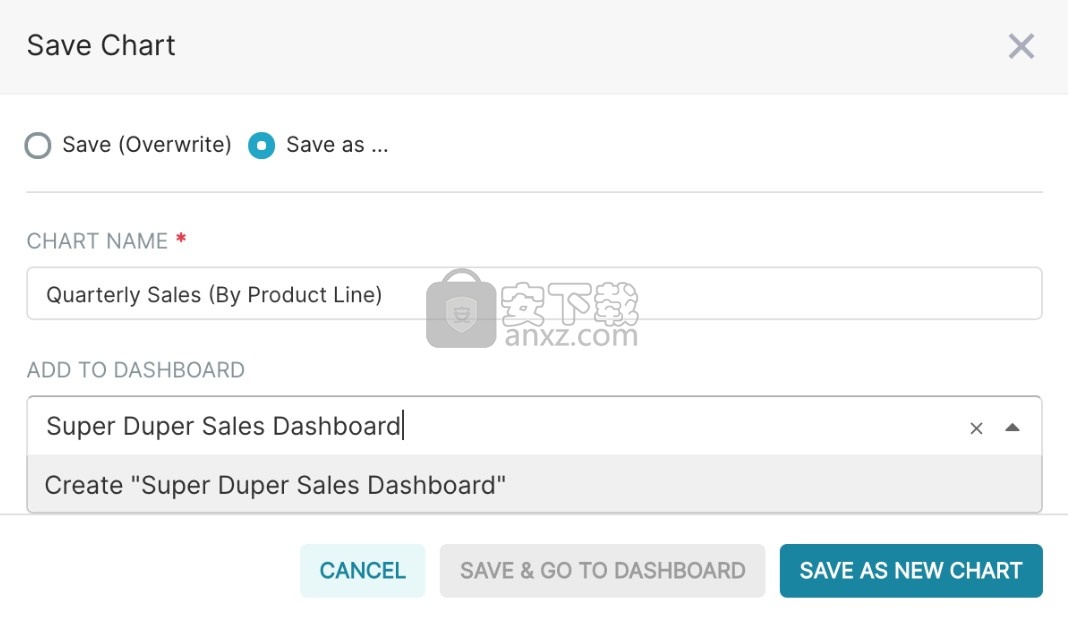
要保存图表,请首先单击“保存”按钮。您可以:
保存图表并将其添加到现有仪表板
保存图表并将其添加到新的仪表板
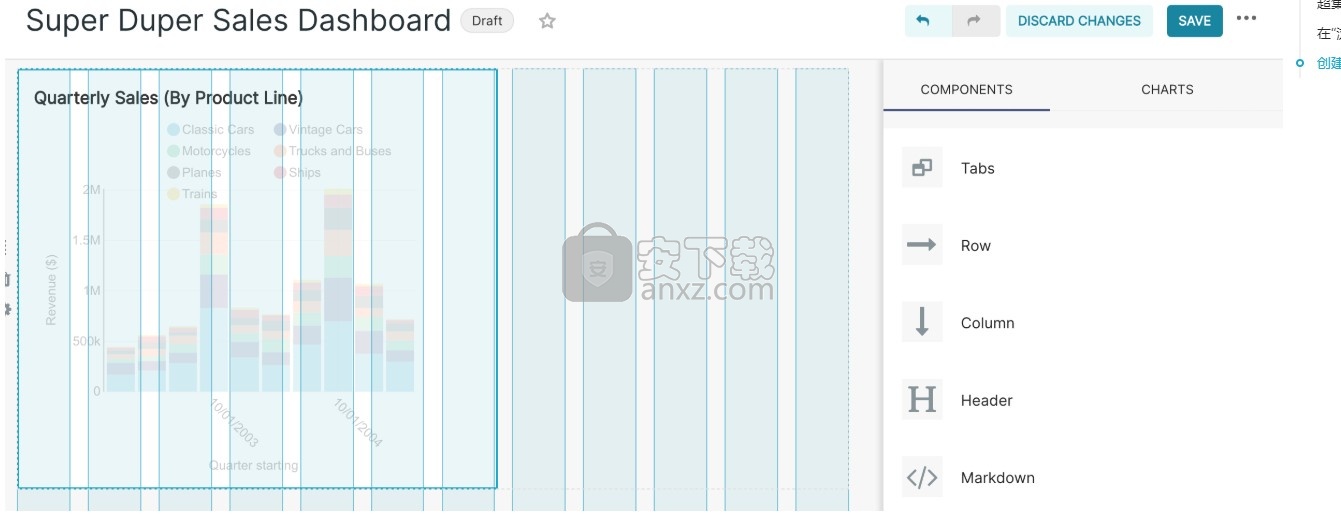
在以下屏幕截图中,我们将图表保存到新的“ Superset Duper销售仪表板”中:
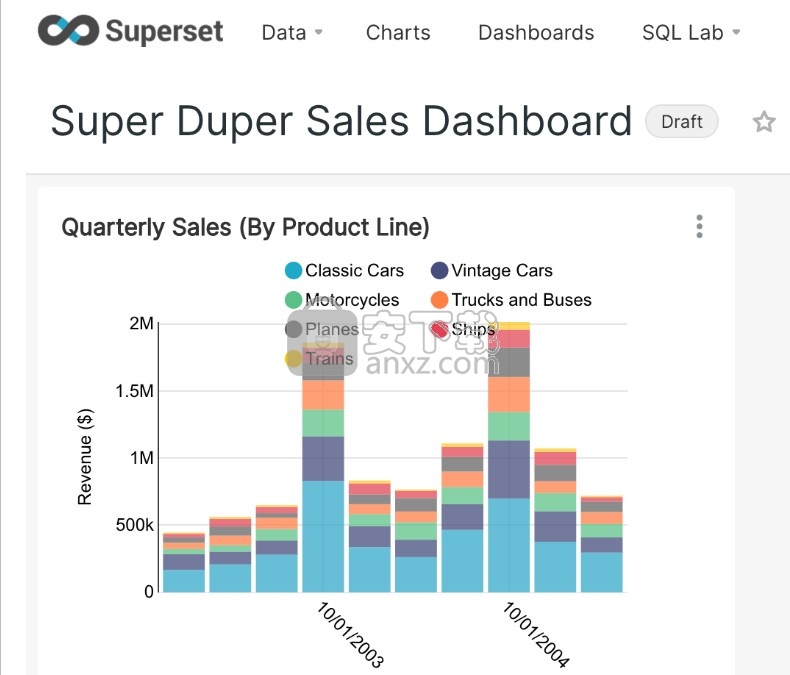
要发布,请单击保存并转到仪表板。
在后台,Superset将创建一个切片,并将创建图表所需的所有信息存储在其精简数据层中(查询,图表类型,所选选项,名称等)。
要调整图表大小,请先单击右上角的铅笔按钮。
然后,单击并拖动图表的右下角,直到图表布局捕捉到您喜欢的基础网格上的位置。
单击保存以保存更改。
恭喜!您已成功链接,分析和可视化了Superset中的数据。还有许多其他表配置和可视化选项,因此请开始探索和创建自己的切片和仪表板
常见问题
1、我可以一次加入/查询多个表吗?
不在“浏览”或“可视化” UI中。Superset SQLAlchemy数据源只能是单个表或视图。
使用表时,解决方案将是创建一个表,其中包含分析所需的所有字段,很可能是通过某些计划的批处理过程完成的。
视图是一个简单的逻辑层,该逻辑层将任意SQL查询抽象为虚拟表。这可以允许您联接和联合多个表,并使用任意SQL表达式进行一些转换。数据库的性能受到限制,因为Superset会有效地在查询(视图)之上运行查询。一个好的做法可能是将自己限制为只将主大表连接到一个或多个小表,并避免在可能的情况下使用GROUP BY,因为Superset会自己执行GROUP BY,并且两次执行工作可能会降低性能。
无论使用表还是视图,重要的因素是数据库是否足够快以交互方式提供服务,从而在Superset中提供良好的用户体验。
2、我的数据源有多大?
可能是巨大的!超集充当基础数据库或数据引擎之上的薄层。
如上所述,主要标准是数据库是否可以在用户可接受的时间范围内执行查询并返回结果。许多分布式数据库可以执行以交互方式扫描数TB的查询
3、如何将动态过滤器添加到仪表板?
使用“筛选器框”小部件,构建切片并将其添加到仪表板。
使用“过滤器框”小部件,您可以定义查询以填充可用于过滤的下拉列表。为了构建不同值的列表,我们运行一个查询,然后根据您提供的指标对结果进行排序,并按降序排序。
该小部件还具有一个复选框日期过滤器,它可以对仪表板启用时间过滤功能。选中该框并刷新后,您会看到一个从和到下拉列表。
默认情况下,过滤将应用于在共享过滤器所基于的列名称的数据源之上构建的所有切片。还要求在表编辑器的“列”选项卡中将该列检查为“可过滤”。
但是,如果您不希望某些小部件在仪表板上被过滤怎么办?您可以通过编辑仪表板来做到这一点,然后在表单中编辑JSON Metadata字段,更具体地说是filter_immune_slices键,该字段 将接收一个sliceIds数组,该数组不应受到任何仪表板级过滤的影响。
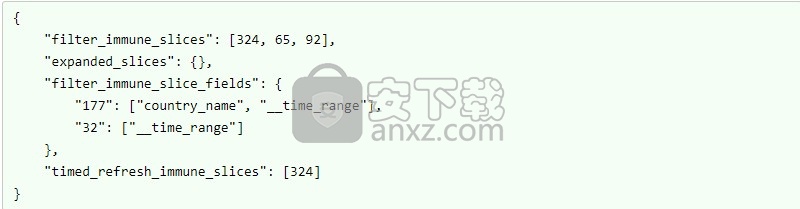
在上面的json blob中,切片324、65和92不会受到任何仪表板级过滤的影响。
现在记下filter_immune_slice_fields密钥。这使您可以更加具体,并为特定的slice_id定义,应忽略哪些过滤器字段。
请注意,使用了__time_range关键字,该关键字保留用于处理上述时间边界过滤。
但是,当处理来自不同表或数据库的切片时,过滤会发生什么?如果列名是共享的,则将应用过滤器,就这么简单。
4、如何限制仪表板上的定时刷新?
默认情况下,仪表板定时刷新功能使您可以根据设置的时间表自动重新查询仪表板上的每个切片。但是,有时您不希望刷新所有切片,尤其是当某些数据移动缓慢或运行繁重的查询时。要从定时刷新过程中排除特定的片,请将timed_refresh_immune_slices密钥添加到仪表板JSON元数据字段:

在上面的示例中,如果为仪表板设置了定时刷新,则除324以外的每个切片都将按计划自动重新查询。
切片刷新也将在指定时间段内错开。您可以通过将设置stagger_refresh为false来关闭这种交错,并通过stagger_time在JSON元数据字段中将值设置为毫秒来修改交错周期:
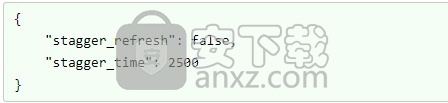
在这里,如果启用了定期刷新,则整个仪表板将立即刷新。2.5秒的交错时间将被忽略。
为什么启动时“ flask fab”或superset冻结/挂起/不响应(我的主目录已挂载NFS)?
默认情况下,Superset在创建并使用SQLite数据库~/.superset/superset.db。如果在NFS上使用SQLite,则已知SQLite不能很好地工作,这是因为NFS上的文件锁定实现损坏。
您可以使用SUPERSET_HOME环境变量覆盖此路径。
另一个解决方法是通过在以下位置添加以下内容来更改超集存储sqlite数据库的位置 superset_config.py:
SQLALCHEMY_DATABASE_URI = 'sqlite:////new/location/superset.db'
5、如果表架构更改了怎么办?
表模式不断发展,而Superset需要反映这一点。要添加新的维度或指标,在仪表板的生命周期中很常见。要让Superset发现新列,所有要做的就是转到菜单->源->表格,单击架构已更改的表格旁边的编辑图标,然后从“详细信息”选项卡中单击“保存” 。在幕后,新列将被合并。之后,您可能需要稍后重新编辑该表以配置“列”选项卡,选中相应的框并再次保存。
6、我可以使用哪个数据库引擎作为Superset的后端?
需要说明的是,数据库后端是Superset使用的OLTP数据库,用于存储其内部信息,例如您的用户列表,切片和仪表板定义。
Superset已使用Mysql,Postgresql和Sqlite作为其后端进行了测试。建议您在这些数据库服务器之一上安装Superset进行生产。
使用非列存储,例如Vertica,Redshift或Presto这样的非OLTP数据库作为数据库后端根本无法工作,因为这些数据库并非针对此类工作负载而设计的。在Oracle,Microsoft SQL Server或其他OLTP数据库上的安装可能有效,但未经测试。
请注意,几乎所有具有SqlAlchemy集成的数据库都可以作为Superset的数据源正常运行,而不是作为OLTP后端
人气软件
-

PL/SQL Developer(PL/SQL数据库管理软件) 130.1 MB
/简体中文 -

Oracle SQL Developer(oracle数据库开发工具) 382 MB
/简体中文 -

PowerDesigner16.6 32/64位 2939 MB
/简体中文 -

Navicat for MySQL 15中文 72.1 MB
/简体中文 -

Navicat Data Modeler 3中文 101 MB
/简体中文 -

SPSS 22.0中文 774 MB
/多国语言 -

db文件查看器(SQLiteSpy) 1.67 MB
/英文 -

Navicat Premium V9.0.10 简体中文绿色版 13.00 MB
/简体中文 -

Navicat 15 for MongoDB中文 78.1 MB
/简体中文 -

sql prompt 9 12.67 MB
/简体中文
 toad for oracle 绿化版 v12.8.0.49 中文
toad for oracle 绿化版 v12.8.0.49 中文  Aqua Data Studio(数据库开发工具) v16.03
Aqua Data Studio(数据库开发工具) v16.03  dbforge studio 2020 for oracle v4.1.94 Enterprise企业
dbforge studio 2020 for oracle v4.1.94 Enterprise企业  navicat 12 for mongodb 64位/32位中文 v12.1.7 附带安装教程
navicat 12 for mongodb 64位/32位中文 v12.1.7 附带安装教程  SysTools SQL Log Analyzer(sql日志分析工具) v7.0 (附破解教程)
SysTools SQL Log Analyzer(sql日志分析工具) v7.0 (附破解教程)  FileMaker pro 18 Advanced v18.0.1.122 注册激活版
FileMaker pro 18 Advanced v18.0.1.122 注册激活版  E-Code Explorer(易语言反编译工具) v0.86 绿色免费版
E-Code Explorer(易语言反编译工具) v0.86 绿色免费版