

Stata 16补丁
附带安装教程- 软件大小:24.55 MB
- 更新日期:2020-07-23 18:13
- 软件语言:简体中文
- 软件类别:编程工具
- 软件授权:免费版
- 软件官网:待审核
- 适用平台:WinXP, Win7, Win8, Win10, WinAll
- 软件厂商:

软件介绍 人气软件 下载地址
Stata补丁是一款针对Stata 16而开发的文件,此文件能够帮助用户将官方程序进行,从而解除所有的功能限制;在新版本中,用户可以从Stata中嵌入并执行Python代码,Stata的新python命令提供了一系列子命令,使您可以轻松地从Stata调用Python并在Stata中输出Python结果;可以以交互方式或在do文件和ado文件中调用Python,以便可以利用Python的广泛语言功能,也可以直接通过Stata执行Python脚本文件;新版本提供了Stata和Python之间的双向连接,允许用户将Python的功能与Stata的核心功能进行交互;在模块内,定义了类以提供对Stata当前数据集,帧,宏,标量,矩阵,值标签,特征,全局Mata矩阵等的访问;Stata一直强调命令行界面,该界面有助于可复制的分析,现在该程序包含了一个图形用户界面,该界面使用菜单和对话框可以访问几乎所有内置命令;这将生成始终显示的代码,从而简化了向命令行界面的过渡和更灵活的脚本语言,可以以电子表格格式查看或编辑数据集,现在还可以在打开数据浏览器或编辑器时执行其他命令;需要的用户可以下载体验
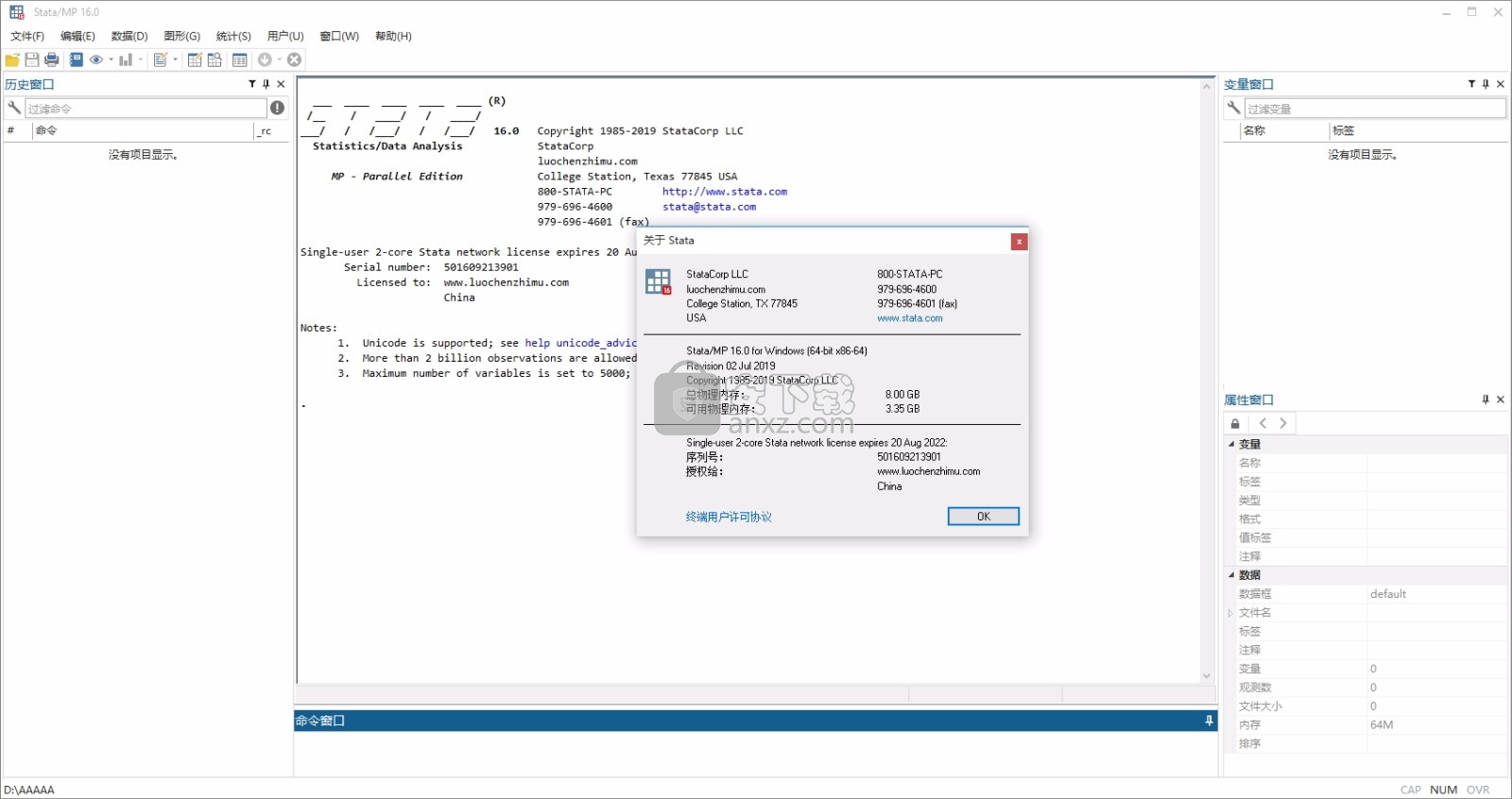
软件功能
功能模块信息如下:
支持使用图表构建器创建的图表、图表过程以及通过统计过程创建的图表
回归模型、一般估计和回归、图形汇总
Gelman-Rubin-收敛诊断、有效样本量、摘要统计
信息准则、模型后验概率的假设检验、表计算器
区间假设检验、预测
后验预测p值、标题。 在查看器的概要窗格中标记为标题的文本对象。
精确 Logistic回归、精确泊松回归、百分位与置信区间
双样本 Kolmogorov-Smirnov-检验、K样本中位数检验
二项式概率检验、二项式概率检验计算器、对称性和边际齐性检验
对称性和边际齐性检验计算器、双向表关联性分析、所有可能的双向表
软件特色
数据结构与存储
Stata一次只能打开一个数据集
Stata将整个数据集保存在(随机访问或虚拟)内存中,这限制了它在超大型数据集中的使用。
有效的内部存储在某种程度上减轻了这种情况
因为整数存储类型仅占用一个或两个字节,而不是四个字节,并且浮点数的默认类型是单精度而不是双精度点数。
Stata提供许多许可证,从学生到专业人士使用,小型版本可用于价格较低的小型数据集。
数据集的格式始终为矩形,也就是说,所有变量都具有相同数量的观察值
用更多的数学术语来说,所有向量的长度都相同,尽管某些条目可能缺少值
按类别
线性模型
检验结果、内源回归、自举,折刀以及鲁棒和簇鲁棒方差、工具变量、三阶段最小二乘、约束、分位数回归、GLS
面板/纵向数据
具有稳健的标准误差、线性混合模型、随机效应概率、随机效应和固定效应泊松、动态面板数据模型
多级混合效应模型
连续,二进制,计数和生存结果、两级,三级和更高级别的模型、广义线性模型、非线性模型
随机截距、随机斜率、交叉随机效应、效应和拟合值的BLUPs、层次模型/残差错误结构、DDF调整、支持调查数据
二进制,计数和有限结果
逻辑,概率,位、泊松和负二项式、有条件,多项式,嵌套,有序,等级有序和定型逻辑
多项式、零膨胀和左截断的计数模型、选择模型•边际效应•更多
扩展回归模型(ERM)
越来越
多地将内生协变量,样本选择和非随机处理结合在模型中以实现连续,间隔检查,二进制和有序结果。
安装步骤
1、用户可以点击本网站提供的下载路径下载得到对应的程序安装包
2、只需要使用解压功能将压缩包打开,双击主程序即可进行安装,弹出程序安装界面
3、同意上述协议条款,然后继续安装应用程序,点击同意按钮即可
4、弹出以下界面,用户可以直接输一个名称,或者直接点击下一步功能按钮
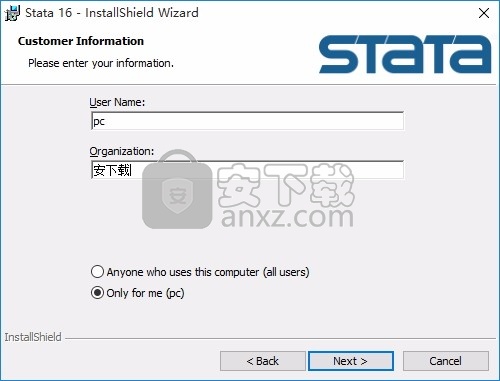
5、可以根据您的需要选择不同的程序类型进行安装
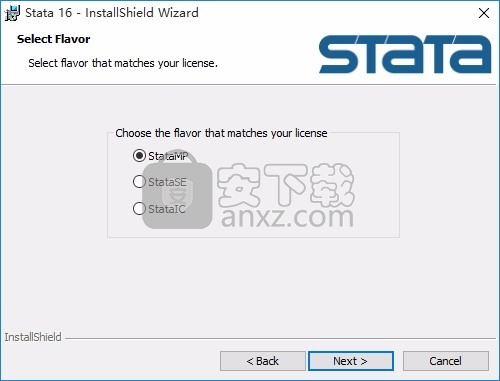
6、可以根据自己的需要点击浏览按钮将应用程序的安装路径进行更改
7、弹出以下界面,用户可以直接使用鼠标点击下一步按钮,可以根据您的需要不同的组件进行安装
8、现在准备安装主程序,点击安装按钮开始安装
9、弹出应用程序安装进度条加载界面,只需要等待加载完成即可
10、根据提示点击安装,弹出程序安装完成界面,点击完成按钮即可
方法
1、程序安装完成后,先不要运行程序,打开安装包,然后将文件夹内的文件复制到粘贴板
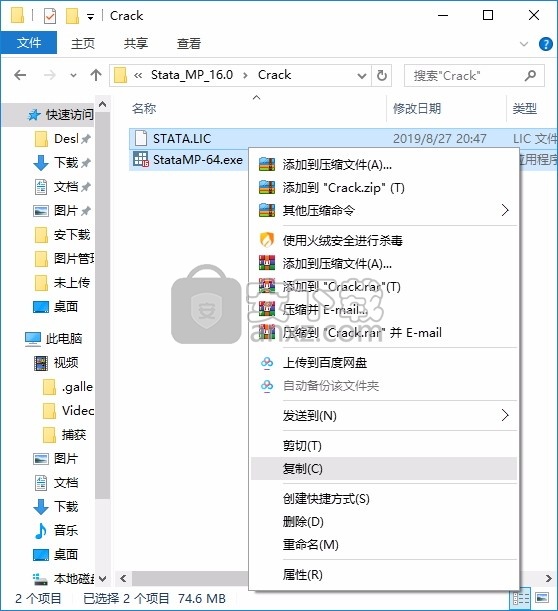
2、然后打开程序安装路径,把复制的文件粘贴到对应的程序文件夹中替换源文件
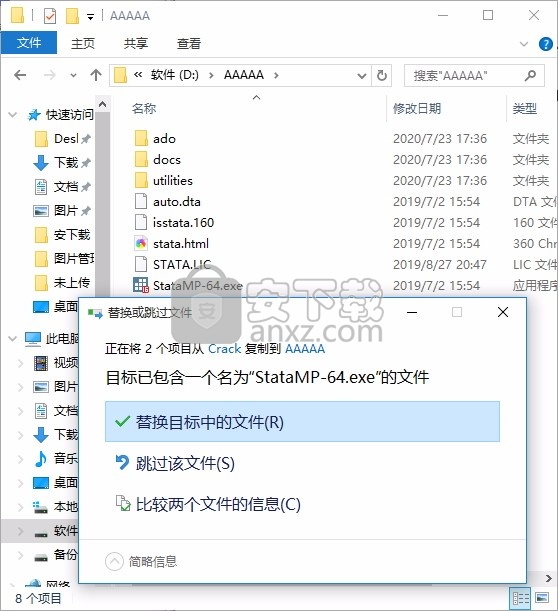
3、完成以上操作步骤后,就可以双击应用程序将其打开,此时您就可以得到对应程序
使用说明
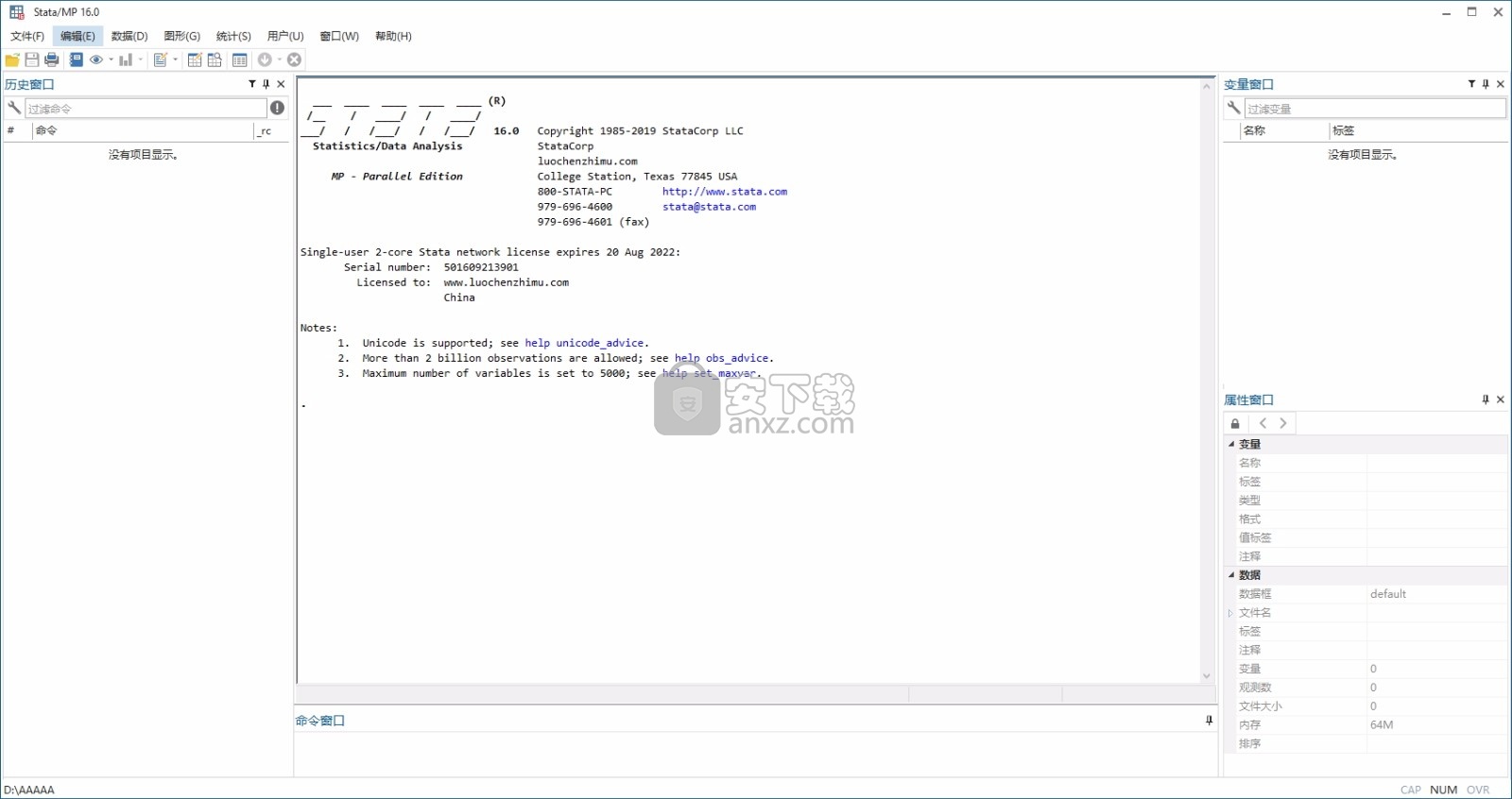
任何研究项目的首要任务之一就是读取数据。 import sas允许我们将SAS®数据从版本7或更高版本导入Stata。我们可以导入整个数据集或仅导入其中的一部分。通过import sas,我们还可以导入价值标签。日期,值标签和缺失值均已从SAS正确转换为Stata格式。
让我们看看它的工作原理
我们有一个SAS数据集,其中包含美国人口普查局的美国社区调查提供的康涅狄格州住房数据。
该数据集名为psam_h09.sas7bdat。要将其导入Stata,我们通过单击文件>导入> SAS数据(* .sas7bdat)打开“导入sas”对话框。我们选择psam_h09.sas7bdat并获得
现在,我们可以导入所有数据或仅导入一部分。
在这种情况下,我们要导入与信息有关的通信和技术。具体来说,我们导入变量来记录家庭是否可以访问互联网(ACCESS),以及该互联网是拨号服务(DIALUP)还是高速互联网(HISPEED)。我们还导入变量,以记录它们是否具有便携式计算机或台式机(LAPTOP)或其他计算机设备(COMPOTHX)。另外,我们导入变量以指示它们是否具有蜂窝数据计划(BROADBND)。
请注意,变量在此SAS文件中具有大写名称。我们希望它们全部都小写。在可变大小写下:我们选择选项下级。
现在,我们可以单击“确定”导入数据。
与往常一样,我们可以使用命令代替对话框。这是我们应该输入的内容:
进口SAS访问BROADBND COMPOTHX DIALUP HISPEED LAPTOP使用
psam_h09.sas7bdat”,案例(下)
无论哪种情况,数据现在都存储在Stata中,可以进行分析了。
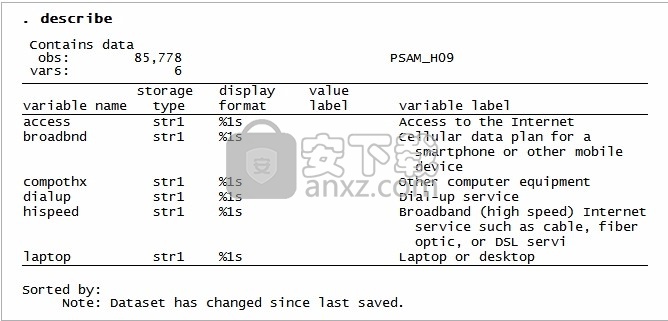
导入了我们将要使用的所有模块,函数和对象。
将这四个要素和物种类型分别加载到两个NumPy数组X和y中。请注意,为简单起见,我们不在此处拆分数据集,而是将所有实例用作训练样本。
使用Matplotlib绘制3D散点图。
为sklearn包中定义的分类构建了一个SVC分类器,并拟合了模型。
使用训练有素的分类器对数据集进行预测。
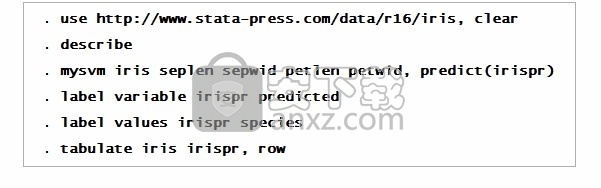
将预测结果存储到Stata中的新变量irispr中。
回到Stata,将iris的值标签附加到irispr上,并使用tabulate命令显示分类表。
上表显示,有2个杂色鸢尾花观察结果被错误分类为维吉尼亚鸢尾,没有鸢尾鸢尾或维吉尼亚鸢尾花被错误归类。
将Python代码嵌入到ado文件中
Python代码也可以嵌入和在ado文件中执行。下面,我们在mysvm.ado中创建一个新命令mysvm来说明此目的。 mysvm期望首先指定一个标签变量,然后是一系列特征变量,以及一个predict()选项,该选项指定要在其中存储预测的变量的名称。
将Python代码嵌入到ado文件中
Python代码也可以嵌入和在ado文件中执行。下面,我们在mysvm.ado中创建一个新命令mysvm来说明此目的。 mysvm期望首先指定一个标签变量,然后是一系列特征变量,以及一个predict()选项,该选项指定要在其中存储预测的变量的名称。
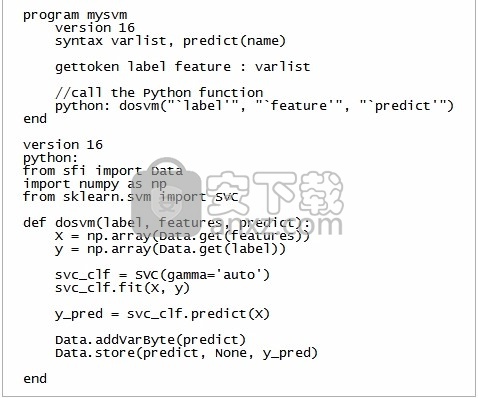
在上面的ado文件中,我们在Python函数dosvm()中定义了分类器,该分类器采用了种类类型变量,四个特征变量以及将预测存储为参数的新变量。我们在ado代码中使用python:istmt语法调用了Python函数。
要产生与上述相同的输出,我们可以输入
与线性回归一样,非参数级数回归(NPSR)估计给定协变量集的平均结果。与线性回归不同,NPSR在协变量方面不确定结局的功能形式,这意味着NPSR不受错误指定错误的影响。
在NPSR中,您可以指定因变量及其决定因素。 NPSR确定功能形式。
您可以指定要拟合的模型的通用性(非参数化程度)。
拟合的模型不会以代数形式返回。实际上,该函数甚至从未以代数形式出现。它由一个系列近似,您可以选择多项式系列,自然样条系列或B样条系列。 npregress系列报告
连续协变量的平均边际效应
离散协变量的对比
npregress级数比线性回归需要更多的观测值以产生一致的估计,并且所需观测值的数量随协变量数量和\(g()\)的复杂性而增长。
让我们看看它的工作原理
我们有来自世界512个葡萄酒产区的葡萄酒产量的虚构数据。输出将是我们的因变量。我们认为产量受到以下因素的影响
葡萄酒生产税
毫米/小时
灌溉酒庄是否灌溉
我们的主要兴趣是了解税率如何影响葡萄酒的产量,我们将降雨和灌溉作为控制因素,以便正确地测量税率的影响。
我们从拟合模型开始。
npregress系列输出税收水平降雨灌溉
计算近似函数
最小化交叉验证标准
迭代0:交叉验证条件= 109.7216
计算平均导数
三次B样条估计obs数= 512
标准:交叉验证结数= 1
输出报告了-297、53和8.4对税率,降雨量和灌溉的影响
从-297开始。税率水平是一个连续变量,因此-297是“平均边际效应”,这意味着它是产出相对于税率水平的平均导数。换句话说,边际效应被经济学家称为税收对产出的平均边际效应。较高的税收导致较低的产出。
现在考虑53,这也是平均边际效应,因为降雨是一个连续变量。更高的降雨增加了葡萄酒产量。
最后是8.4,这是对比,因为灌溉是一个因子(虚拟)变量。如果葡萄种植者灌溉,灌溉为1,否则为0。 8.4的对比度是离散更改的平均效果。如果所有生产者都被灌溉,那么平均产出将是多少;如果没有生产者被灌溉,则平均产出将是多少。 8.4表示灌溉的积极治疗效果。
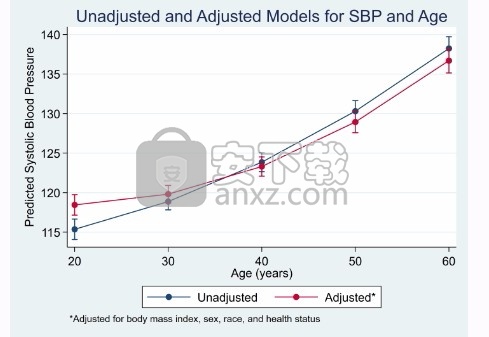
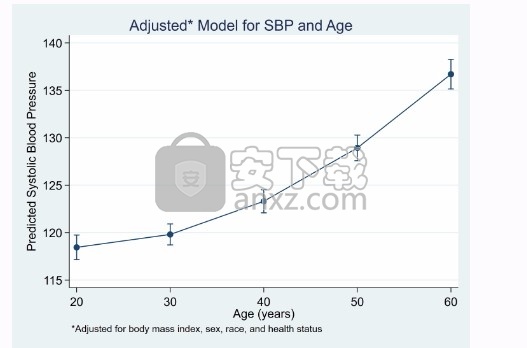
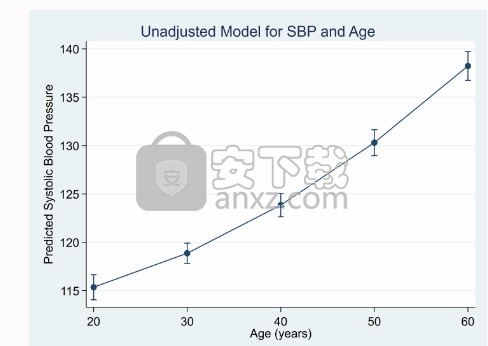
这些估计的效果是否回答了您的研究问题?它们可能会,但如果没有,我们可以使用Stata的margins命令获得所需的估计效果。如果我们需要探索各种税率的影响,例如11%至29%,我们可以输入
边距,at(taxlevel =(。11(.03).29))(输出省略)
它会生成一个效果和标准误差表,我们将其省略,因为我们希望以图形方式显示结果,我们只需在使用ma生成表后键入marginsplot即可完成此操作
税收的影响不是线性的。
您不仅可以一次探索一个变量的功能。 您可以通过键入以下内容来调查不同税率和灌溉水平的平均产出
边距灌溉,at(taxlevel =(。11(.03).29))
您可以通过键入以下内容来调查不同税率,灌溉和降雨水平的平均产出
边距在(taxlevel =(。11(.03).29))at(rainfall =(。01(.05).33))处灌溉
花一点时间欣赏一下。 我们认为葡萄酒的产量是税收,降雨和灌溉的函数,但我们不知道该函数。 尽管如此,我们仍可以拟合未知函数的近似值,并使用npregress序列,边距和marginsplot对其进行探索以获得统计见解。
人气软件
-

redis desktop manager2020.1中文 32.52 MB
/简体中文 -

s7 200 smart编程软件 187 MB
/简体中文 -

GX Works 2(三菱PLC编程软件) 487 MB
/简体中文 -

CIMCO Edit V8中文 248 MB
/简体中文 -

JetBrains DataGrip 353 MB
/英文 -

Dev C++下载 (TDM-GCC) 83.52 MB
/简体中文 -

TouchWin编辑工具(信捷触摸屏编程软件) 55.69 MB
/简体中文 -
信捷PLC编程工具软件 14.4 MB
/简体中文 -

TLauncher(Minecraft游戏启动器) 16.95 MB
/英文 -

Ardublock中文版(Arduino图形化编程软件) 2.65 MB
/简体中文
 Embarcadero RAD Studio(多功能应用程序开发工具) 12
Embarcadero RAD Studio(多功能应用程序开发工具) 12  猿编程客户端 4.16.0
猿编程客户端 4.16.0  VSCodium(VScode二进制版本) v1.57.1
VSCodium(VScode二进制版本) v1.57.1  aardio(桌面软件快速开发) v35.69.2
aardio(桌面软件快速开发) v35.69.2  一鹤快手(AAuto Studio) v35.69.2
一鹤快手(AAuto Studio) v35.69.2  ILSpy(.Net反编译) v8.0.0.7339 绿色
ILSpy(.Net反编译) v8.0.0.7339 绿色  文本编辑器 Notepad++ v8.1.3 官方中文版
文本编辑器 Notepad++ v8.1.3 官方中文版 






