

集搜客网络爬虫(GooSeeker)
v8.2.1 免费版- 软件大小:29.97 MB
- 更新日期:2019-08-15 09:58
- 软件语言:简体中文
- 软件类别:编程工具
- 软件授权:免费版
- 软件官网:待审核
- 适用平台:WinXP, Win7, Win8, Win10, WinAll
- 软件厂商:

软件介绍 人气软件 下载地址
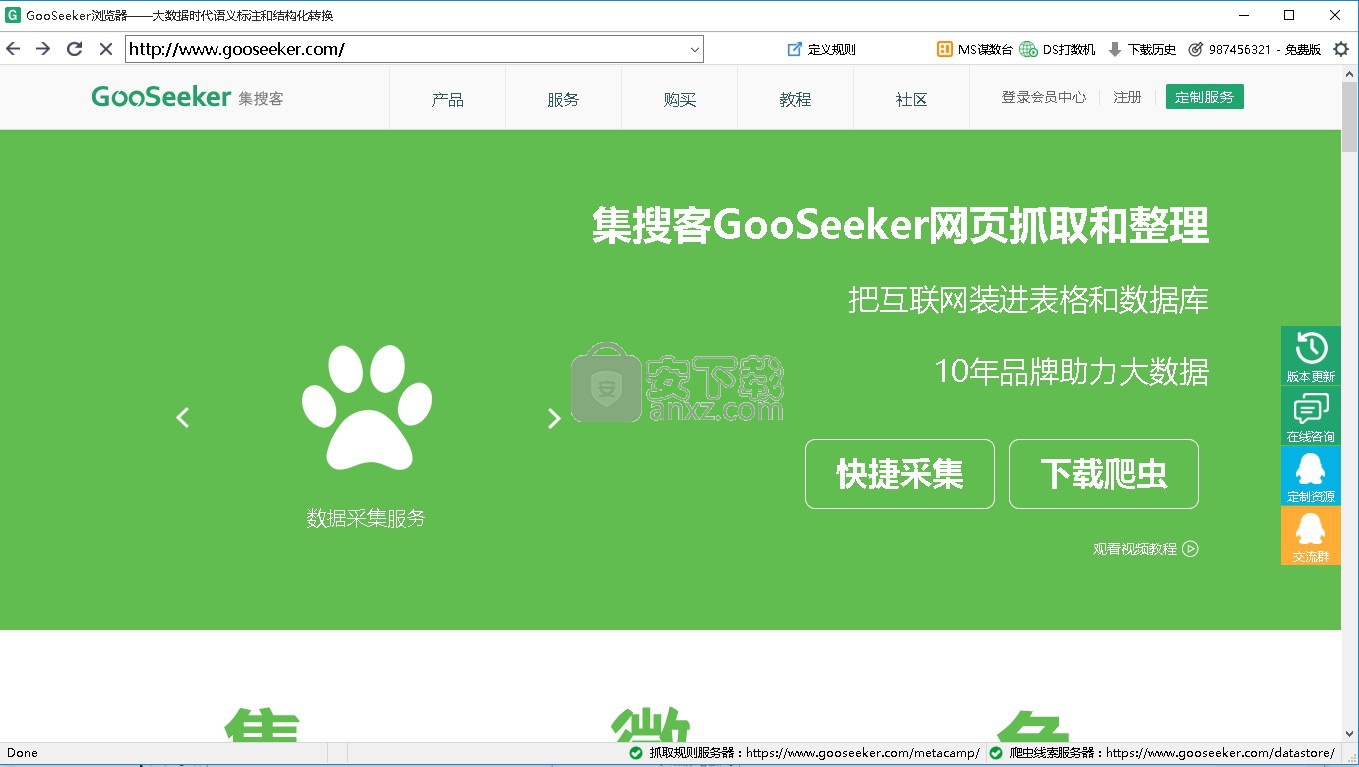
集搜客网络爬虫(GooSeeker)是深圳天据电子商务有限公司出品的一款免费网页抓取软件,该软件支持集成化图形界面、在使用过程中,抓取规则会根据系统自动生成、随机延迟、抓取结果本地存储、高仿真模拟点击等功能,爬虫不能只是抓取数据,还要对抓来的数据进行管理,所以系统更新出了一套运行逻辑,来实现对爬虫、任务、数据的业务管理,这套运行逻辑的几个关键节点,按照范围从大到小排列分别是:主题>规则>整理箱>线索;对照电脑上的文件管理模式,主题就等同于文件夹,规则就是Excel文件,整理箱就是一个Excel表,线索就是表里的行;登录集搜客官网进入到会员中心,用户可以看到爬虫、规则、线索、数据的管理模块,在这里您能够直观地监测到规则以及线索的采集情况,还能控制爬虫采集某个规则的周期、控制翻页数、设置增量采集最新数据、导出数据等等;强大又实用,需要的用户可以下载体验
软件功能
1、集成化图形界面
包括网页结构窗口、工作台、显示窗口等子窗口。选取被抓取内容时,三个子窗口联动,并显示HTML节点的重要属性
2、抓取规则自动生成
指定抓取内容,定义抓取结果存放结构(整理箱),然后将网页内容分别映射给整理箱中的抓取内容,MS谋数台即可自动生成抓取规则
3、原始网页内容纠错
网页的发布者在写网页的时候可能存在语法和词法错误,只要是火狐浏览器能打开的,都能定义抓取规则并进行抓取
软件特色
1、分词打标软件:自动分词,筛选词库、 开店选品,发掘营销关键词,行业研究、掌握话题要点
2、报表摘录软件:收集素材做笔记、采摘数据整理报表、写paper做研究的好帮手
3、智慧城市要素库:智慧城市海量数据库、 直接下载用于数据分析、数据分析课的好素材
4、通用网络爬虫
采用功能强大的火狐浏览器内核,所见即所得
安装步骤
1、需要的用户可以点击本网站提供的下载路径下载得到对应的程序安装包
2、通过解压功能将压缩包打开,找到主程序,双击主程序即可进行安装
3、用户可以根据自己的需要点击浏览按钮将应用程序的安装路径进行更改
4、快捷键选择可以根据自己的需要进行选择,也可以选择不创建
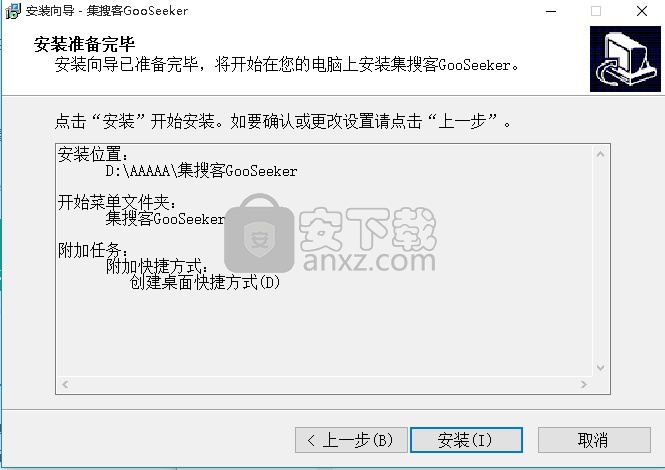
5、现在准备安装主程序。点击“安装”按钮开始安装或点击“上一步”按钮重新输入安装信息
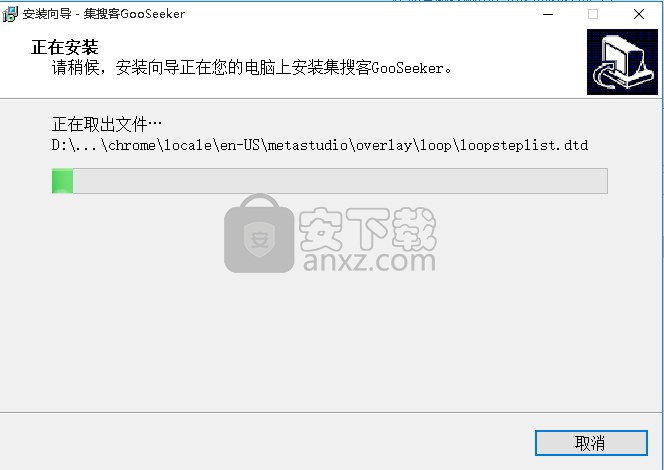
6、等待应用程序安装进度条加载完成即可,需要等待一小会儿
7、根据提示点击安装,弹出程序安装完成界面,点击完成按钮即可
8、程序安装完成后,双击程序打开,会弹出一个程序登录界面,输入对应的程序用户即可登录
9、没有账号的用户可以通过注册一个号码即可登录

10、登录后就可以进入主程序界面
使用说明
主题是用来抓取某一类网页的多个规则的集合,当某一类网页有多种网页结构时,比如淘宝的商品详情页面就有多种网页结构,这时,我们可以在同一个主题下建立多个规则,一个规则对应抓取一种网页结构,目的是为了覆盖到全部的网页结构,这样爬虫只要执行这个主题,就可以抓取到全部网页,
规则是从属于某一个主题,同一个主题下的规则是用不同规则编号来区分,它是对某种网页结构做映射而得到的爬虫程序,也就是说一种网页结构做一个规则就够了;如果主题下建立了多个规则,特别要注意,每个规则的整理箱里必须要采集一个特有的信息标志,用来让爬虫在抓取网页时,能根据这个标志判断出要使用哪个规则,
整理箱是从属于规则的,对网页信息做标注映射就可以得到一个树状目录结构的整理箱,说明整理箱是对应网页模块结构的。一个规则下面可以建立多个整理箱,各个整理箱可以对应网页上的不同模块,运行采集时就会同时执行多个整理箱的采集。例如,要抓取淘宝的商品详情页面,可以建立三个整理箱,第一个整理箱用来采集商品名、价格信息,第二个整理箱用来采集宝贝详情的图片,第三个整理箱用来采集店铺介绍,因为这三种信息是网页上的不同模块,如果全都放在一个整理箱抓取,就会抓取错位或遗漏,所以不同模块的信息最好是建立各自的整理箱来抓取。另一种需要建立多个整理箱的情况是,对于内嵌了iframe的网页,每一个iframe结构都要单独建立一个整理箱来采集,不能放到一个整理箱抓取。
线索就是我们常说的网址,网页结构相同的网址可以套用一个规则来采数据,可以手工把这些网址添加到规则中,再运行主题,就会逐条网址采集,这样就能批量采集一类网页信息,
除了手工添加线索,我们还有层级采集的方法可以把网址自动导入到规则里,从而实现批量采集,
怎样使用搜狐新闻搜索列表快捷工具抓取关键词搜索结果
针对常用的网站采集需求,集搜客网络爬虫用一系列快捷采集工具满足这些需求,这样,用户就不用花时间学习网络爬虫的使用方法,只需按照快捷工具的要求,输入要采集的网址并设置要采集的网页数量,把爬虫群窗口启动起来,爬虫就能自动运行,最后把采集到的结果打包下载出来 excel文件即可。
下面,以搜狐新闻搜索列表快捷采集工具为例,介绍怎样根据关键词,利用这些新闻类的快捷采集工具,把需要的新闻搜索到。
数据规则怎么看
数据规则就是随着标注和映射操作立刻生成的XSLT程序,它是集搜客网络爬虫采集网页数据的依据,主要涉及到xpath,大家在掌握html、xml、xpath的基础上,就能很好地理解XSLT程序。查看方法是做好规则后,再点击“测试”,在输出结果窗口里点击“数据规则”页签,如下图。
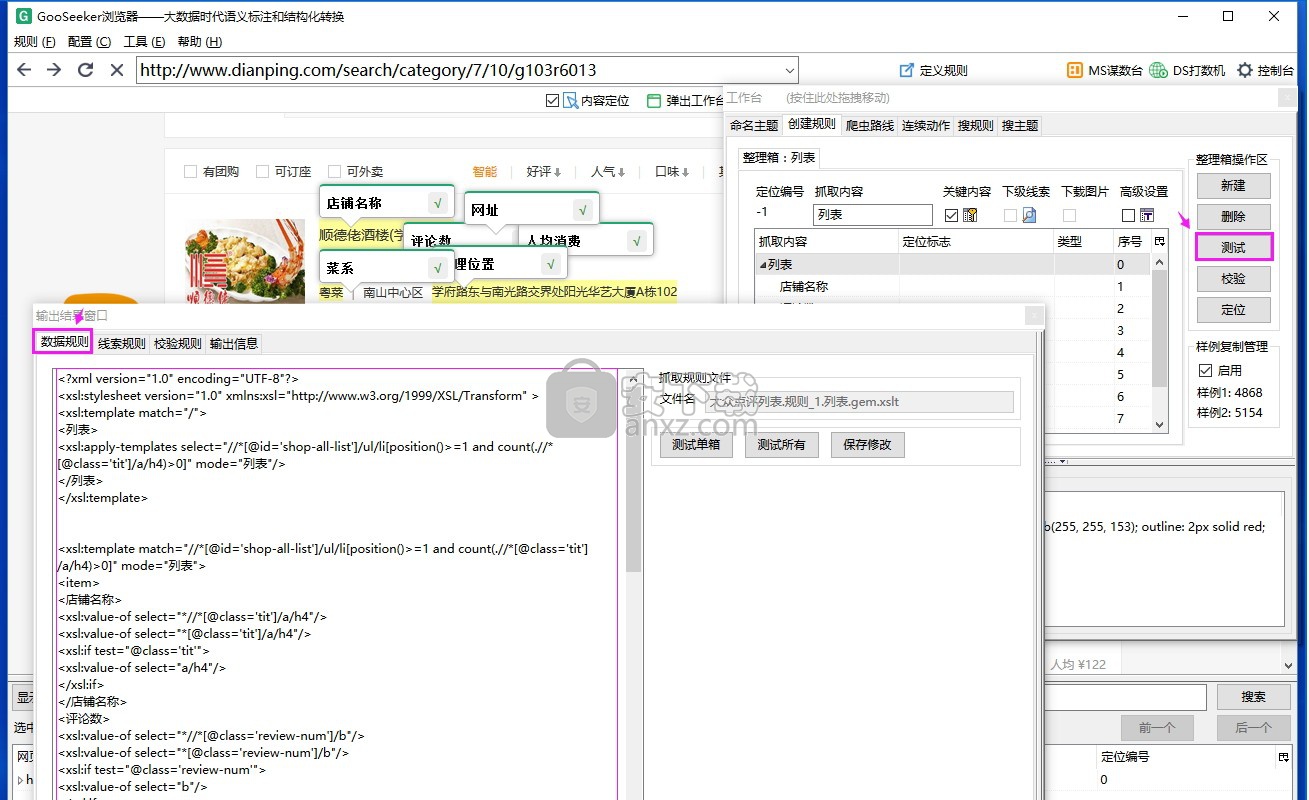
查看数据规则是为了能在原来的基础上优化程序,有很多实现的方法,例如对整理箱的抓取内容做定位标志映射或自定义xpath,这里就不细说了,下面讲解一下数据规则的结构。
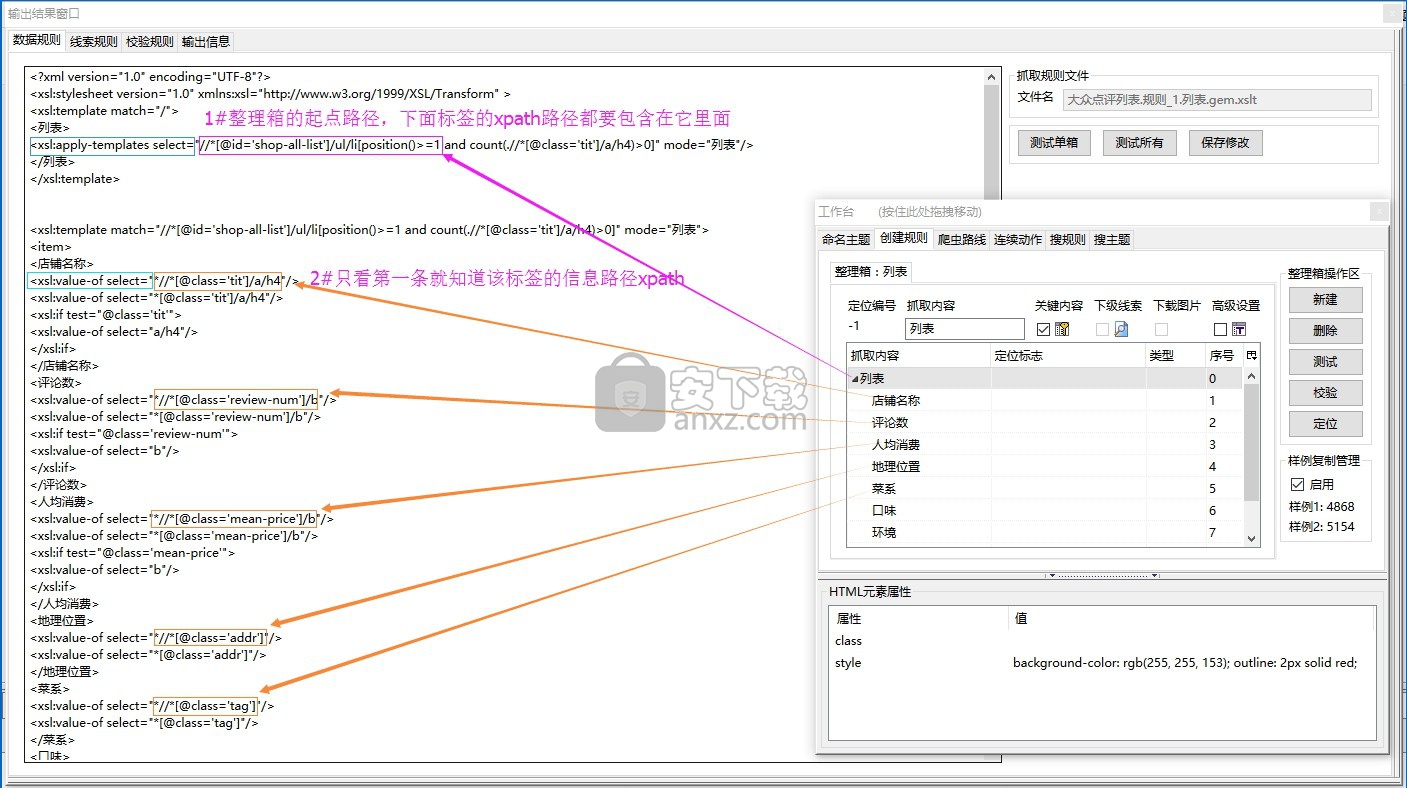
1、整理箱的起点路径
在xsl:apply-template select="***",双引号里面的第一个xpath路径就是整理箱的起点路径,and后面是勾了关键内容的标签的xpath路径。起点路径限定了整理箱的采集范围,其他标签的xpath路径必须包含在它里面,才可以被定位和采集。
2、每个标签的xpath路径
只要看标签下的第一条程序xsl:value-of select="***”,双引号里面就是它的xpath路径。
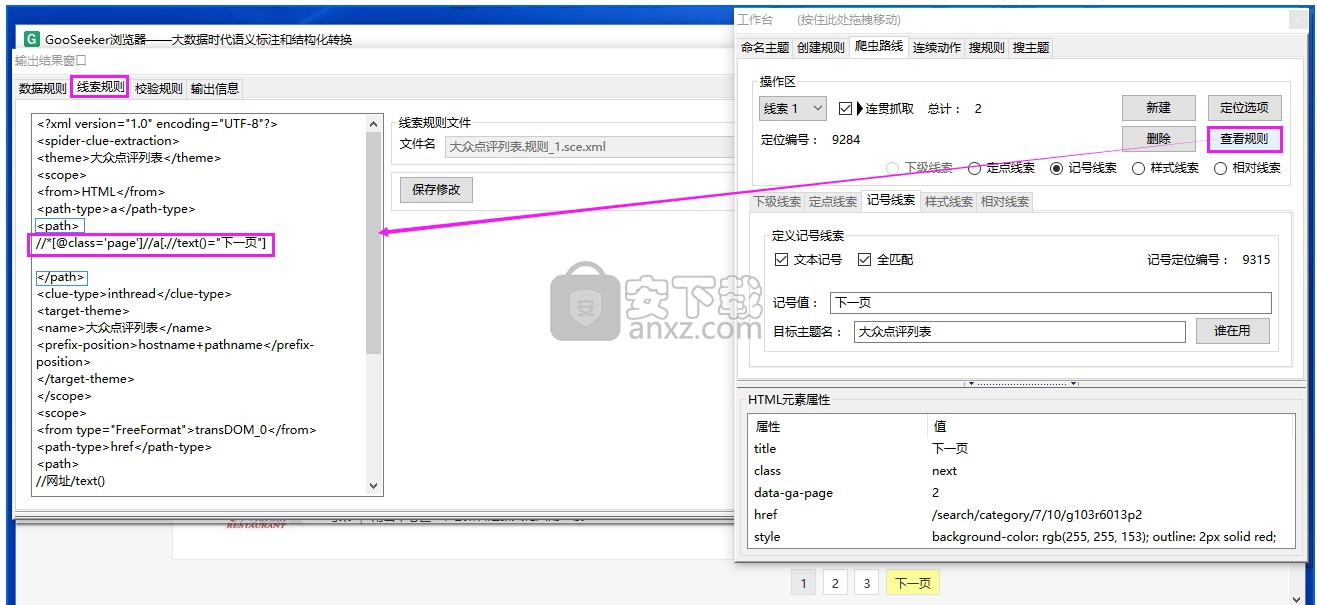
Tips1:爬虫路线也是有规则的,除下级线索外,设置其他类型的爬虫路线后,就会线索规则页签里生成一个路线程序。定义好爬虫路线后点击“查看规则”,在线索规则里,标签里面的就是该路线的xpath路径。
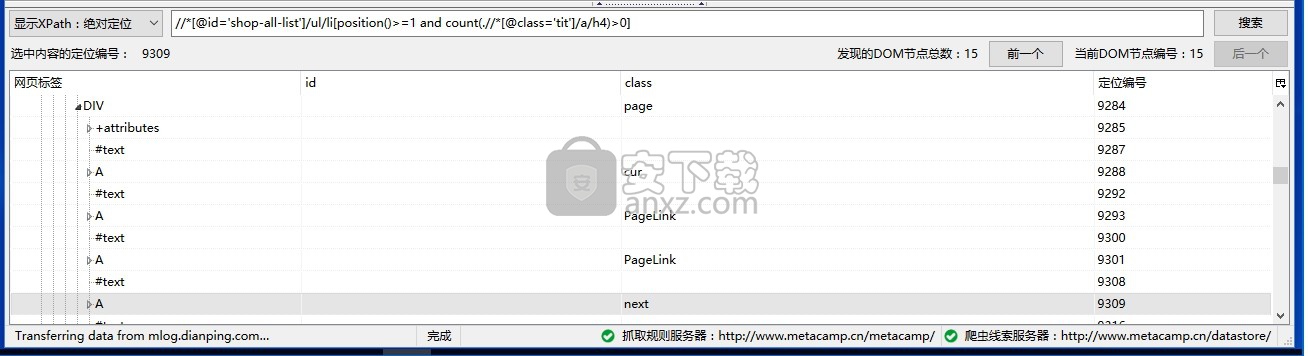
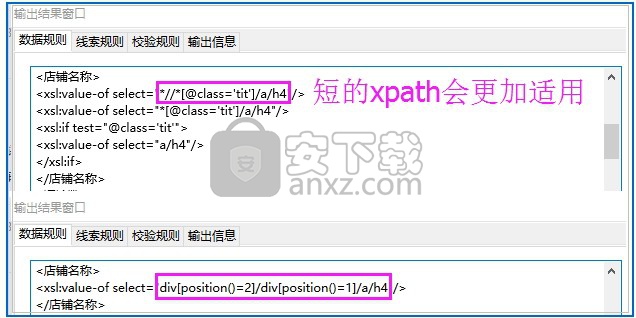
Tips2:无论是数据规则还是线索规则,得到的xpath都是越短越好,因为越短的xpath所查找的路径层级就越少,能大大减少由于网页结构变动而定位失败的情况,通常做定位标志映射可以优化xpath路径。
规划采集流程图
采集复杂页面的数据或者涉及多个页面的数据,首先要规划采集流程图,否则做规则的时候可能会无从下手。为了规划采集流程图,我们要清楚知道需要在浏览器做哪些动作才能得到目标信息。
下面以几个网页为例教大家规划采集流程图。
注意下面出现的流程图,左边是人在浏览器做的动作流程图,右边是仿照人的动作设计的采集流程图。
1.淘宝网
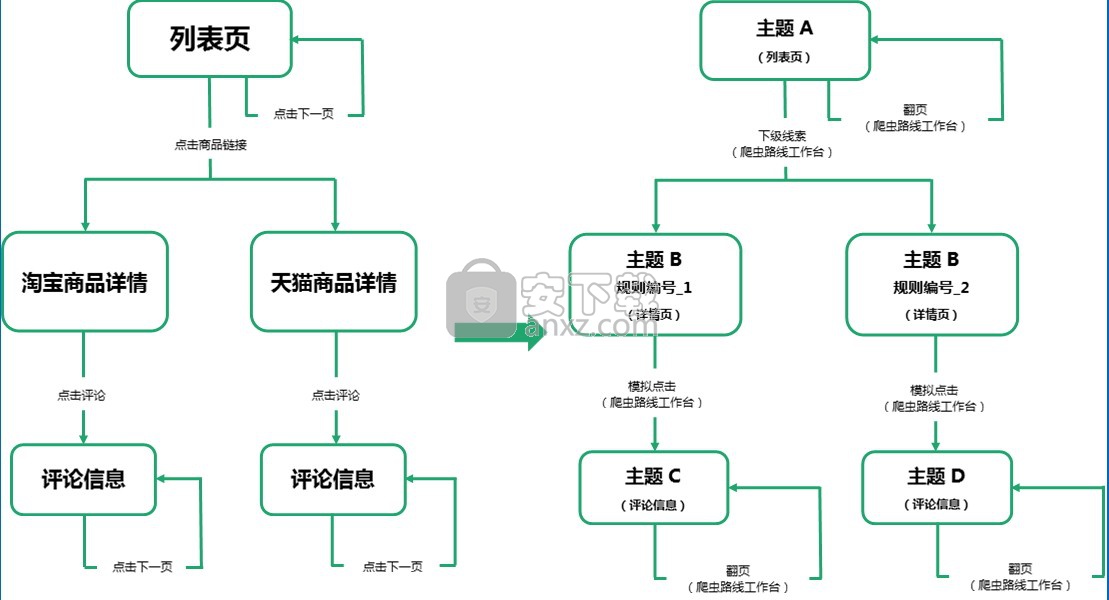
以淘宝网为例,我们从列表页开始,最终要采集每个商品的评论信息。
那我们在浏览器中做的是:从列表页点击商品的链接进入详情页(详情页分为淘宝详情页和天猫详情页两种),同时列表页还要点击下一页采集每页数据;进入详情页后需要点一下评论才能看到评论信息,再点击下一页翻看后面评论信息。
对于在浏览器做的一系列动作可以用左下的流程图表示,而定义规则就是要告诉软件要做的就是这些动作,对于GooSeeker而言,点击链接进入下一级页面就是设置层级抓取(即定义下级线索),点击评论但是网址不变就做模拟点击,点击翻页就是设置翻页线索。于是我们可以得到完整的采集流程图如右下图所示。
2.中国知网
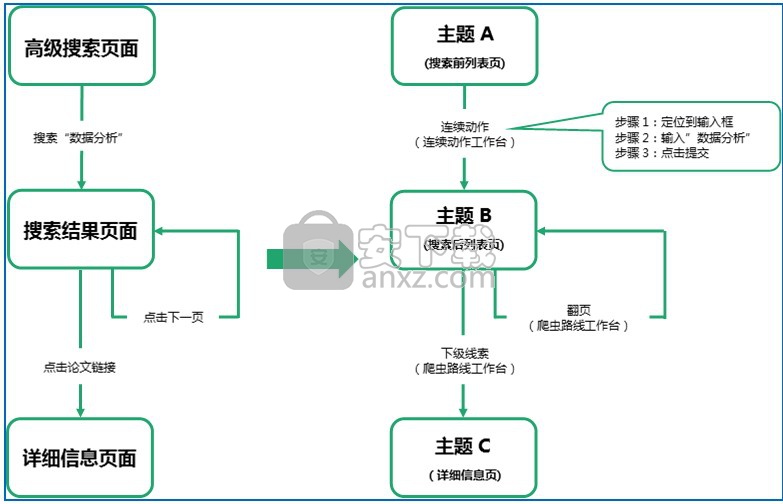
以中国知网为例,从高级搜索页面开始,要得到关于“数据分析”的论文的作者、摘要等信息。
那我们在浏览器做的操作就是:在高级搜索页面,搜索“数据分析”得到相关论文,点击论文链接进入到详细信息页,同时要在搜索结果列表点击下一页查看所有论文。
人在浏览器做的动作如左下的流程图,而对于软件而言,由于搜索后网址不变且需要三个动作(点击搜索框->输入“数据分析”->提交)才完成搜索,所以要用连续动作来模拟这些鼠标操作,点击论文链接进入到详细信息页要做层级抓取(即定义下级线索),另外,把搜索出来的每一页论文都采集下来,就需要定义翻页线索。于是我们可以得到完整的采集流程图如右下图所示。
3.新浪微博
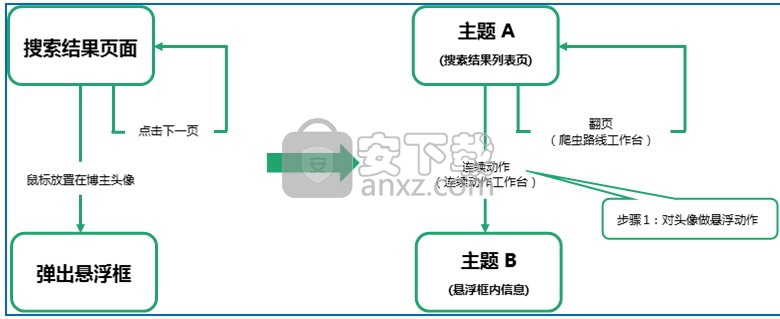
以新浪微博为例,我们要在微博搜索的找人页面上搜索标签包含“电商”的博主,当鼠标放置在博主头像上,会悬浮弹出博主详细信息框,我们希望把那些信息也采集下来,这就需要对每个博主头像都做一次悬浮动作,另外,我们还希望把每一页的博主信息都采集下来,这就需要翻页动作。
人的动作流程图和采集流程图如下所示。
注意:对于一个同时存在连续动作和翻页的规则,会先执行连续动作再执行翻页。
xml转换为excel
集搜客网络爬虫采集下来的结果数据是用XML文件存的,如果要转换成Excel格式,需要用到爬虫的导入和导出功能。导入数据的方法又分成手工导入和自动导入两种情况。
做完采集规则后,点击爬数据或者DS打数机上的单搜或者集搜按钮,这样采集下来的数据是不会自动导入的,需要按照本教程讲解的方法导入数据。
对规则设置了调度,而且勾选了自动入库,或者使用微博采集工具箱和快捷采集工具,那么都会自动导入,用户只需在规则管理那里导出数据即可。
通过会员中心使xml格式转为excel格式,手工导入导出的操作步骤如下:(注意控制ZIP包的大小)
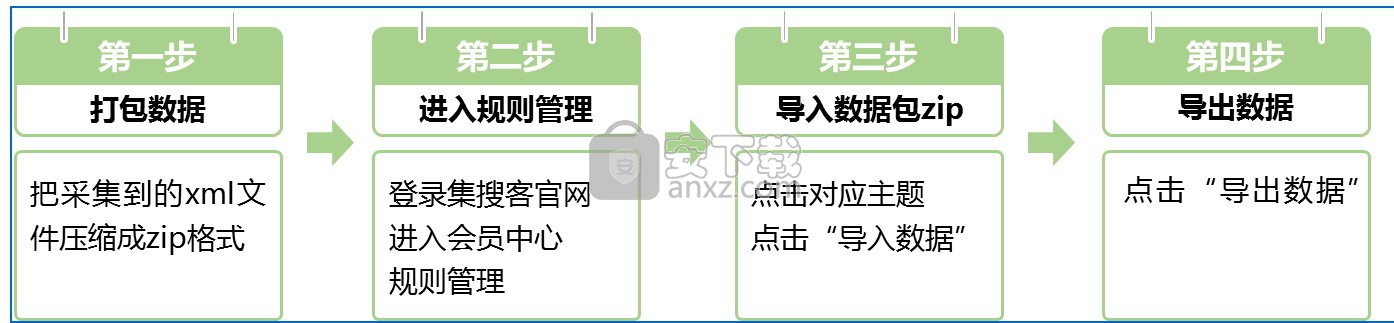
二、手工导入操作步骤
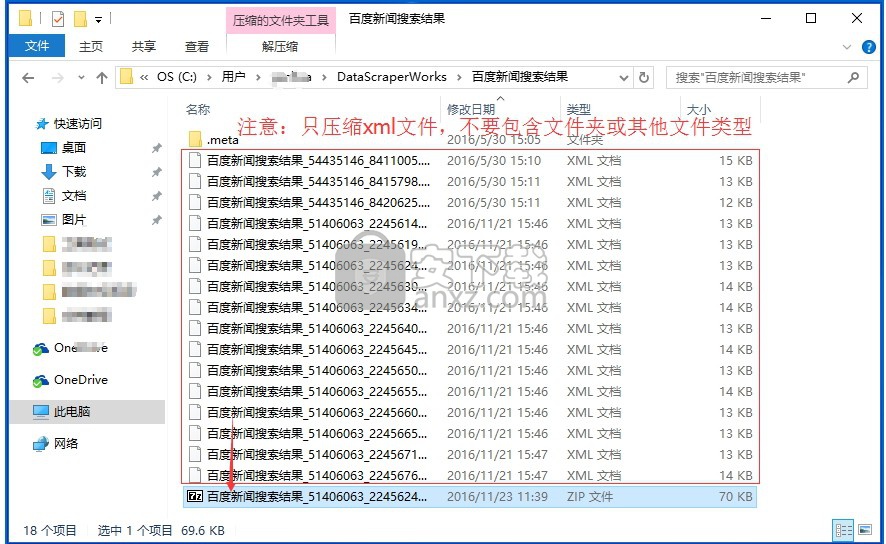
打数机采集下来的数据,一页一个XML文件,存放在硬盘的DataScraperWorks目录下,相应主题名文件夹里。
1,在硬盘的主题名文件夹里选中多个xml文件直接压缩到zip包,不要夹杂除xml外的文件夹或其他文件类型。
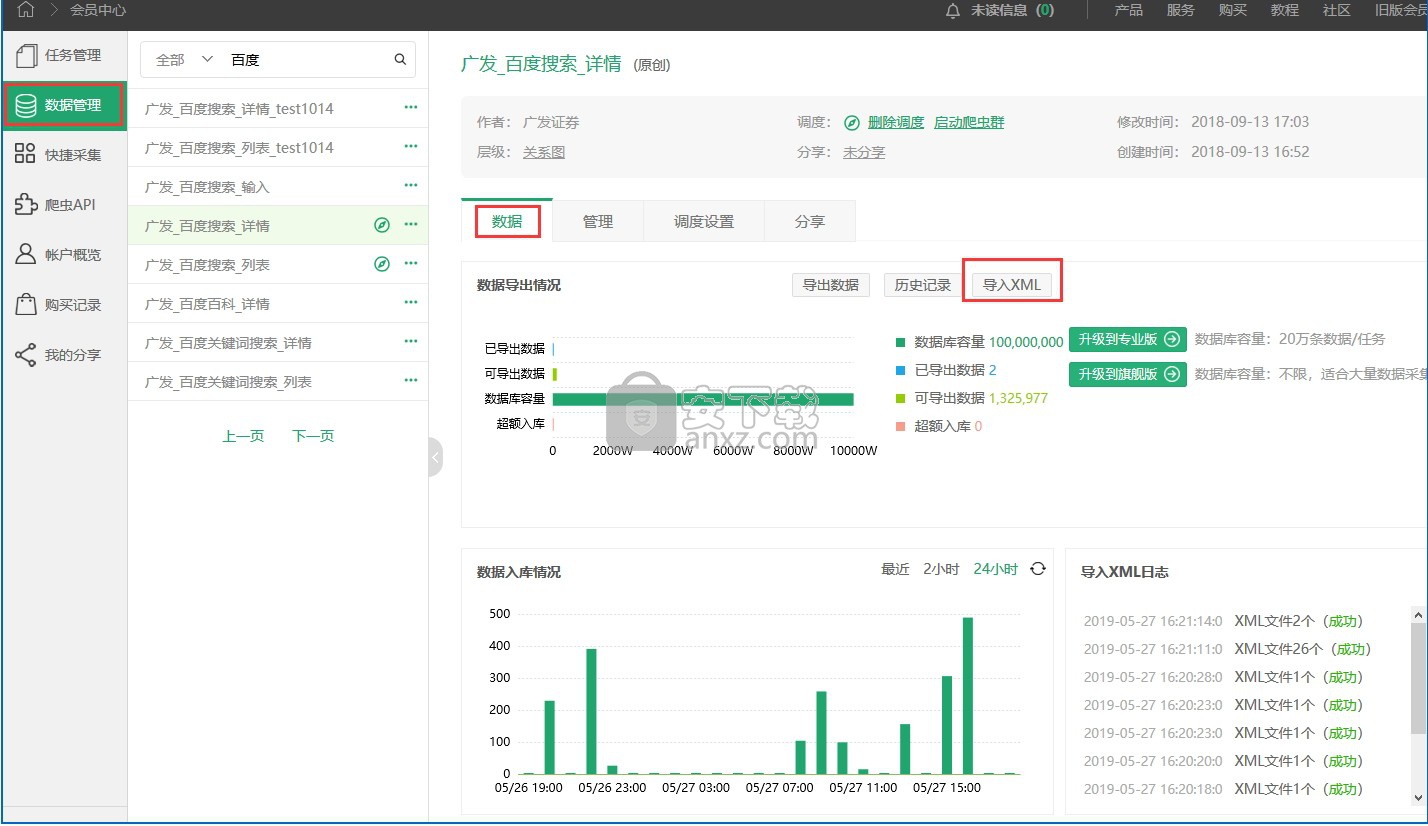
2,登录集搜客官网,进入会员中心->任务管理。
3,点击对应的任务名进入到该任务的管理页面,点击“数据”按钮->“导入XML”,选择XML的压缩包zip,导入。
4,导入成功后即可“导出数据”,在“历史记录”中可以重复下载。下载的数据,默认保存在本地的下载目录。
注意:ZIP包不能大于10M,为了稳定上传,最好分批压缩成多个2M的包。
【注意】数据管理功能是增值服务,每个规则可以免费导出1万条数据,超额,会提示购买“专业版or旗舰版爬虫”。
三、自动导入操作步骤
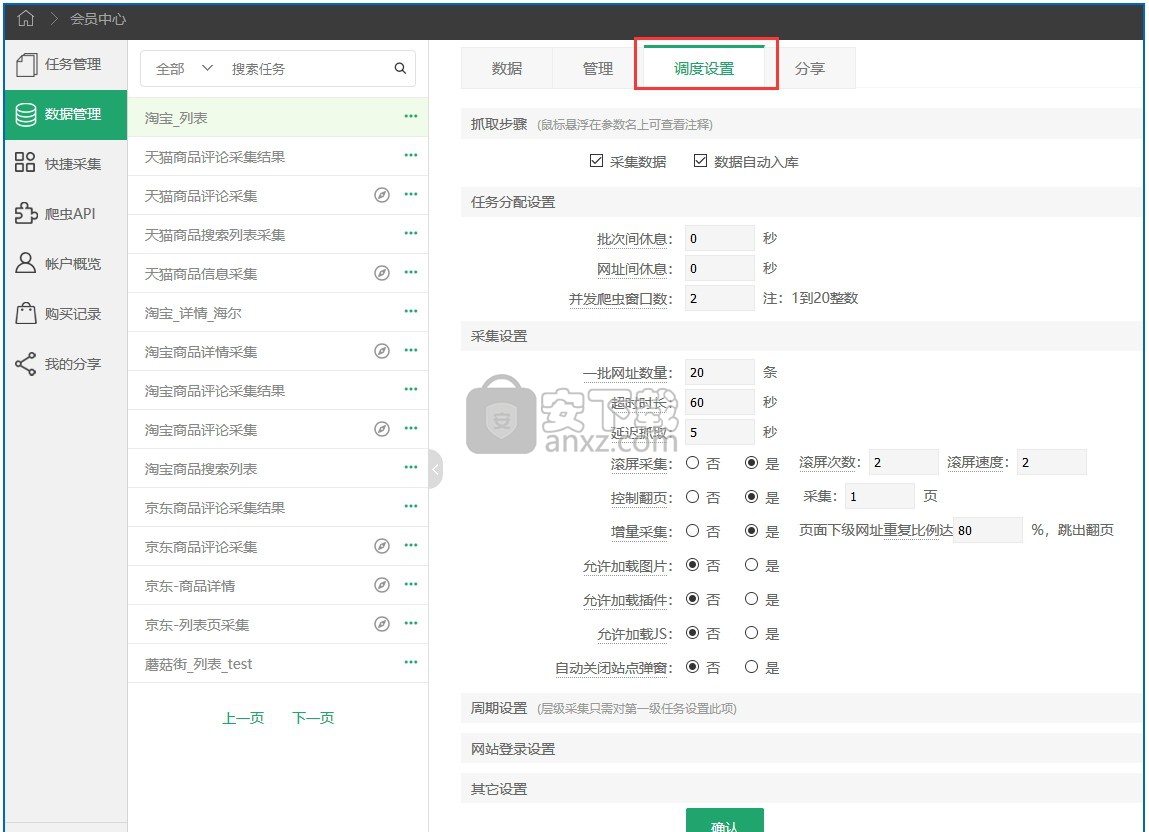
在会员中心给自己做的规则设置调度,而且勾选了自动入库,如果运行起来爬虫群模式,爬虫群就能自动入库。
人气软件
-

redis desktop manager2020.1中文 32.52 MB
/简体中文 -

s7 200 smart编程软件 187 MB
/简体中文 -

GX Works 2(三菱PLC编程软件) 487 MB
/简体中文 -

CIMCO Edit V8中文 248 MB
/简体中文 -

JetBrains DataGrip 353 MB
/英文 -

Dev C++下载 (TDM-GCC) 83.52 MB
/简体中文 -

TouchWin编辑工具(信捷触摸屏编程软件) 55.69 MB
/简体中文 -
信捷PLC编程工具软件 14.4 MB
/简体中文 -

TLauncher(Minecraft游戏启动器) 16.95 MB
/英文 -

Ardublock中文版(Arduino图形化编程软件) 2.65 MB
/简体中文
 Embarcadero RAD Studio(多功能应用程序开发工具) 12
Embarcadero RAD Studio(多功能应用程序开发工具) 12  猿编程客户端 4.16.0
猿编程客户端 4.16.0  VSCodium(VScode二进制版本) v1.57.1
VSCodium(VScode二进制版本) v1.57.1  aardio(桌面软件快速开发) v35.69.2
aardio(桌面软件快速开发) v35.69.2  一鹤快手(AAuto Studio) v35.69.2
一鹤快手(AAuto Studio) v35.69.2  ILSpy(.Net反编译) v8.0.0.7339 绿色
ILSpy(.Net反编译) v8.0.0.7339 绿色  文本编辑器 Notepad++ v8.1.3 官方中文版
文本编辑器 Notepad++ v8.1.3 官方中文版 






