

FlatBuffers(序列化库)
v2.0.0 官方版- 软件大小:1.95 MB
- 更新日期:2021-05-15 11:16
- 软件语言:英文
- 软件类别:编程工具
- 软件授权:免费版
- 软件官网:待审核
- 适用平台:WinXP, Win7, Win8, Win10, WinAll
- 软件厂商:

软件介绍 人气软件 下载地址
FlatBuffers是一款序列化库,您可以在开发游戏或者上开发其他软件的时候使用这款软件提升数据访问效率,软件主要的优势就是在不解析/解包的情况下访问序列化数据,让数据读取更加快速,对于需要读取庞大数据资源的游戏来说非常有帮助,软件支持很多语言编辑,可以将其部署到任意平台开发,您可以为自己的软件附加序列化数据读取功能,解决数据读取效率慢的问题,软件可以使用的场景非常多,例如开源移动游戏引擎Cocos2d-x使用它来序列化所有游戏数据,例如通讯软件、网站平台可以通过这款软件提升数据读取效率,提升加载网站帖子的速度,如果你需要这款软件就下载吧!
软件功能
1、在不解析/解包的情况下访问序列化数据
FlatBuffers与众不同之处在于,它在平坦的二进制缓冲区中表示层次结构数据,使得即使不进行解析/解包也可以直接访问分层数据,同时还支持数据结构的演进(forward /向后兼容)。
2、内存效率和速度
访问数据所需的唯一内存是缓冲区的内存。它需要0个额外的分配(在C ++中,其他语言可能会有所不同)。FlatBuffers也非常适合与mmap(或流)一起使用,仅要求将部分缓冲区存储在内存中。访问仅通过一个额外的间接调用(一种vtable)即可接近原始结构访问的速度,以允许格式演变和可选字段。它针对那些不希望花费时间和空间(许多内存分配)来访问或构造序列化数据的项目,例如在游戏或任何其他对性能敏感的应用程序中。
3、灵活
可选字段不仅意味着您具有很好的前后兼容性(对于长寿命游戏也越来越重要:不必使用每个新版本更新所有数据!)。这也意味着您在写入哪些数据,不写入哪些数据以及如何设计数据结构方面有很多选择。
4、微小的代码占用空间
生成的代码量很少,只有一个小的标头作为最小的依赖项,非常易于集成。同样,请参阅基准测试部分以了解详细信息。
5、强类型
错误发生在编译时,而不是手动编写重复且容易出错的运行时检查。可以为您生成有用的代码。
6、使用方便
生成的C ++代码允许简洁的访问和构造代码。然后是可选功能,可以在需要时在运行时高效地解析模式和类似JSON的文本表示形式(比其他JSON解析器更快,更高效地使用内存)。
Java,Kotlin和Go代码支持对象重用。C#具有高效的基于结构的访问器。
7、无需依赖项的跨平台代码
C ++代码可与任何最新的gcc / clang和VS2010一起使用。随附用于测试和示例的构建文件(Android .mk文件,以及用于所有其他平台的cmake)。
软件特色
FlatBuffers是跨平台序列化库,旨在最大程度地提高内存效率。它使您可以直接访问序列化的数据,而无需先解析/拆包,同时仍具有很好的前向/向后兼容性。
支持的编程语言
C++
C#
C
Dart
Go
Java
JavaScript
Lobster
Lua
PHP
Python
Rust
TypeScript
官方教程
在C中使用
C语言绑定存在于名为FlatCC的单独项目中。
该flatccÇ模式编译器可以通过一个C库在线生成代码下线为好。它还可以生成缓冲区验证器和快速JSON解析器,打印机。
已经采取了非常谨慎的措施来确保与主要flatc项目的兼容性。
支持平台
Ubuntu(clang / gcc,ninja / gnu make)
OS-X(c语/ gcc,忍者/ gnu make)
Windows MSVC 2010、2013、2015年
CI在OS-X,Ubuntu和Windows上构建gcc,clang和MSVC的最新版本,并偶尔编译较旧的编译器版本。请参阅主要项目状态。
包括Centos在内的其他平台也可能工作良好,但未经过定期测试。
Monster示例项目是专门为C99编写的,以遵循C ++版本,因此,该示例项目不适用于MSVC 2010。
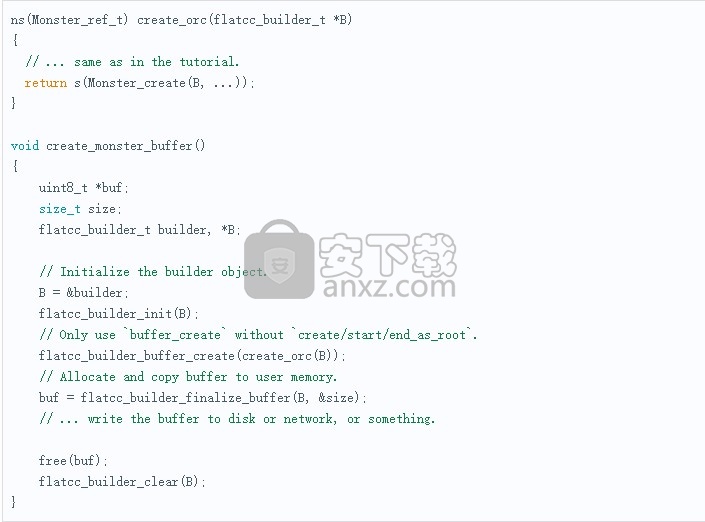
模块化对象创建
在本教程中,我们使用了调用Monster_create_as_root来创建根缓冲区对象,因为在简单的用例中,这更容易。有时我们需要更多的模块化,因此我们可以重复使用函数以相同的方式创建嵌套表和根表。为此,我们需要flatcc_builder_buffer_create_call。最好将flatcc_builder呼叫隔离在最高驱动程序级别,这样我们得到:
在自顶向下方法中,start/endvs适用相同的原理start/end_as_root。
自上而下的例子
本教程使用自下而上的方法。在C语言中,通过开始和结束彼此嵌套的对象,也可以使用自顶向下的方法。在本教程中,没有深层嵌套,因此差异是有限的,但是它说明了这一点:

基本思考
C-API确实支持通过从reflection.fbs架构生成的代码读取二进制架构(.bfbs)文件,示例用法说明了如何使用此文件。反射模式文件是在运行时分发中预先生成的。
变异与反思
C-API不像C ++一样支持变异反射,阅读器接口也不支持变异标量(而且即使在验证之后,这样做也是不安全的)。
生成的读取器接口在将向量强制转换为变异类型后支持就地排序向量,因为在构建缓冲区时这样做并不实际。构建器文档中对此进行了介绍。
反射示例利用此功能按名称查找对象。
可以使用现有缓冲区中的复杂对象作为源来构建新缓冲区。由于直接复制语义而无需字节序转换或临时堆栈分配,因此这可能非常有效。
标量,结构和字符串以及它们的向量都可以用作源。
当前不可能使用现有的表或表的向量作为源,但是有可能在某个时候添加对此的支持。
命名空间
FLATBUFFERS_WRAP_NAMESPACE当每个函数都有一个很长的名称空间前缀时,本教程中使用的方法很方便。但这并不总是最好的方法。如果名称空间不存在,或者简单而内容丰富,那么我们不妨直接使用前缀。上面提到的反射示例使用此方法。
检查现有成员
并非所有语言都支持对是否存在字段的测试,但是在C语言中,我们可以通过测试详细说明本教程的阅读器部分。记得将mana其设置为默认值150,因此不应存在。

添加工会的替代方法
在本教程中,我们使用了一个调用来添加联合。在这里,我们展示了完成同一件事的不同方法。最后一种形式很少使用,但这是底层的实现方式。通过在不同时间点添加类型和数据,可以将表中的小值分组在一起。

为什么不与 flatc 工具集成?
考虑了如何将C代码生成器集成到flatc工具中,但是它要么要求删除模式编译器的独立C实现,否则将导致过多的代码重复,或者必须使用复杂的中间表示形式。发明的。这两种选择都不是很吸引人,使用flatcc工具代替使用flatcFlatBuffers C运行时库也没什么大不了的。
编写模式
模式语言(又名IDL,接口定义语言)的语法对于任何C语言族的用户和其他IDL的用户都应该非常熟悉。让我们先来看一个例子:
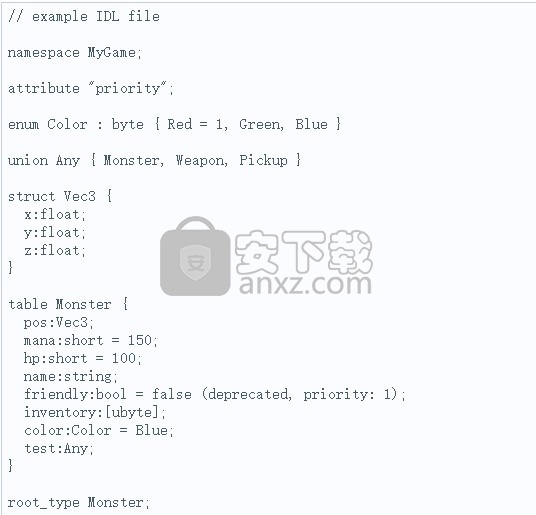
表
表是在FlatBuffers中定义对象的主要方式,由名称(此处为Monster)和字段列表组成。每个字段都有一个名称,类型和可选的默认值。如果未在架构中指定默认值,则它将0用于标量类型或null其他类型。某些语言支持将标量默认设置设置为null。这使得标量是可选的。
字段不必出现在导线表示中,并且可以在构造对象时选择忽略字段。您可以灵活地添加字段,而不必担心数据膨胀。此设计也是FlatBuffer的向前和向后兼容性的机制。注意:
您只能在表定义的末尾在架构中添加新字段。较旧的数据仍将正确读取,并在读取时为您提供默认值。较旧的代码将仅忽略新字段。如果要灵活地对架构中的字段使用任何顺序,可以手动分配ID(与协议缓冲区类似),请参见id下面的属性。
您无法从架构中删除不再使用的字段,但是您可以停止将它们写入数据中以达到几乎相同的效果。另外,您可以像deprecated上面的示例中那样标记它们,这将防止在生成的C ++中生成访问器,作为强制不再使用该字段的方法。(注意:这可能会破坏代码!)。
您可以更改字段名称和表名称,如果可以的话,可以使用代码中断功能,直到您也将其重命名为止。
结构
类似于表,仅现在所有字段都不是可选的(因此也没有默认值),并且可能不会添加或弃用字段。结构只能包含标量或其他结构。将其用于简单的对象,这些对象您可以确定不会进行任何更改(在示例中非常清楚Vec3)。结构使用的内存少于表,并且访问速度甚至更快(它们始终以内联方式存储在其父对象中,并且不使用虚拟表)。
种类
内置标量类型为
8位:byte( int8),ubyte(uint8),bool16位:short(int16),ushort(uint16)
32位:int(int32),uint(uint32),float(float32)
64位:long(int64),ulong(uint64),double(float64)
括号中的类型名称是别名,例如uint8可以代替ubyte,并且int32可以代替int而不影响代码生成。
内置非标量类型:
任何其他类型的向量(以表示[type])。不支持嵌套向量,而是可以将内部向量包装在表中。
string,可能只包含UTF-8或7位ASCII码。对于其他文本编码或常规二进制数据,请使用向量([byte]或[ubyte])。
对其他表或结构,枚举或联合的引用(请参见下文)。
一旦使用了字段,就无法更改字段类型,但相同大小的数据除外,其中areinterpret_cast会给您带来理想的结果,例如uint,int如果当前数据中还没有值使用高位,则可以将a更改为a 。
数组
数组是固定长度元素集合的便捷捷径。数组可用于替换以下架构:
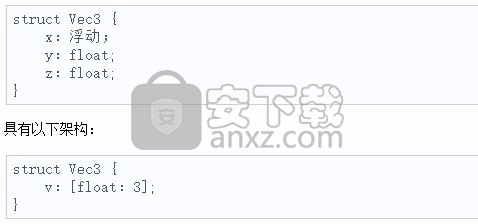
两种表示形式都是二进制等效的。
目前仅在中支持数组struct。
人气软件
-

redis desktop manager2020.1中文 32.52 MB
/简体中文 -

s7 200 smart编程软件 187 MB
/简体中文 -

GX Works 2(三菱PLC编程软件) 487 MB
/简体中文 -

CIMCO Edit V8中文 248 MB
/简体中文 -

JetBrains DataGrip 353 MB
/英文 -

Dev C++下载 (TDM-GCC) 83.52 MB
/简体中文 -

TouchWin编辑工具(信捷触摸屏编程软件) 55.69 MB
/简体中文 -
信捷PLC编程工具软件 14.4 MB
/简体中文 -

TLauncher(Minecraft游戏启动器) 16.95 MB
/英文 -

Ardublock中文版(Arduino图形化编程软件) 2.65 MB
/简体中文
 Embarcadero RAD Studio(多功能应用程序开发工具) 12
Embarcadero RAD Studio(多功能应用程序开发工具) 12  猿编程客户端 4.16.0
猿编程客户端 4.16.0  VSCodium(VScode二进制版本) v1.57.1
VSCodium(VScode二进制版本) v1.57.1  aardio(桌面软件快速开发) v35.69.2
aardio(桌面软件快速开发) v35.69.2  一鹤快手(AAuto Studio) v35.69.2
一鹤快手(AAuto Studio) v35.69.2  ILSpy(.Net反编译) v8.0.0.7339 绿色
ILSpy(.Net反编译) v8.0.0.7339 绿色  文本编辑器 Notepad++ v8.1.3 官方中文版
文本编辑器 Notepad++ v8.1.3 官方中文版 






