

spaCy(句法解析器)
v3.0.4 官方版- 软件大小:9.49 MB
- 更新日期:2021-03-12 10:06
- 软件语言:英文
- 软件类别:编程工具
- 软件授权:免费版
- 软件官网:待审核
- 适用平台:WinXP, Win7, Win8, Win10, WinAll
- 软件厂商:

软件介绍 人气软件 下载地址
spaCy提供句法解析功能,您可以在软件上分析语法,可以建立多种变压器管道分析语法,让软件可以准确解析句法,对于优化项目非常有帮助,软件提供非常多的组件进行分析,您可以根据自己的项目配置管道组件建立可视化的分析方案,建立神经网络模型分析方案,将分析流程添加到可视化的界面执行解析,为分析大型项目提供更多自由组合模型,方便对更多工作流分析,软件提供新的培训和配置系统、新的内置组件、新的自定义组件API、新方法和属性,为用户解析句法提供更多帮助,如果你需要这款软件就下载吧!
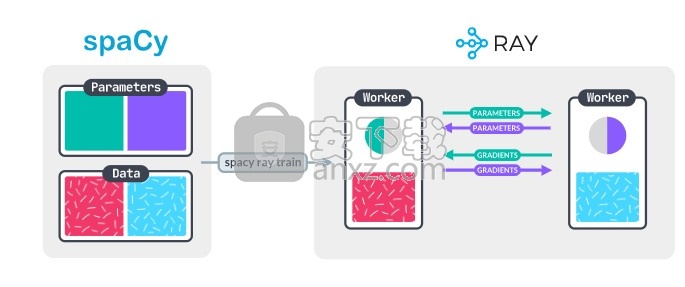
基本介绍
spaCy是用于Python和Cython中高级自然语言处理的库。它基于最新的研究,从第一天开始就设计用于实际产品中。
spaCy带有预训练的管道,目前支持60多种语言的标记化和训练。它具有用于标记,解析,命名实体识别,文本分类等的最新速度和神经网络模型,具有像BERT这样的预训练变压器的多任务学习,以及可用于生产的训练系统和简单模型包装,部署和工作流管理。spaCy是商业开放源代码软件,根据MIT许可发行。
软件功能
支持60多种语言
经过训练的管道可以处理不同的语言和任务
使用像BERT这样的预训练变压器进行多任务学习
支持预训练的单词向量和嵌入
最先进的速度
生产就绪培训系统
语言驱动的标记化
用于命名实体识别,词性标记,依存关系分析,句子分段,文本分类,词义化,形态分析,实体链接等的组件
使用自定义组件和属性可轻松扩展
支持PyTorch,TensorFlow和其他框架中的自定义模型
内置用于语法和NER的可视化工具
易于模型打包,部署和工作流管理
稳健,经过严格评估的精度
软件特色
项目模板
spaCy项目使您可以管理和共享针对不同用例和域的端到端spaCy工作流,并协调培训,打包和服务自定义管道。您可以从克隆预定义的项目模板开始,根据需要对其进行调整,加载数据,训练管道,将其导出为Python包,将输出上传到远程存储并与团队共享结果。
1、pipelines:用于训练在不同语料库上具有不同组件的NLP管道的模板。
2、tutorials:端到端通过特定NLP用例工作的模板。
3、integrations:模板显示了与第三方库和工具的集成,这些工具用于管理数据和实验,迭代演示和原型并将模型交付生产。
4、benchmarks:模板可重现我们的基准并产生可量化的结果,这些结果可轻松与其他系统或spaCy版本进行比较。
5、experimental:实验性工作流程和其他前沿工具需要您自担风险。
使用说明
点子
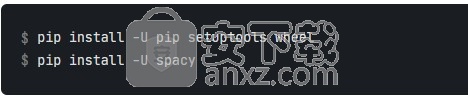
使用pip,可将spaCy版本作为源包和二进制文件提供。您安装spaCy及其依赖之前,请确保您的pip, setuptools并且wheel是最新的。
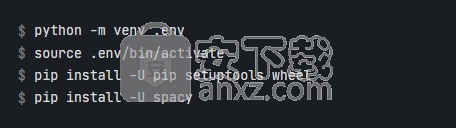
使用pip时,通常建议在虚拟环境中安装软件包,以避免修改系统状态:
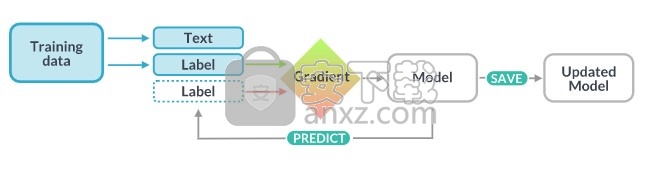
培训管道和模型
根据您自己的数据训练和更新组件,并集成自定义模型
spaCy的标记器,解析器,文本分类器和许多其他组件均由统计模型提供支持。这些组件的每个“决定”(例如,要分配的词性标签或单词是否是命名实体)都是基于模型当前权重值的预测。权重值是根据模型在训练过程中看到的示例进行估算的。要训练模型,您首先需要训练数据–文本示例,以及您希望模型预测的标签。这可以是词性标签,命名实体或任何其他信息。
训练是一个反复的过程,在该过程中,将模型的预测与参考注释进行比较,以估算损失的梯度。损耗的梯度然后用于通过反向传播计算权重的梯度。渐变指示应如何更改权重值,以使模型的预测随着时间的推移变得与参考标签更加相似。
在训练模型时,我们不仅希望它记住我们的示例,而且还希望它提出一个可以在看不见的数据上推广的理论。毕竟,我们不仅希望模型得知此处的“ Amazon”实例是一家公司,我们还希望其了解“ Amazon”在这种情况下极有可能是一家公司。因此,培训数据应始终代表我们要处理的数据。在Wikipedia上训练的模型(其中第一人称的句子非常少见)可能会在Twitter上表现不佳。同样,接受浪漫小说训练的模型在法律文字上的表现可能也会很差。
这也意味着,要了解模型的性能以及是否在学习正确的东西,您不仅需要训练数据,还需要评估数据。如果仅使用训练有据的数据来测试模型,那么您将不知道其概括性如何。如果您想从头开始训练模型,通常至少需要数百个例子来进行训练和评估。

如果您需要标记大量数据,请查看Prodigy,这是我们开发的一种新的,具有主动学习功能的注释工具。 Prodigy快速且可扩展,并带有一个现代化的Web应用程序,可帮助您更快地收集训练数据。它与spaCy无缝集成,预先选择最相关的示例进行注释,并允许您训练和评估即用型spaCy管道。
快速入门新
推荐的SpaCy管道训练方法是通过命令行上的spacy train命令。 它只需要一个包含所有设置和超参数的config.cfg配置文件。 您可以选择在命令行上覆盖设置,并加载到Python文件中以注册自定义功能和体系结构。 此快速入门小部件可帮助您生成具有针对特定用例的建议设置的启动器配置。 在spaCy中,它也可以作为init config命令使用。
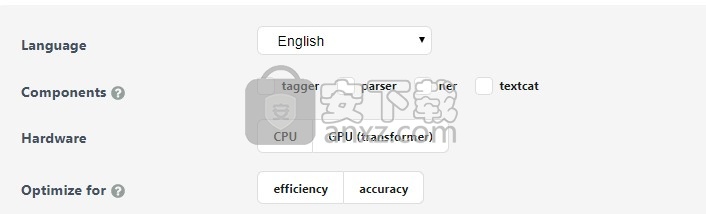
层和模型架构
通过自定义神经网络为SpaCy组件供电
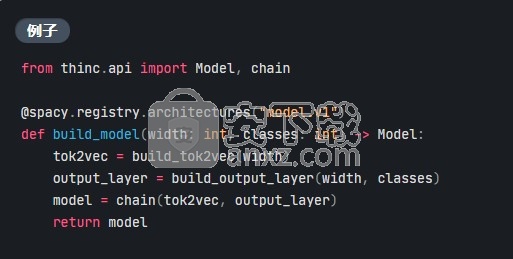
甲模型体系结构是一个函数,导线了 THINCModel实例。它描述了作为spaCy管道中组件的一部分在内部运行的神经网络。要定义实际的体系结构,可以直接在Thinc中实现逻辑,也可以将Thinc用作围绕PyTorch,TensorFlow和MXNet等框架的精简包装。每个Model都还可以用作较大网络的子层,从而使您可以将来自不同框架的实现自由组合到一个模型中。
spaCy的内置组件需要Model通过配置系统将实例传递给它们。要更改现有组件的模型架构,您只需要更新配置,使其引用其他注册功能即可。通过此配置创建组件后,您将无法再对其进行更改。该体系结构就像是网络的配方,一旦准备好菜就无法更改配方。您必须重新制作一个。
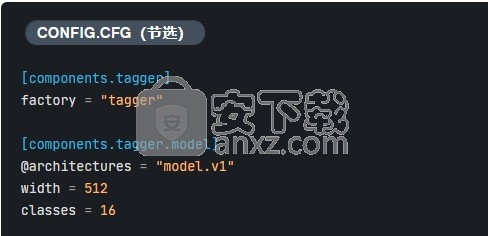
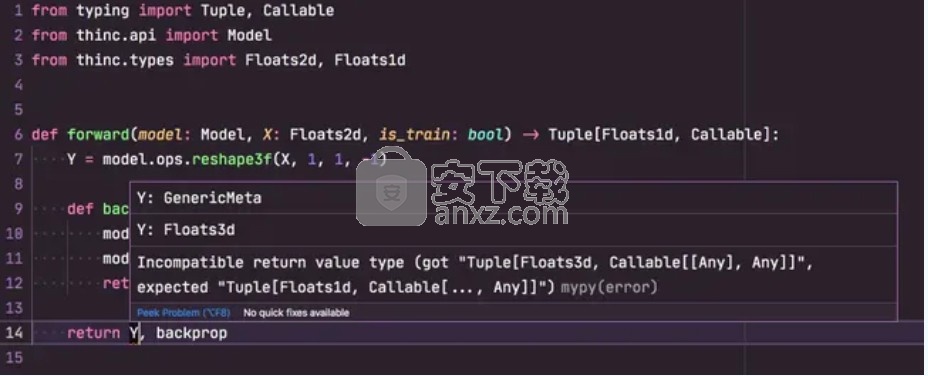
不能保证具有相同类型签名的两个模型可以互换使用。它们还有许多不兼容的其他方式。但是,如果类型不匹配,则几乎肯定不会兼容。验证的过程大有帮助,特别是如果您 配置了编辑器或其他工具以及早突出显示这些错误。训练开始时还将对配置文件进行验证,以验证所有类型是否正确匹配。
提示:在编辑器中进行静态类型检查
如果您使用的是像Visual Studio Code这样的现代编辑器,则可以使用自定义Thinc插件进行 设置,mypy并在编写代码时获得有关不匹配类型的实时反馈。
交换模型架构
如果没有为 TextCategorizer, 这 TextCatEnsemble默认情况下使用体系结构。这种体系结构将简单的词袋模型与神经网络结合在一起,通常可以得到最准确的结果,但要以速度为代价。该模型的配置文件如下所示:
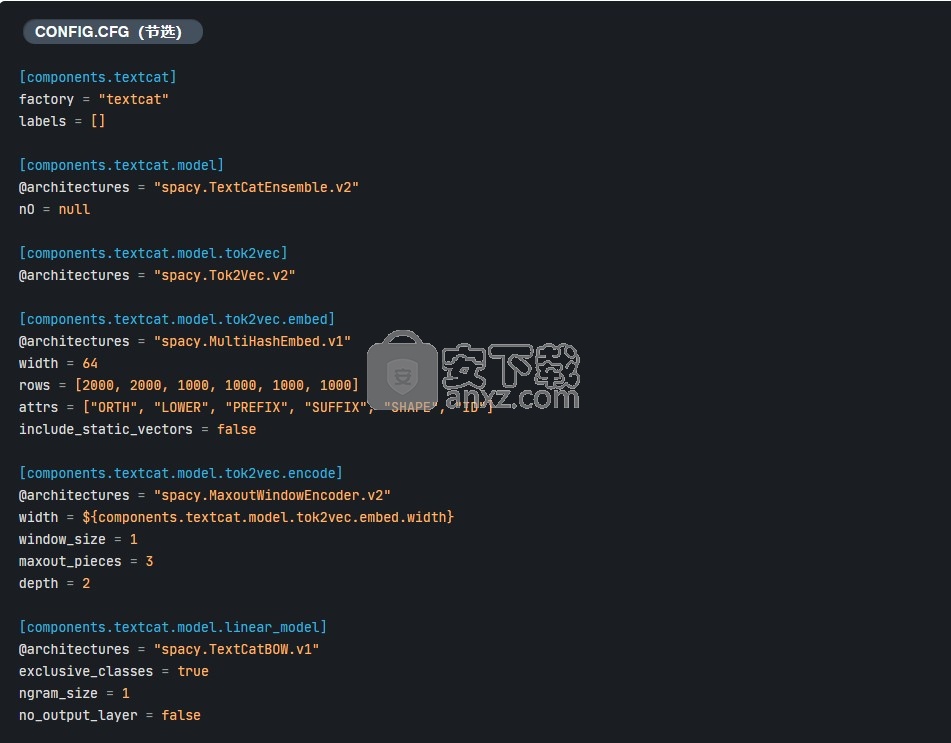
spaCy具有两个附加的内置textcat体系结构,您可以通过交换textcat模型的定义来轻松使用它们。例如,使用简单快速的词袋模型 TextCatBOW,您可以将配置更改为:
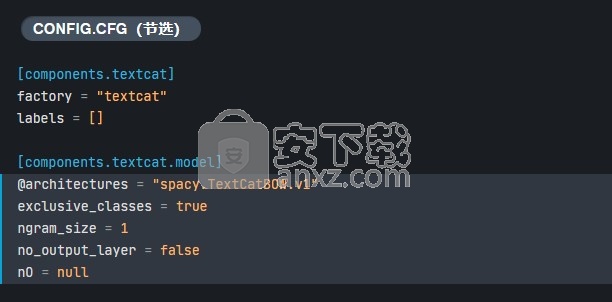
定义子层
模型体系结构功能通常接受子层作为参数,因此您可以尝试将另一个层替换为网络。根据架构功能的结构,您也许可以使用已定义的层,通过config系统完全定义网络结构。
在用于NLP的大多数神经网络模型中,网络最重要的部分就是我们所说的 嵌入和编码步骤。这些步骤共同计算出令牌的密集的,上下文相关的表示形式,它们的组合形成了典型的 Tok2Vec 层:
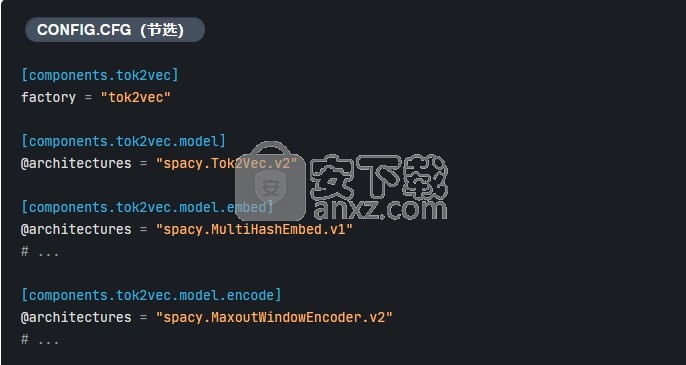
通过专门定义这些子层,可以很容易地将一个子层换成另一个子层,例如,将第一个子层更改为嵌入了 嵌入的角色 建筑学:
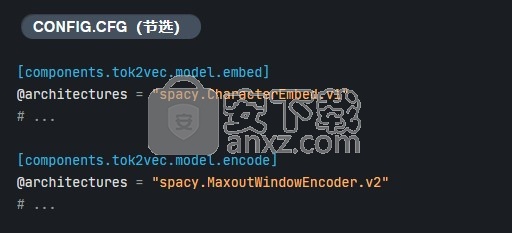
spaCy的大多数默认体系结构都将tok2vec层作为较大的特定于任务的神经网络中的子层。这使得在变压器,CNN,BiLSTM或其他特征提取方法之间轻松切换。所述 变压器的文档 部分显示换出一个模型的标准的一个例子tok2vec用的变压器层。而且,如果您想定义自己的解决方案,您只需注册一个架构功能,就可以在任何spaCy组件中进行尝试。Model[List[Doc], List[Floats2d]]
包装PyTorch,TensorFlow和其他框架
Thinc允许您 使用统一的API包装用其他机器学习框架(例如PyTorch,TensorFlow和MXNet)编写的模型Model。这使得使用在不同框架中实现的模型来为spaCy管道中的组件提供动力变得容易。例如,要将PyTorch模型包装为Thinc Model,可以使用Thinc的 PyTorchWrapper:

让我们使用PyTorch定义一个非常简单的神经网络,该网络由两个Linear具有ReLU激活和退出功能的隐藏层以及一个softmax激活的输出层组成:
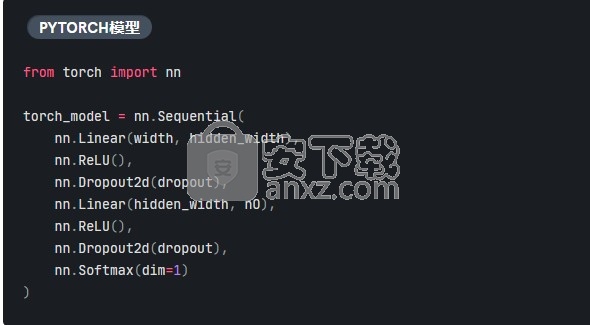
这样包装的结果Model可以直接用作自定义架构,也可以是较大模型的子组件。例如,我们可以使用Thinc的 chain组合器(Sequential在PyTorch中的工作原理) 将包装的模型与更大网络中的其他组件结合起来。这实际上意味着您可以轻松地包装来自不同框架的不同组件,然后将它们与Thinc“粘合”在一起:
在上面的示例中,我们将自定义PyTorch模型与spaCy定义的字符嵌入层结合在一起。 嵌入的角色返回Model以a作为输入的a,并输出a 。为了确保包装的PyTorch模型接收到有效的输入,我们使用Thinc的 帮助器。List[Doc]List[Floats2d]with_array
您还可以实现一个模型,该模型仅将PyTorch用于变压器层,并使用“本地” Thinc层进行灵活的输入和输出转换,并添加特定于任务的“头”,因为对于这些部分,效率不是一个考虑因素。网络。
更新日志
v3.0.4:修复了tok2vec的预培训,禁用了源功能的组件,更好的UX和错误修复
新功能和改进
允许在配置中采购禁用的组件。
支持Doc.spans在Example.from_dict。
在快速入门小部件和中改进变压器的建议init config。
改善保加利亚语的语言数据。
错误处理和UX的各种改进。
Bug修复
修复问题#6952,#7285和 #7289:使tok2vec预训练和pretrain命令再次按预期工作。
修复问题#7062:仅在有相应的跨度时才为NEL评估命名实体。
修复问题#7065:正确处理中的句子边界Span.sent。
修复问题#7071:修复conll转换器选项。
修复问题#7100:重新添加n_sents到实体链接器并修复配置处理和I / O。
修复问题#7122:修复evaluateCLI中的显示输出。
修复问题#7127:修复的初始化UkrainianLemmatizer。
修复问题#7176:重构Sentencizer以使用PipeAPI。
修复问题#7182:允许SpanGroup从导入spacy.tokens。
修复问题#7204:调整Cython编译以用于具有自定义包含路径的设置。
修复问题#7222:针对bg和的快速入门建议中的YAML格式正确bn。
修复问题#7225:修复中的spansweakref Doc.copy。
修复问题#7237:修复is_cython_func了其他导入的代码。
修复问题#7250:修复相同分数的耐心。
修复问题#7329:使自动spacy.lower_case.v1调节器按预期方式工作。
修复问题#7352:按EntityRuler.labels字母顺序排序。
人气软件
-

redis desktop manager2020.1中文 32.52 MB
/简体中文 -

s7 200 smart编程软件 187 MB
/简体中文 -

GX Works 2(三菱PLC编程软件) 487 MB
/简体中文 -

CIMCO Edit V8中文 248 MB
/简体中文 -

JetBrains DataGrip 353 MB
/英文 -

Dev C++下载 (TDM-GCC) 83.52 MB
/简体中文 -

TouchWin编辑工具(信捷触摸屏编程软件) 55.69 MB
/简体中文 -
信捷PLC编程工具软件 14.4 MB
/简体中文 -

TLauncher(Minecraft游戏启动器) 16.95 MB
/英文 -

Ardublock中文版(Arduino图形化编程软件) 2.65 MB
/简体中文
 Embarcadero RAD Studio(多功能应用程序开发工具) 12
Embarcadero RAD Studio(多功能应用程序开发工具) 12  猿编程客户端 4.16.0
猿编程客户端 4.16.0  VSCodium(VScode二进制版本) v1.57.1
VSCodium(VScode二进制版本) v1.57.1  aardio(桌面软件快速开发) v35.69.2
aardio(桌面软件快速开发) v35.69.2  一鹤快手(AAuto Studio) v35.69.2
一鹤快手(AAuto Studio) v35.69.2  ILSpy(.Net反编译) v8.0.0.7339 绿色
ILSpy(.Net反编译) v8.0.0.7339 绿色  文本编辑器 Notepad++ v8.1.3 官方中文版
文本编辑器 Notepad++ v8.1.3 官方中文版 






