

NVIDIA CUDA Toolkit(高性能GPU加速应用设计工具)
v11.1.1 免费版- 软件大小:310.25 MB
- 更新日期:2020-12-11 15:46
- 软件语言:英文
- 软件类别:编程工具
- 软件授权:免费版
- 软件官网:待审核
- 适用平台:WinXP, Win7, Win8, Win10, WinAll
- 软件厂商:

软件介绍 人气软件 下载地址
NVIDIA CUDA Toolkit是一款用于创建高性能GPU加速应用程序的开发环境,借助CUDA Toolkit,用户可以在GPU加速的嵌入式系统,台式机工作站,企业数据中心,基于云的平台和HPC超级计算机上开发,优化和部署应用程序;该工具包包括GPU加速库,调试和优化工具,C / C ++编译器以及用于部署应用程序的运行时库;GPU加速的CUDA库可实现跨多个域的嵌入式加速,例如线性代数,图像和视频处理,深度学习和图形分析;为了开发自定义算法,用户可以将可用的集成与常用语言和数字包以及发布良好的开发API结合使用;您的CUDA应用程序可以部署在本地和云中GPU实例上可用的所有NVIDIAGPU系列中,利用内置的功能跨多GPU配置分布计算,科学家和研究人员可以开发从单个GPU工作站扩展到具有数千个GPU的云安装的应用程序!
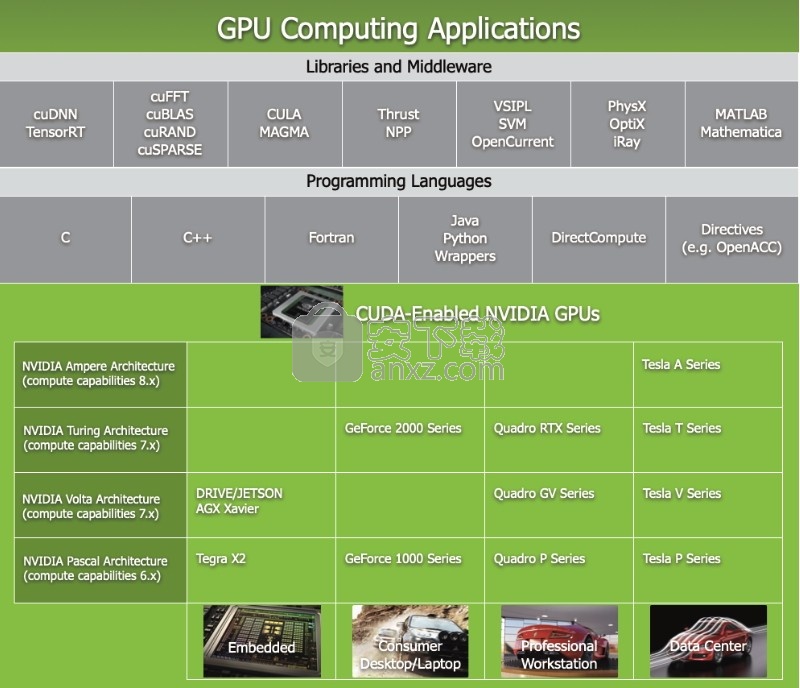
软件功能
GPU时间戳:开始时间戳
方法:GPU方法名称。这是内存副本的memcpy或GPU内核的名称。
内存副本的后缀描述了内存传输的类型,例如memcpyDToHasync表示从设备内存到主机内存的异步传输
GPU时间:这是该方法在GPU上的执行时间
CPU时间:这是启动该方法的GPU时间和CPU开销的总和。
在驱动程序生成的数据级别,CPU时间仅是启动非阻塞方法的CPU开销。
对于阻塞方法,它是GPU时间和CPU开销的总和。
默认情况下,所有内核启动都是非阻塞的。
但是,如果启用了任何探查器计数器,内核启动将被阻止。
不同流中的异步内存复制请求是非阻塞的
流ID:流的标识号
仅适用于内核方法的列
占用率:占用率是每个多处理器的活动扭曲数与最大活动扭曲数之比。
探查器计数器:请参阅探查器计数器部分以获取支持的计数器列表
网格大小:沿X,Y和Z维度的网格中的块数在单列中显示为[num_blocks_X num_blocks_Y num_blocks_Z]
块大小:沿X,Y和Z维度的块中的线程数在单列中显示为[num_threads_X num_threads_Y num_threads_Z]
dyn smem每块:每块动态共享内存大小(以字节为单位)
每块sta smem:每块的静态共享内存大小(以字节为单位)
每个线程的reg:每个线程的寄存器数
仅用于记忆复制方法的列
mem传输大小:内存传输大小(以字节为单位)
主机内存传输类型:指定内存传输是使用“可分页”还是“页面锁定”内存
软件特色
具有图形和命令行工具的IDE,用于调试,识别GPU和CPU上的性能瓶颈以及提供上下文相关的优化指导。
使用已知的编程语言开发应用程序,包括C,C ++,Fortran和Python。
首先,浏览在线入门资源,优化指南,说明性示例,并与快速发展的开发者社区进行协作。
NVIDIA® CUDA® 工具包提供了开发环境,可供创建经 GPU 加速的高性能应用。
借助 CUDA 工具包,您可以在经 GPU 加速的嵌入式系统、台式工作站、企业数据中心
基于云的平台和 HPC 超级计算机中开发、优化和部署应用。
此工具包中包含多个 GPU 加速库、多种调试和优化工具、一个 C/C++ 编译器
以及一个用于在主要架构(包括 x86、Arm 和 POWER)上构建和部署应用的运行时库。
借助多 GPU 配置中用于分布式计算的多项内置功能
科学家和研究人员能够开发出可从单个 GPU 工作站扩展到配置数千个 GPU 的云端设施的应用。
使用说明
编译器
CUDA-C和CUDA-C ++编译器, nvcc,位于 箱/目录。它基于NVVM优化器构建,而NVVM优化器本身则基于LLVM编译器基础结构构建。想要直接定位NVVM的开发人员可以使用Compiler SDK(可在nvvm / 目录。
请注意,以下文件是编译器内部的文件,如有更改,恕不另行通知。
中的任何文件 包含/ CRT 和 箱/盒
包括/ common_functions.h, 包括/device_double_functions.h, 包括/device_functions.h, 包括/ host_config.h, 包括/ host_defines.h和 包括/ math_functions.h
nvvm / bin / cicc
bin / cudafe ++, bin / bin2c和 bin / fatbinary
工具类
以下开发工具可在 箱/ 目录(除了作为Microsoft Visual Studio插件安装的Nsight Visual Studio Edition(VSE)之外,Nsight Compute和Nsight系统在单独的目录中可用)。
IDE: 视力 (Linux,Mac),Nsight VSE(Windows)
调试器: cuda-memcheck, cuda-gdb (Linux),Nsight VSE(Windows)
探查器:Nsight系统,Nsight计算, nvprof, nvvp, 新生儿监护病房,Nsight VSE(Windows)
实用程序: cuobjdump, 网络传播
图书馆
以下列出的科学和实用程序库可在 lib64 / 目录(Windows上的DLL位于 箱/),它们的界面在 包括/ 目录。
幼兽 (CUDA的高性能原语)
库布拉斯 (BLAS)
cublas_device (BLAS内核接口)
占用率 (内核占用率计算[头文件实现])
库达德维特 (CUDA设备运行时)
库达特 (CUDA运行时)
袖口 (快速傅立叶变换[FFT])
铜杯 (CUDA分析工具界面)
and (随机数生成)
库斯科尔 (密集稀疏直接线性求解器和本征求解器)
cusparse (稀疏矩阵)
libcu ++ (CUDA标准C ++库)
nvJPEG (JPEG编码/解码)
pp (NVIDIA Performance Primitives [图像和信号处理])
nvblas (“引入式” BLAS)
nvcuvid (CUDA视频解码器[Windows,Linux])
nvml (NVIDIA管理库)
虚拟电视台 (CUDA运行时编译)
nvtx (NVIDIA工具扩展)
推力 (并行算法库[头文件的实现])
CUDA样本
可以通过以下示例获取代码示例,这些示例说明了如何使用各种CUDA和库API。 样品/ Linux和Mac上的目录,并安装到 C:\ ProgramData \ NVIDIA Corporation \ CUDA示例在Windows上。在Linux和Mac上,样品/目录是只读的,如果要修改样本,必须将样本复制到另一个位置。
这些发行说明的最新版本可以在在线找到。另外,版本.txt 工具箱根目录中的文件将包含已安装工具箱的版本和内部版本号。
可以在以下位置以PDF格式找到文档: doc / pdf / 目录,或以HTML格式在 doc / html / index.html
通用CUDA
CUDA 11.1 Update 1是次要更新,与CUDA 11.1二进制兼容。此版本适用于R450 NVIDIA驱动程序的所有版本。
nvJPEG
为非标准JPEG图像添加了错误处理功能。
立方玻璃
cuBLASLt日志记录正式稳定,不再进行实验。cuBLASLt日志记录API仍处于试验阶段,将来的发行版中可能会更改。
cuSPARSE
cusparseSparseToDense
CSR,CSC或COO转换为密集表示
支持行主和列主布局
支持所有数据类型
支持32位和64位索引
提供比3倍更高的性能 cusparseXcsc2dense, cusparseXcsr2dense
cusparseDenseToSparse
代表CSR,CSC或COO
支持行主和列主布局
支持所有数据类型
支持32位和64位索引
提供比3倍更高的性能 cusparseXcsc2dense, cusparseXcsr2dense
已知的问题
此工具包版本包含安全修复程序。有关此工具包版本中提供的安全修复程序的更多信息,请参考安全公告。
cuSOLVER
cusolverDnIRSXgels 可能会回来 CUSOLVER_STATUS_INTERNAL_ERROR。当由于工作空间不足而导致非法内存访问的精度为“ z”时。
的 cusolverDnIRSXgels_bufferSize()不报告工作区的正确大小。要变通解决此问题,用户必须添加更多的工作空间,而不是报告的数量。cusolverDnIRSXgels_bufferSize()。
例如,如果x是由返回的工作空间的大小 cusolverDnIRSXgels_bufferSize(),则用户必须分配 [x +分钟(m,n)* sizeof(cuDoubleComplex)) 个字节。
cuSPARSE
cusparseXdense2csr 提供某些矩阵大小的错误结果。
解决的问题
立方玻璃
cublasLt Matmul在具有以下功能的Volta架构GPU上失败 CUBLAS_STATUS_EXECUTION_FAILED当n维> 262,137且使用尾声偏斜特征时。此问题在11.0和11.1版本中存在,但在11.1 Update 1中已得到纠正。
cuSOLVER
cusolverDnDDgels 报告 IRS_NOT_SUPPORTED 当m> n时。此问题已在11.1 U1版本中修复,因此 cusolverDnDDgels 将支持m> n。
cusolverMgDeviceSelect会消耗超过1GB的设备内存。此问题已在11.1 U1版本中修复。每个设备在cusolverMG句柄中的隐藏内存分配约为30 MB。
弃用
cuSPARSE
旧版转换例程: cusparseXcsc2dense, cusparseXcsr2dense, cusparseXdense2csc, cusparseXdense2csr
2.3。通用CUDA
添加了对基于NVIDIA Ampere GPU架构的GA10x GPU GPU(计算能力8.6)的支持,包括GeForce RTX-30系列。
跨次要版本的CUDA增强的CUDA兼容性将使CUDA应用程序与特定CUDA主版本的所有版本兼容。
CUDA 11.1添加了一个新的PTX Compiler静态库,该库允许使用库提供的一组API来编译PTX程序。
在x86_64平台上增加了对Fedora 32和Debian 10.3 Buster的支持。
用于以下方面的统一编程模型:
异步复制、异步管道
异步屏障(cuda :: barrier)
添加了硬件加速的稀疏纹理支持。
增加了对只读映射的支持 cudaHostRegister。
CUDA Graphs增强功能:
改进了graphExec更新
外部依赖
扩展内存复制API
预先提交
引入了新的系统级接口,该接口使用基于/ dev的功能通过MIG进行cgroup样式隔离。
使用多GPU时,改进了MPS错误处理。
由Volta + MPS客户端生成的致命GPU异常将包含在受其影响的设备以及使用这些设备的其他客户端中。
在由同一MPS服务器管理的其他设备上运行的客户端可以继续正常运行。
用户现在可以通过nvidia-smi配置和查询GPU的每个上下文时间片持续时间。
配置时间片将需要管理员特权,并且允许的设置为默认,短,中和长。
该时间片仅适用于在应用配置后执行的CUDA应用程序。
改进了对不支持的配置的检测和报告。
cuFFT现在支持L2缓存,并为L2缓存超过4.5MB的GPU使用L2缓存。
在某些单GPU 3D C2C FFT情况下,性能可能会提高。
成功创建计划后,cuFFT现在对cufftHandle强制执行锁定。
随后使用相同的cufftHandle调用任何计划函数将失败。
在DGX-2上的多GPU cuFFT中增加了对超大尺寸(3k立方体)的支持。
对于某些大小(1k多维数据集),改进了多gpu cuFFT的性能。
当前版本的CUDA软件不推荐使用以下功能。
这些功能在当前版本中仍然可以使用,但是它们的文档可能已被删除
将来的版本中将不再正式支持这些功能。
我们建议开发人员对其软件中的这些功能采用替代解决方案。
通用CUDA
CUDA 11.1是在IBM POWER(ppc64le)平台上支持Ubuntu发行版的最新版本。
从下一个CUDA版本开始,IBM POWER仅支持Red Hat Enterprise Linux(RHEL)。
CUDA工具
不再支持VS2015。不推荐使用包括VS2012和VS2013在内的早期Visual Studio版本
并且在将来的CUDA版本中可能会放弃支持。CUDA库
版本更新
NVIDIA几年前首次推出的软件开发人员工具包经历了几次转型,其中最新的成果不到24小时就已揭晓。
在CUDA工具包,该公司决定将其命名创建,取得了功能支持和性能相当的飞跃。
从2012年4月发布的4.2版本开始,它一直跃升至5.0版。从4.0(2011年5月)到4.1(2012年1月)再到4.2的发展形成了鲜明的对比。
该软件开发工具包为C和C ++应用程序创建者提供了一些新的可能性。
首先,可以使用NVCC单独编译和链接所有设备功能。这允许创建封闭源设备功能库,甚至允许那些库启动用户定义的设备回调函数。
链接器支持在此版本中是BETA,但客户的反馈将使NVIDIA消除可能留下的任何错误。
CUDA Toolkit 5.0的第二个功能是新的命令行分析器nvproof。通过提供有关应用程序花费时间最多的位置的摘要信息,它可以使优化工作正确地集中在。
该版本的第三项资产是CUDA动态并行,它允许GPU运行的全局和设备功能使用“ <<<< >>>>>>语法启动内核,并直接调用CUDA运行时API例程。当然,此功能以前存在,但仅存在于主机功能中。
第四个也是最后一个新功能是用于Linux和Mac OS的Nsight Eclipse Edition,这是一个集成的开发环境用户界面,使程序员可以开发,调试和优化CUDA代码。
总而言之,CUDA Toolkit 5.0为新的和改进的程序打开了大门,这些程序能够利用图形处理单元的并行计算功能。
开发人员可以从下面的链接之一下载适当版本的软件。
人气软件
-

redis desktop manager2020.1中文 32.52 MB
/简体中文 -

s7 200 smart编程软件 187 MB
/简体中文 -

GX Works 2(三菱PLC编程软件) 487 MB
/简体中文 -

CIMCO Edit V8中文 248 MB
/简体中文 -

JetBrains DataGrip 353 MB
/英文 -

Dev C++下载 (TDM-GCC) 83.52 MB
/简体中文 -

TouchWin编辑工具(信捷触摸屏编程软件) 55.69 MB
/简体中文 -
信捷PLC编程工具软件 14.4 MB
/简体中文 -

TLauncher(Minecraft游戏启动器) 16.95 MB
/英文 -

Ardublock中文版(Arduino图形化编程软件) 2.65 MB
/简体中文
 Embarcadero RAD Studio(多功能应用程序开发工具) 12
Embarcadero RAD Studio(多功能应用程序开发工具) 12  猿编程客户端 4.16.0
猿编程客户端 4.16.0  VSCodium(VScode二进制版本) v1.57.1
VSCodium(VScode二进制版本) v1.57.1  aardio(桌面软件快速开发) v35.69.2
aardio(桌面软件快速开发) v35.69.2  一鹤快手(AAuto Studio) v35.69.2
一鹤快手(AAuto Studio) v35.69.2  ILSpy(.Net反编译) v8.0.0.7339 绿色
ILSpy(.Net反编译) v8.0.0.7339 绿色  文本编辑器 Notepad++ v8.1.3 官方中文版
文本编辑器 Notepad++ v8.1.3 官方中文版 






